Clear Sky Science · pl
Ulepszanie prognoz Au z danych cenzurowanych za pomocą bayesowskich modeli przestrzennych i Random Forest z fraktalnym oddzielaniem tła
Dlaczego drobne ślady złota mają znaczenie
Gdy geolodzy poszukują nowych złóż złota, często pracują na próbkach gleby zawierających jedynie kilka części na miliard tego metalu. Wartości tak ekstremalnie niskie leżą bardzo blisko granic wykrywalności aparatów laboratoryjnych, więc wiele pomiarów jest raportowanych po prostu jako „poniżej wykrywalności”. Jeśli takie bliskie granicy wartości są niewłaściwie traktowane, można przeoczyć obiecujące strefy mineralne lub błędnie odwzorować ich zasięg. W badaniu przedstawiono inteligentniejszy sposób odzyskiwania informacji z tych cenzurowanych pomiarów, co pomaga eksploratorom zobaczyć wyraźniejsze wzorce w podłożu przy ograniczonych i zaszumionych danych.
Ukryte sygnały w niedoskonałych pomiarach
Chemia gleby i skał jest kluczowym narzędziem w eksploracji, ponieważ niewielkie zmiany chemiczne mogą wskazywać na ukryte ciało rudy. Jednak urządzenia nie mierzą ilości w nieskończoność. W tym badaniu dla złota każda próbka poniżej kilku części na miliard została potraktowana jako cenzurowana: laboratorium mogło stwierdzić jedynie, że prawdziwa wartość znajduje się poniżej tej granicy. Powszechne szybkie naprawy polegają na zastępowaniu takich wyników stałą liczbą, np. połową granicy detekcji. Choć wygodne, postępowanie to wygładza naturalną zmienność, zamaza subtelne anomalie i zniekształca relacje złota z innymi pierwiastkami, jak miedź. Autorzy argumentują, że aby naprawdę odczytać chemiczne odciski Ziemi, trzeba zachować niepewność wiążącą się z niskimi wartościami, zamiast ją nadpisywać.
Z mapy geologicznej do czystszego tła
Badania koncentrują się na prospekcie miedź–złoto w północnej części rejonu Dalli w centralnym Iranie, gdzie pobrano 165 próbek gleby na gęstej siatce nad znanym systemem porfirowym. Złoto mierzono wraz z 29 innymi pierwiastkami, a 14 próbek znalazło się poniżej przyjętej granicy wykrywalności 5 części na miliard. Zamiast wprowadzać wszystkie dane bezpośrednio do modelu, zespół najpierw zastosował fraktalną metodę zależności koncentracja–liczba, by oddzielić wartości tła od silniejszych anomalii. Analizując, jak liczba próbek zmienia się wraz ze wzrostem stężenia złota na wykresie log–log, zidentyfikowali progi dzielące tło, słabe anomalie i silne anomalie. Do budowy modeli prognostycznych użyto wyłącznie populacji tła — włącznie z wartościami cenzurowanymi — co zmniejszyło ryzyko, że kilka próbek o wysokiej wartości zdominuje proces uczenia.
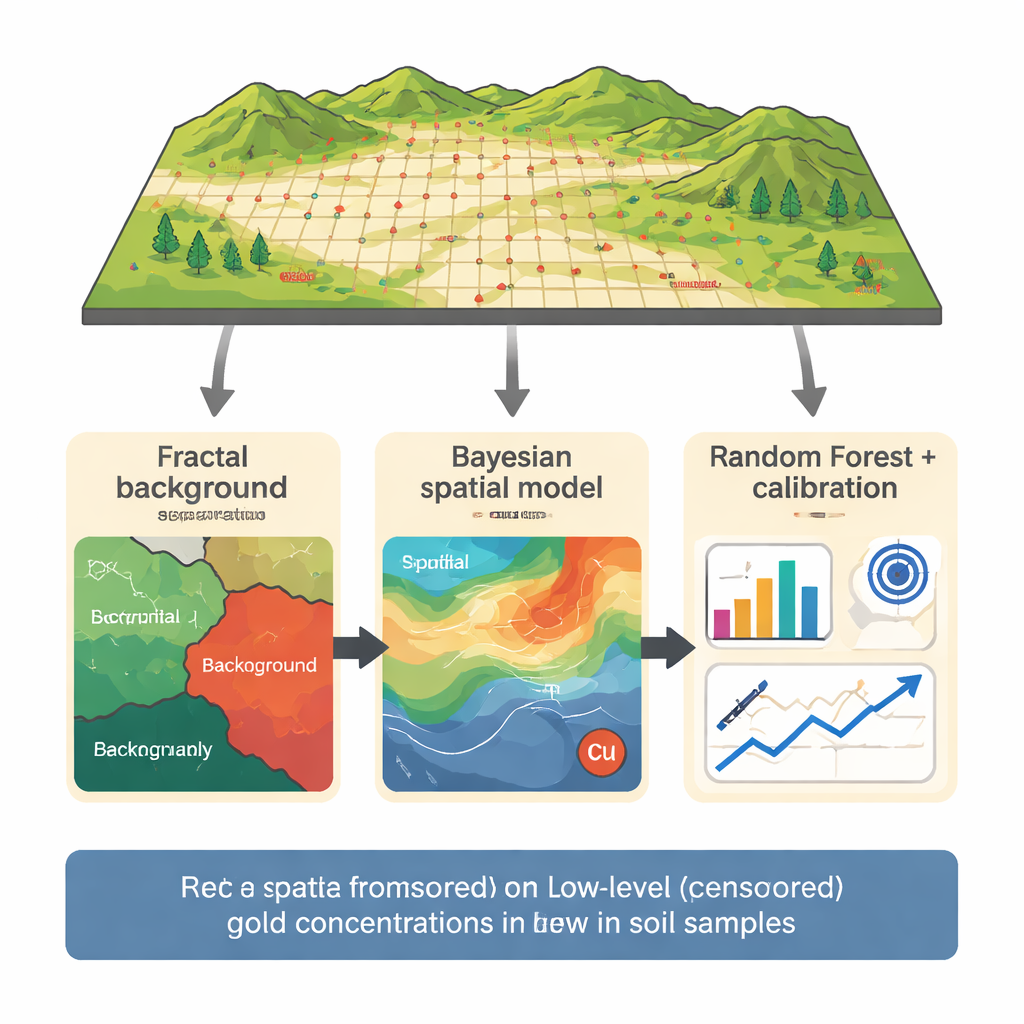
Mapa probabilistyczna wsparta miedzią
Aby oszacować rzeczywistą zawartość złota w próbkach cenzurowanych, autorzy zastosowali następnie bayesowski model pola losowego Gaussa (Gaussian Random Field), probabilistyczne podejście przestrzenne. Model traktuje stężenie złota jako gładko zmieniające się pole na mapie, zależne zarówno od lokalizacji, jak i od zawartości miedzi, która w tym systemie porfirowym jest silnie powiązana ze złotem. Zamiast przypisywać pojedynczą liczbę każdemu cenzurowanemu punktowi, model generuje pełną krzywą prawdopodobieństwa, respektując fakt, że prawdziwa wartość musi leżeć poniżej progu detekcji. Wynikiem jest zestaw najlepszych estymacji i zakresów niepewności dla 14 cenzurowanych próbek, spójnych z pobliskimi pomiarami i z obserwowanym powiązaniem złoto–miedź w skałach.
Uczenie maszynowe skoncentrowane tam, gdzie ma to znaczenie
Te probabilistyczne estymaty zostały następnie wykorzystane w modelu Random Forest — metodzie uczenia maszynowego łączącej wiele drzew decyzyjnych. Model uczy się wzorców na podstawie złota, miedzi, żelaza, niklu, tytanu i boru z populacji tła, z ostrożnym krzyżowym sprawdzaniem (cross-validation), tak aby każda próbka była testowana tylko na modelach, które jej wcześniej nie widziały. Początkowe prognozy wciąż miały tendencję do nieco zawyżonych wyników w pobliżu granicy detekcji — powszechny problem przy niewielkiej liczbie bardzo niskich wartości. Aby to skorygować, autorzy przeprowadzili ukierunkowaną kalibrację skoncentrowaną na przedziale 5–8 części na miliard, a następnie zastosowali prosty krok skalowania, by zapewnić, że skorygowane prognozy pozostaną w fizycznie sensownych granicach. Ten trzyetapowy łańcuch — separacja fraktalna, bayesowska estymacja przestrzenna i skalibrowany Random Forest — dał prognozy znacznie lepiej odpowiadające rzeczywistym niskim wartościom złota niż standardowe podejścia.
Lepsze niż stare skróty
W badaniu porównano nowe podejście z podstawowym Random Forest oraz z dwoma klasycznymi regułami podstawiania, które zastępują wyniki cenzurowane stałymi ułamkami granicy wykrywalności. W kilku miarach błędu skalibrowany i skalowany model hybrydowy okazał się najdokładniejszy i najmniej obciążony systematycznie, szczególnie dla próbek bliskich granicy detekcji, gdzie drobne błędy mają największe znaczenie. Zachował też realistyczną zmienność i rozsądne relacje między złotem a miedzią, podczas gdy zastępowanie wszystkich wartości cenzurowanych jedną stałą niszczyło tę strukturę. W niektórych wyższych cenzurowanych próbkach względny błąd nowej metody był setki razy mniejszy niż w przypadku tradycyjnych podstawień.
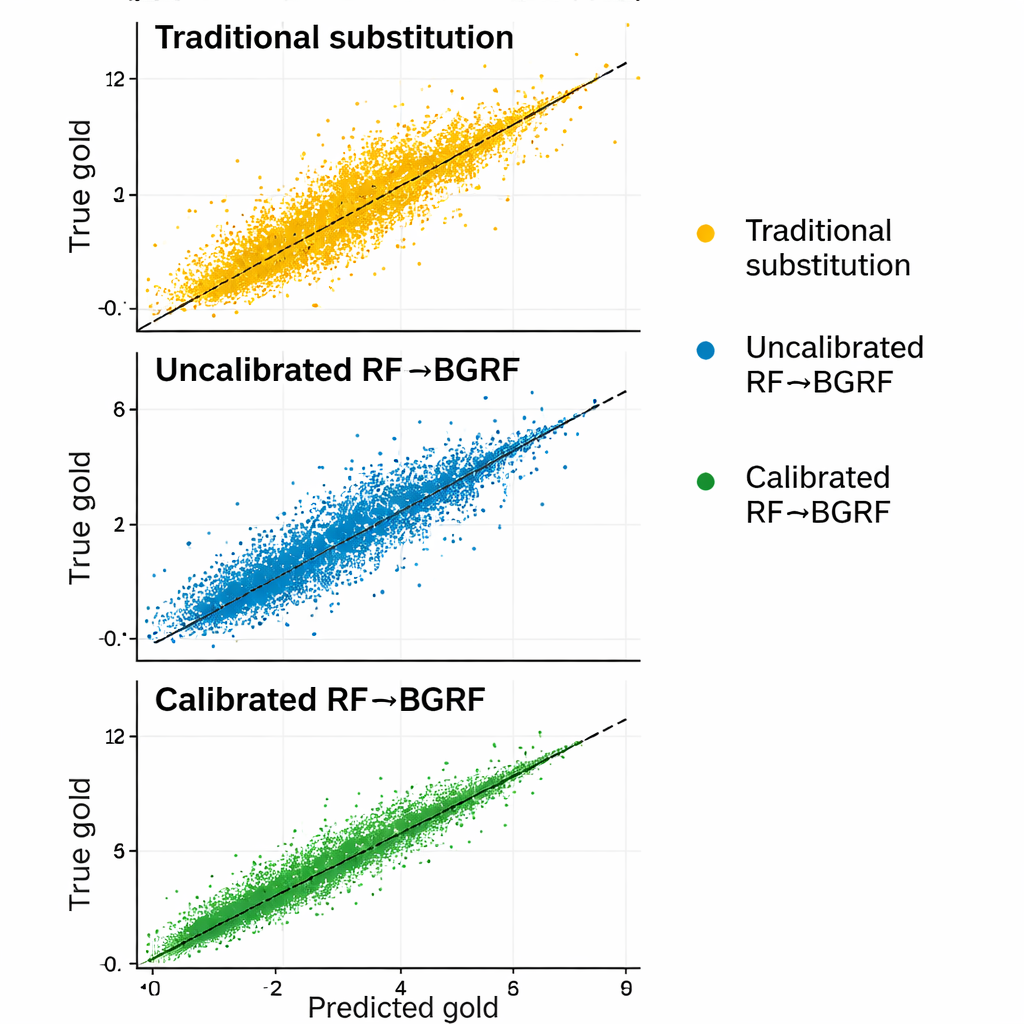
Czystsze obrazy chemiczne dla eksploracji
Dla osób nie będących specjalistami kluczowy wniosek jest taki, że sposób traktowania wartości „poniżej wykrywalności” w danych geochemicznych może przesądzić o powodzeniu poszukiwań nowych złóż. Zamiast usuwać niepewność za pomocą grubych przybliżeń, praca ta pokazuje, że połączenie probabilistycznego modelowania przestrzennego, uczenia maszynowego i prostej kalibracji potrafi odzyskać wiele ukrytej informacji w niskopoziomowych pomiarach. Efektem są czystsze mapy subtelnych wzorców złota, bardziej wiarygodne wykrywanie anomalii i ostatecznie większa szansa na odnalezienie ciał rud przy mniejszej liczbie odwiertów i bardziej rzetelnych danych.
Cytowanie: Mahdiyanfar, H. Advancing censored geochemical Au prediction through Bayesian spatial models and Random Forest with fractal-based background separation. Sci Rep 16, 4763 (2026). https://doi.org/10.1038/s41598-026-34999-4
Słowa kluczowe: poszukiwania geochemiczne, dane cenzurowane, anomalia złota, modelowanie przestrzenne bayesowskie, uczenie maszynowe w geologii