Clear Sky Science · pl
Dokładna segmentacja obiektów pod wodą w czasie rzeczywistym z ulepszonym dwudziedzinowym YOLOv11‑UOS oraz fizycznie ukierunkowaną adaptacyjną poprawą i wzmacnianiem uwagi
Płytsze zanurzenie z ostrzejszymi cyfrowymi oczami
Nasze oceany są coraz częściej badane nie tylko przez nurków i łodzie podwodne, lecz także przez inteligentne kamery zamontowane na robotach podwodnych. Kamery te pomagają odnajdywać wraki, kontrolować rurociągi przybrzeżne oraz monitorować rafy koralowe i populacje ryb. Jednak zdjęcia pod wodą często są mętne, niebiesko‑zielone i pełne wizualnego zgiełku, co utrudnia rozpoznawanie obiektów nawet ludziom — nie mówiąc już o komputerach. W artykule przedstawiono nowy system widzenia komputerowego, który oczyszcza obrazy podwodne, a następnie szybko wykrywa i obrysowuje obiekty na tyle sprawnie, by wspierać misje robotyczne w czasie rzeczywistym.
Dlaczego widzenie pod wodą jest tak trudne
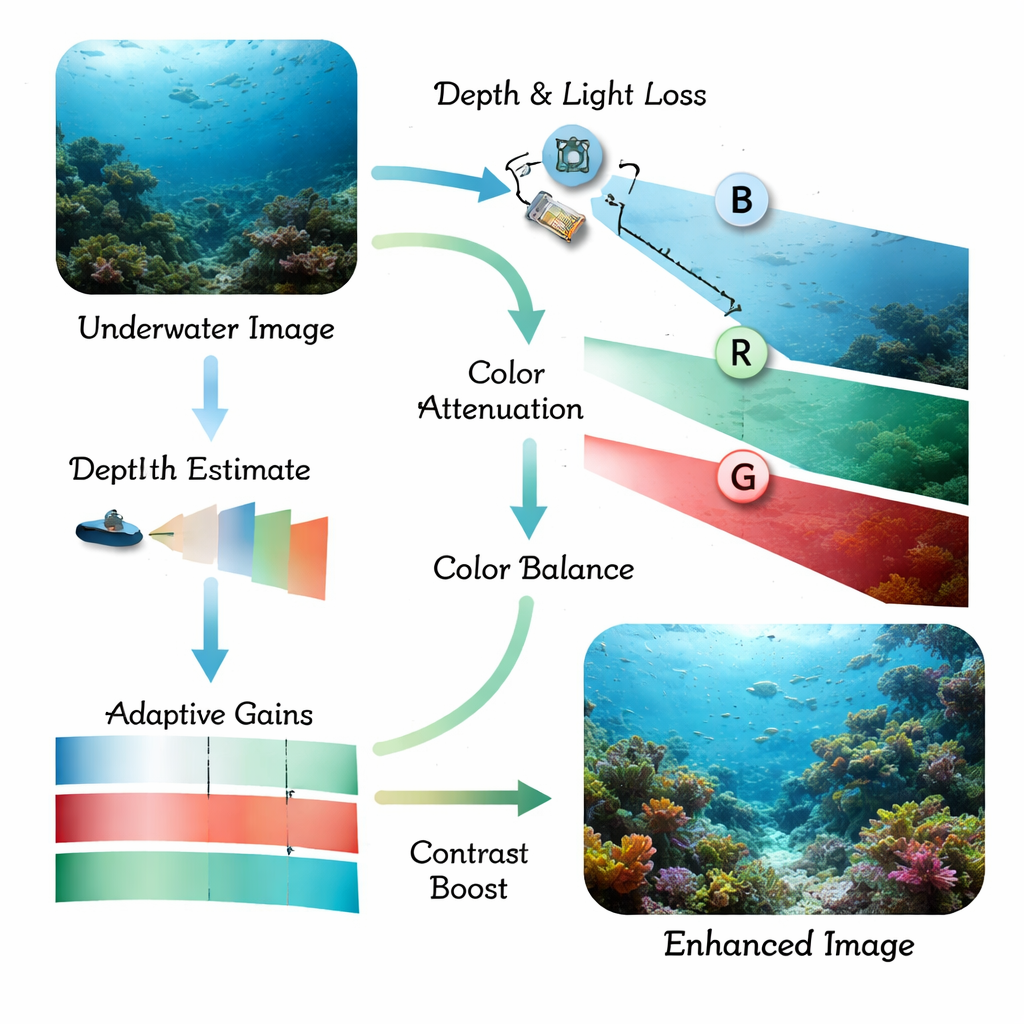
Światło zachowuje się w wodzie inaczej niż w powietrzu. W miarę jak promienie słoneczne przenikają w dół, czerwone tony zanikają jako pierwsze, potem zielone, pozostawiając niebieskawy odcień i matowe, o niskim kontraście sceny. Maleńkie cząstki zawieszone w wodzie rozpraszają światło, tworząc mgłę, która rozmywa krawędzie i ukrywa drobne szczegóły. Tradycyjne programy wykrywające obiekty, a nawet nowoczesne modele głębokiego uczenia, mają problemy z tak zniekształconymi obrazami: ryby zlewają się z koralowcami, obiekty będące dziełem człowieka giną w tle, a sceny przy słabym oświetleniu stają się niemal nieczytelne. Wcześniejsze badania zwykle zajmowały się albo poprawą obrazów, albo wykrywaniem obiektów, co często powodowało, że końcowy system był zbyt wolny, zbyt kruchy lub nadal ślepy w szczególnie mętnej wodzie.
Strategia dwustopniowa: najpierw oczyszczać, potem skupiać się
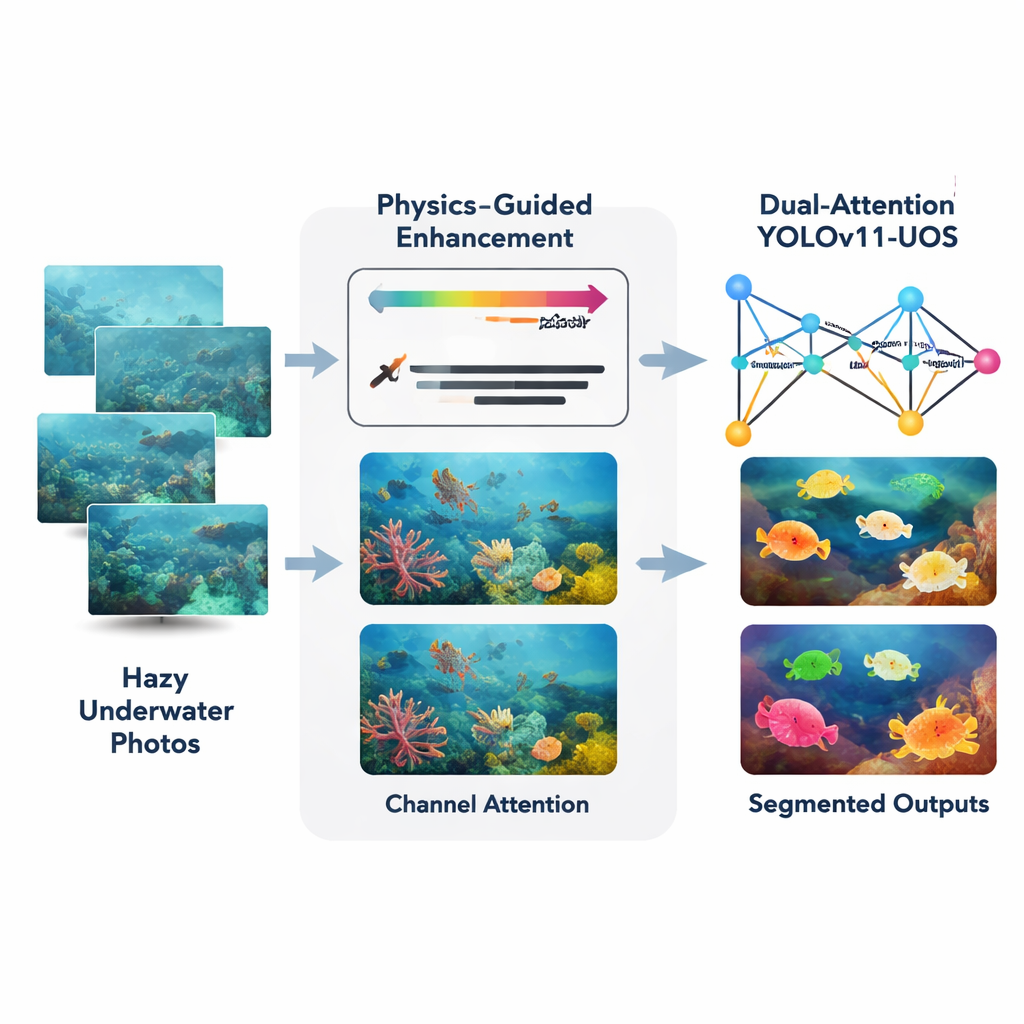
Autorzy proponują podejście łączone oparte na niedawno opracowanym detektorze działającym w czasie rzeczywistym, YOLOv11, dostosowanym tutaj do scen podwodnych i segmentacji instancji (rysowania precyzyjnego obrysu każdego obiektu). Najpierw moduł frontowy zwany Adaptive Physics‑Guided Enhancement przetwarza surowe zdjęcia podwodne i koryguje je, wykorzystując uproszczony model fizyczny pochłaniania i rozpraszania światła w wodzie. Szacuje odległość poszczególnych części sceny od kamery, a następnie kompensuje silniejsze tłumienie czerwieni w porównaniu do zieleni i niebieskiego. Przywraca to bardziej naturalne kolory i zwiększa lokalny kontrast, podczas gdy starannie dobrany etap oparty na histogramie wyostrza krawędzie bez nadmiernego wzmacniania szumu, nawet w ciemnych lub mętnych obszarach.
Nauka sieci, gdzie patrzeć
Po oczyszczeniu obraz trafia do ulepszonego trzonu YOLOv11, wyposażonego w mechanizmy uwagi. Dodane moduły działają jak reflektor i filtr kolorów. Uwaga przestrzenna kieruje sieć, by zwracała większą uwagę na istotne regiony — na przykład obrys ryby lub krawędź zatopionego artefaktu — i ignorowała rozpraszające tło, takie jak piasek czy kołyszące się rośliny. Uwaga kanałowa reguluje, jak silnie system uwzględnia różne wzorce kolorów i faktur, tak by użyteczne wskazówki wizualne były podkreślone, a nieistotne zredukowane. Razem te dwa etapy uwagi pomagają sieci zbudować ostrzejsze wewnętrzne reprezentacje, zanim zdecyduje, gdzie znajdują się obiekty i czym są.
Testy na rzeczywistych oceanach i w trudnych warunkach
Aby sprawdzić działanie systemu w praktyce, badacze trenowali i testowali go na kilku publicznych zbiorach obrazów podwodnych oraz na nowym, niestandardowym zestawie ponad 7000 starannie oznakowanych zdjęć z wód przybrzeżnych o różnej głębokości i zmętnieniu. Mierzyli standardowe miary wykrywania i segmentacji oraz porównywali swoją metodę z szeroko stosowanymi modelami, takimi jak U‑Net, DeepLab, segmentery oparte na transformatorach oraz bazowy system YOLOv11 bez nowych modułów. Połączone rozwiązanie łączące ulepszenie obrazu i mechanizmy uwagi poprawiło średnią dokładność wykrywania o około 6,5 punktu procentowego względem bazowego YOLOv11, przy wyraźnie czystszych obrysach obiektów oraz mniejszej liczbie przeoczonych lub błędnie wykrytych elementów. Co ważne, system nadal działa w tempie około 38 kl./s na nowoczesnym procesorze graficznym, wystarczająco szybko do niemal rzeczywistego zastosowania na platformach robotycznych.
Co to oznacza dla robotów oceanicznych i badań
Mówiąc prościej, badanie pokazuje, że inteligentne wstępne przetwarzanie i ukierunkowana uwaga pozwalają komputerom „widzieć” znacznie lepiej pod wodą. Najpierw niwelując część fizycznych efektów, które psują zdjęcia podwodne, a następnie kierując sieć wykrywającą, by skupiała się na najbardziej informacyjnych regionach i kolorach, metoda dostarcza ostrzejsze, bardziej wiarygodne obrysy ryb, koralowców i obiektów stworzonych przez człowieka. Może to pomóc autonomicznym pojazdom podwodnym bezpiecznie nawigować, monitorować wrażliwe ekosystemy morskie i kontrolować krytyczną infrastrukturę podwodną bez nadzoru człowieka. Wyzwania pozostają w przypadku ekstremalnie mętnych wód lub bardzo głęboko położonych scen pozbawionych czerwonego światła, ale zaproponowane ramy stanowią praktyczny krok w stronę odpornej, działającej w czasie rzeczywistym wizji podwodnej, która może wspierać przyszłe mapowanie 3D i eksplorację wielozmysłową oceanu.
Cytowanie: Deluxni, N., Sudhakaran, P., Alroobaea, R. et al. An accurate realtime underwater object segmentation using improved dual-domain YOLOv11-UOS with physics guided adaptive enhancement and attention-boosting. Sci Rep 16, 4804 (2026). https://doi.org/10.1038/s41598-026-35001-x
Słowa kluczowe: wizja podwodna, robotyka morska, poprawa obrazu, segmentacja obiektów, widzenie komputerowe