Clear Sky Science · pl
Hybrydowy wybór cech z nowym modelem głębokiego uczenia do przewidywania ryzyka COVID-19
Dlaczego przewidywanie ryzyka COVID-19 nadal ma znaczenie
Nawet gdy świat uczy się żyć z COVID-19, wirus nie zniknął. Pojawiają się nowe warianty, szpitale nadal mogą być obciążone, a osoby wrażliwe wciąż są bardziej narażone na ciężki przebieg choroby lub zgon. Lekarze potrzebują więc szybkich i wiarygodnych sposobów oszacowania, jak prawdopodobne jest, że zakażony pacjent stanie się poważnie chory. Artykuł przedstawia nowy model komputerowy, który wykorzystuje dane szpitalne i zaawansowaną sztuczną inteligencję do dokładniejszego przewidywania ryzyka COVID-19, co może pomóc klinicystom w decyzji, kto wymaga uważniejszej obserwacji, wczesnego leczenia lub opieki intensywnej.
Od surowych kartotek pacjentów do użytecznych sygnałów
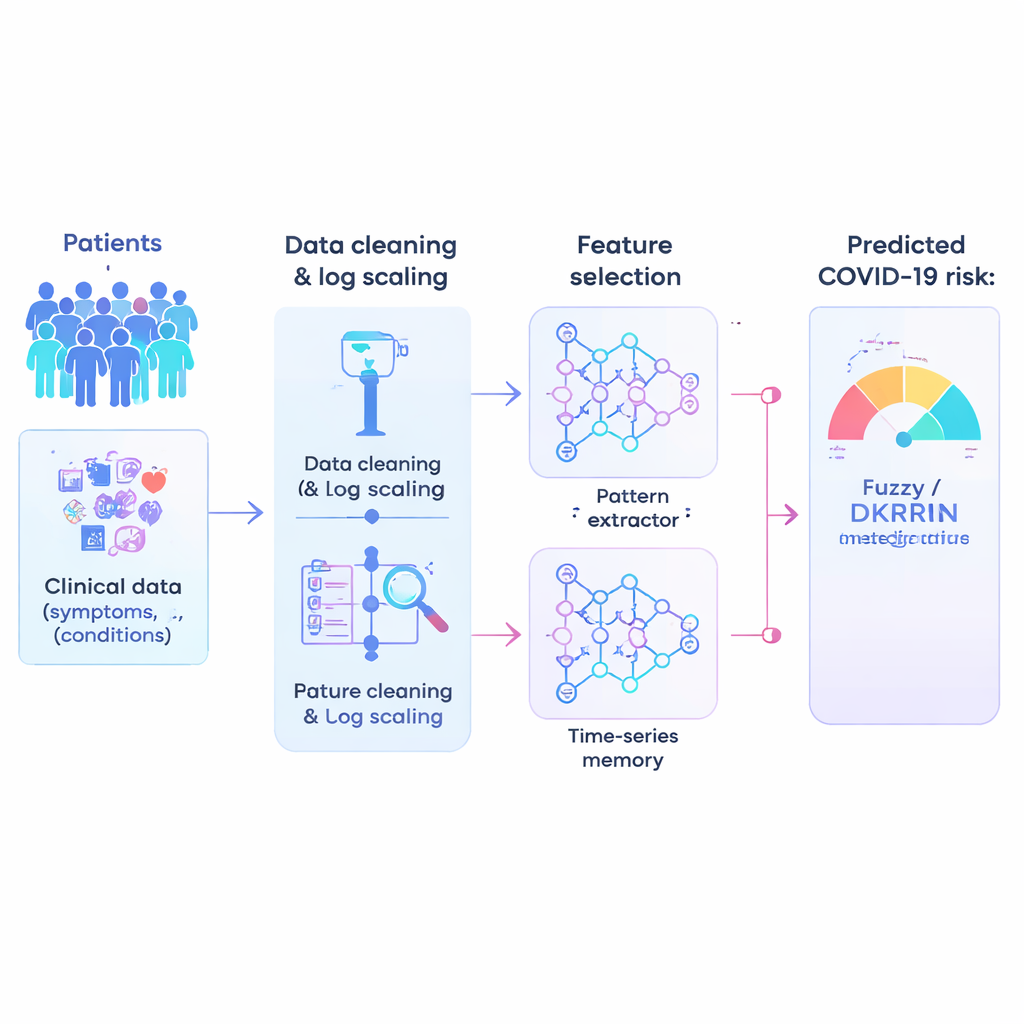
Badanie zaczyna się od bardzo dużego zbioru danych klinicznych: ponad miliona anonimowych pacjentów, z których każdy opisany jest przez 21 prostych, w większości odpowiedzi tak/nie, cech takich jak grupa wiekowa, choroby współistniejące i inne czynniki ryzyka. Dane szpitalne z rzeczywistej praktyki są nieuporządkowane, dlatego pierwszym krokiem jest ich „oczyszczenie”. Autorzy stosują matematyczną sztuczkę nazwaną skalowaniem logarytmicznym, która kompresuje skrajne wartości i rozciąga skupiska bardzo małych wartości. Ta transformacja stabilizuje dane i ułatwia pracę algorytmom, zmniejszając ryzyko, że nietypowe liczby lub rzadkie wskaźniki wprowadzą model w błąd.
Wybór najbardziej wymownych wskaźników
Niek każda zarejestrowana zmienna jest równie pomocna w przewidywaniu, a zbyt wiele słabych sygnałów może wręcz zmylić system sztucznej inteligencji. Dlatego badacze przeprowadzają wybór cech — proces, który odfiltrowuje mniej przydatne informacje i zachowuje najbardziej informatywne czynniki. Ich hybrydowe podejście łączy dwa pomysły: jedna miara ocenia, jak dobrze cecha rozdziela pacjentów wysokiego i niskiego ryzyka, a druga sprawdza, jak silnie cechy na siebie nachodzą. Poprzez zrównoważenie tych dwóch perspektyw na wspólnej skali, metoda faworyzuje cechy zarówno silne, jak i nienadmiernie zduplikowane. To przycinanie przyspiesza trening, redukuje przeuczenie i koncentruje model na najbardziej klinicznie istotnych wzorcach.
Łączenie rozpoznawania wzorców z rozumowaniem rozmytym
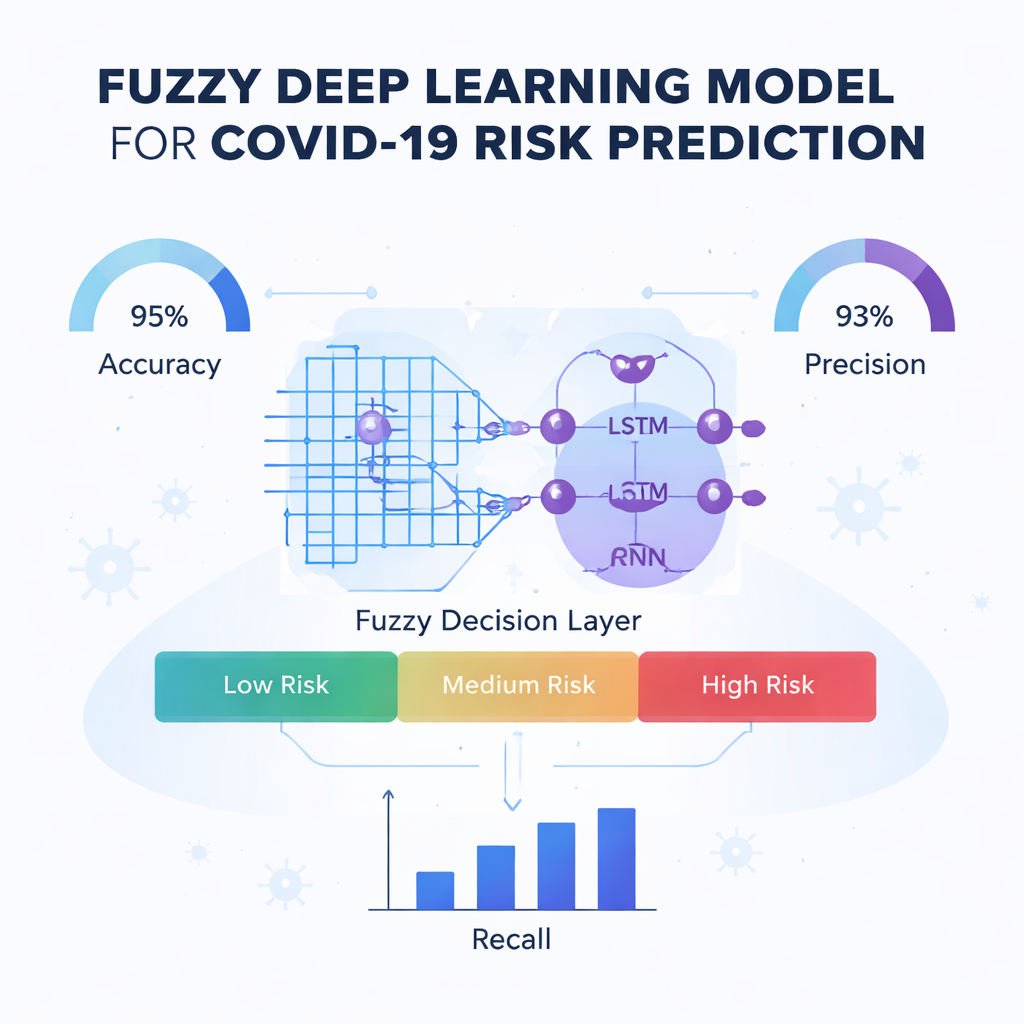
Rdzeniem artykułu jest nowy mechanizm predykcyjny nazwany Fuzzy-Deep Kronecker Recurrent Neural Network, w skrócie Fuzzy-DKRNN. Łączy on kilka uzupełniających się technik. Jednym z komponentów jest Deep Kronecker Network, zaprojektowana do odkrywania zwartch, zorganizowanych wzorców ukrytych w danych klinicznych. Innym komponentem jest głęboka sieć rekurencyjna, odpowiednia do przechwytywania zależności i trendów, na przykład gdy kombinacja czynników w czasie wpływa na ryzyko. Na to wszystko autorzy nakładają system logiki rozmytej. Zamiast podejmować jedynie ostre decyzje tak/nie, reguły rozmyte wyrażają stwierdzenia typu „jeśli kilka wskaźników ryzyka jest umiarkowanie wysokich, pacjent prawdopodobnie jest wysokiego ryzyka”. Każda reguła ma przypisany stopień pewności, co pozwala modelowi radzić sobie z niepewnością i szarościami typowymi w medycynie.
Jak dobrze model wypada?
Autorzy rygorystycznie testują swój model Fuzzy-DKRNN w porównaniu z kilkoma nowoczesnymi alternatywami, w tym systemami opartymi na zdjęciach rentgenowskich klatki piersiowej, tradycyjnym uczeniu maszynowym i innymi podejściami głębokiego uczenia. Korzystając ze standardowych miar, takich jak dokładność, precyzja, recall i F1-score, ich metoda konsekwentnie wypada lepiej. W najlepszej konfiguracji model poprawnie klasyfikuje około 91% przypadków ogółem, z wysoką zdolnością zarówno do wykrywania pacjentów, którzy staną się ciężko chorzy, jak i do unikania niepotrzebnych alarmów u tych, którzy tego nie doświadczą. Te korzyści utrzymują się przy zmianach ilości danych treningowych i ustawień walidacji wewnętrznej, co sugeruje, że podejście jest solidne, a nie dopasowane precyzyjnie do jednego scenariusza.
Co to oznacza dla pacjentów i szpitali
Mówiąc prosto, praca pokazuje, że połączenie starannego oczyszczania danych, inteligentnego wyboru kluczowych czynników ryzyka oraz hybrydy głębokiego uczenia z logiką rozmytą może dać bardziej wiarygodne prognozy ryzyka COVID-19 na podstawie rutynowych informacji klinicznych. Takie narzędzie nie zastąpi lekarzy, ale może służyć jako asystent wczesnego ostrzegania — sygnalizując pacjentów wymagających bliższego nadzoru, wspierając dystrybucję ograniczonych zasobów, takich jak łóżka intensywnej terapii, i ostatecznie pomagając zmniejszyć liczbę możliwych do uniknięcia zgonów. Strategię tę można także dostosować do innych chorób, w których wczesne wykrywanie ryzyka na podstawie złożonych danych klinicznych jest kluczowe.
Cytowanie: P, G.S., Kathiravan, M., Shanthi, S. et al. Hybrid feature selection with novel deep learning model for COVID-19 risk prediction. Sci Rep 16, 4106 (2026). https://doi.org/10.1038/s41598-026-35013-7
Słowa kluczowe: prognozowanie ryzyka COVID-19, głębokie uczenie, logika rozmyta, wspomaganie decyzji klinicznych, medyczne modele AI