Clear Sky Science · pl
Obliczanie miary podobieństwa zdań przy użyciu hybrydowego uczenia głębokiego ze szczególnym uwzględnieniem zdań z negacją
Dlaczego sens słów ma znaczenie dla sprawiedliwego oceniania
Kiedy studenci odpowiadają własnymi słowami, systemy komputerowe wspomagające nauczycieli przy ocenianiu muszą rozumieć coś więcej niż tylko wspólne słowa-klucze. Małe słowo takie jak „nie” może odwrócić sens zdania, a jeśli systemy automatyczne nie wychwycą tej zmiany, studenci mogą być oceniani niesprawiedliwie. Artykuł rozwiązuje ten problem, projektując nowy sposób porównywania znaczeń zdań przez komputery, ze szczególnym uwzględnieniem tego, jak słowa negujące zmieniają przekaz.
Wyzwanie małych słów o dużym wpływie
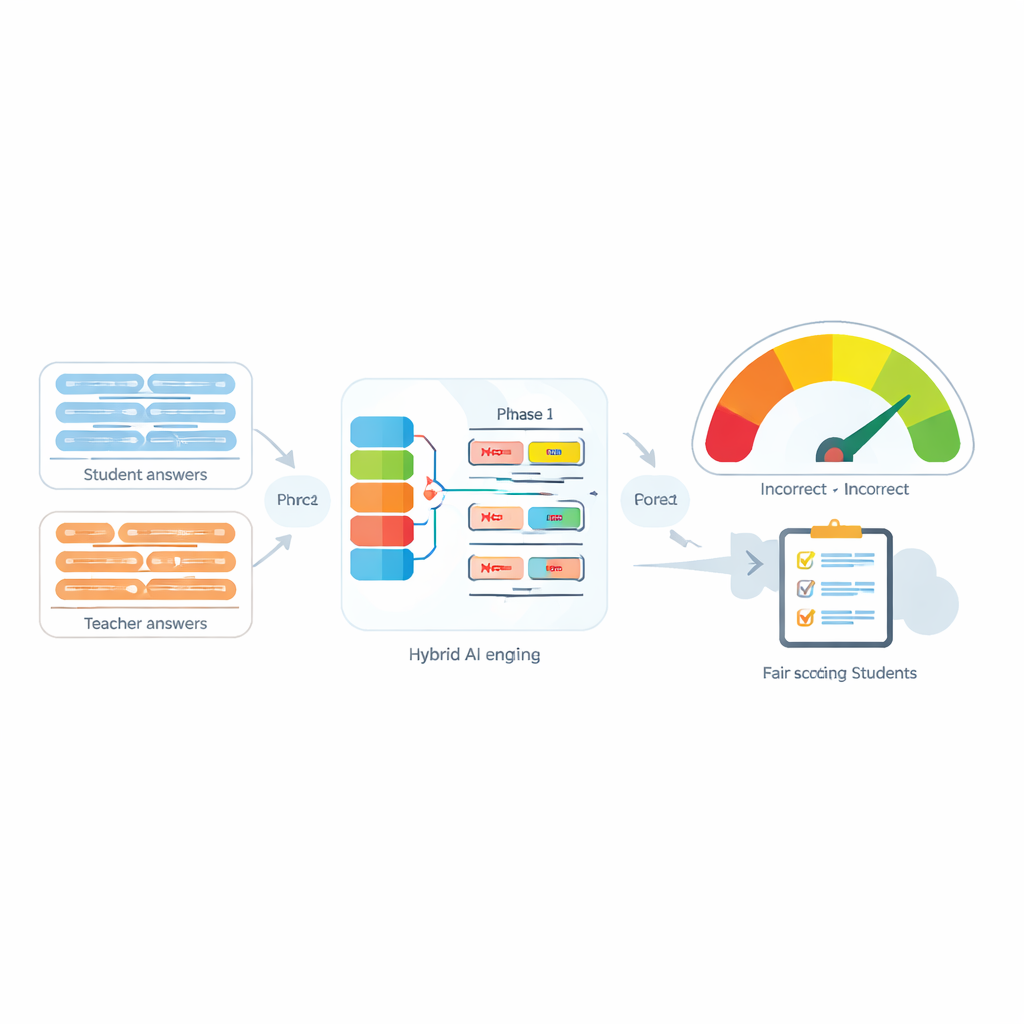
Systemy automatycznej oceny są coraz powszechniej wykorzystywane, aby odciążyć nauczycieli przez porównywanie odpowiedzi studenta z modelem odpowiedzi prowadzącego. Wiele współczesnych narzędzi robi to, zamieniając każde zdanie na numeryczny „odcisk palca”, a następnie mierząc podobieństwo tych odcisków. Te narzędzia działają całkiem dobrze, gdy nie występuje negacja, ale często zawodzą, gdy pojawiają się słowa takie jak „nie”, „nigdy” czy „żaden”. Na przykład „Metoda jest dokładna” i „Metoda nie jest dokładna” mogą dla komputera wyglądać zaskakująco podobnie, mimo że znaczą przeciwieństwa. Autorzy pokazują, że nie tylko obecność negacji, lecz także liczba słów negujących i ich pozycja w zdaniu mogą całkowicie zmienić zamierzony sens.
Budowanie zestawu danych uczącego niuansów
Aby nauczyć system prawdziwego rozumienia negacji, autorzy najpierw potrzebowali danych podkreślających te podstępne przypadki. Stworzyli Zestaw Danych Podobieństwa Zdań z Negacją (Negation-Sentence-Similarity Dataset), zawierający 8 575 par zdań z czterech dziedzin informatyki: systemów operacyjnych, baz danych, sieci komputerowych i uczenia maszynowego. Dla każdej pary ludzie przypisali wartość podobieństwa, która uwzględnia negację. Zestaw danych rejestruje też, ile słów negujących zawiera każde zdanie oraz jaki wzorzec negacji występuje — na przykład pojedyncze „nie”, parzysta bądź nieparzysta liczba zaprzeczeń, czy bardziej złożone przypadki, gdzie negacja wchodzi w interakcję ze spójnikami takimi jak „ponieważ” czy „ale”. Takie szczegółowe oznakowanie daje modelowi jawne wskazówki dotyczące tego, jak negacja kształtuje znaczenie.
Hybrydowy silnik łączący wiele perspektyw
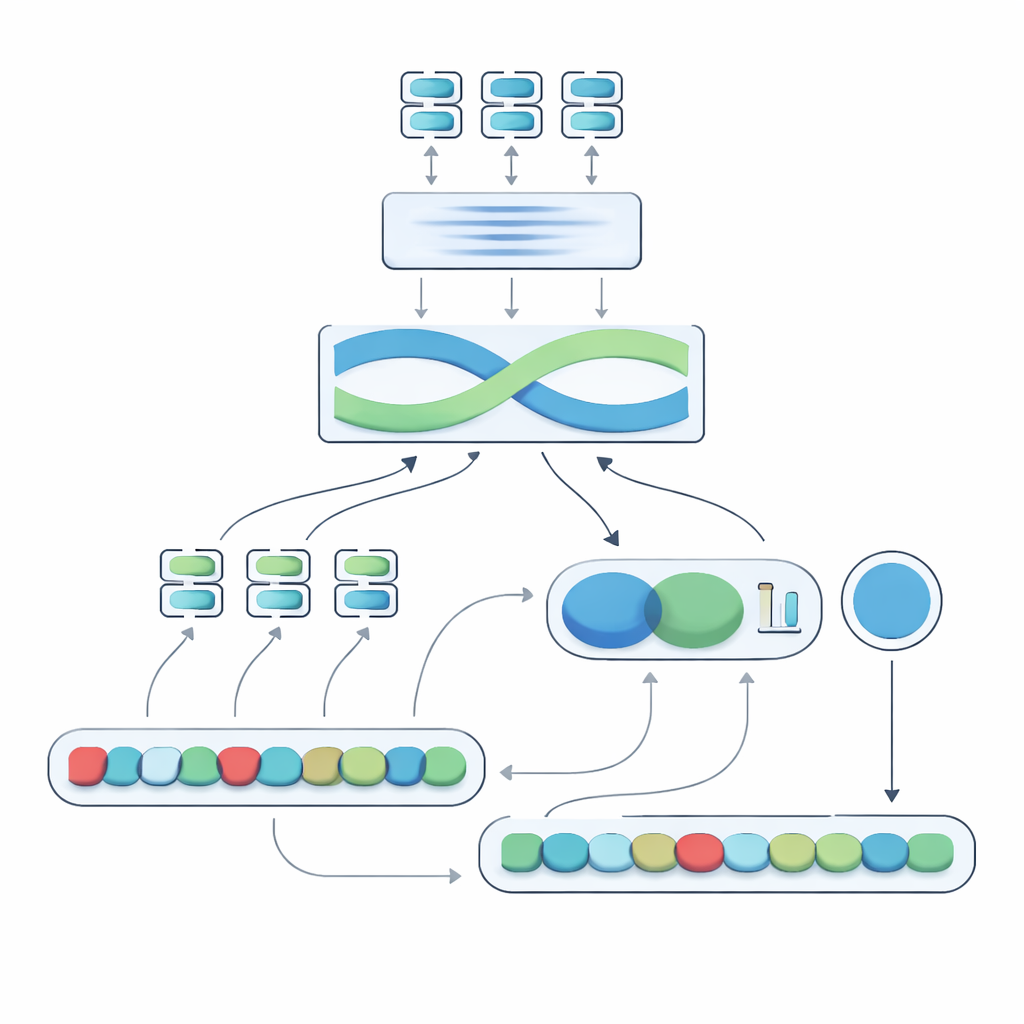
Rdzeniem proponowanego systemu, nazwanego Negation-Aligned Similarity Scorer, jest dwufazowy silnik. W pierwszej fazie każde zdanie przechodzi przez kilka różnych modeli językowych, z których każdy uchwyca nieco inne aspekty znaczenia. Ich wyjścia są łączone, a następnie przekazywane przez dwukierunkową sieć rekurencyjną analizującą zdanie w całości, uwzględniając szyk wyrazów i lokalny kontekst. Powstaje dzięki temu zwarte streszczenie zdania lepiej dostrojone do subtelnych sformułowań, w tym pozycji słów negujących względem innych wyrazów.
Nauczanie modelu wyczuwania odwrócenia przez negację
W drugiej fazie system porównuje dwa streszczenia zdań i dodaje jawne informacje o negacji. Analizuje, jak bardzo streszczenia się różnią, jak bardzo zachodzą na siebie, i łączy te sygnały z trzema prostymi cechami: różnicą w liczbie słów negujących, tym, czy zdania mają nieparzystą czy parzystą liczbę zaprzeczeń (co może odwracać lub znosić negatywne znaczenie), oraz tym, czy negacja pojawia się mniej więcej w odpowiadających sobie pozycjach. Wszystkie te wskazówki są mieszane w małej sieci predykcyjnej, która wypuszcza miarę podobieństwa w skali od 0 do 100. Trenowana end-to-end na przygotowanym zbiorze danych, ta miara staje się wrażliwa na to, jak negacja przekształca znaczenie, zamiast traktować „nie” jak zwykłe słowo.
Jak dobrze nowy oceniacz sprawdza się w praktyce
Aby przetestować swoje podejście, autorzy ocenili je zarówno na własnym zestawie danych, jak i na szeroko stosowanym benchmarku podobieństwa zdań. W porównaniu z silnymi bazowymi modelami opartymi na transformatorach używającymi standardowych metod, nowy oceniacz osiąga niższy błąd predykcji i znacznie wyższą jakość klasyfikacji, z wartością F1 bliską 0,97. W starannie dobranych przykładach daje niskie wyniki podobieństwa, gdy negacja wyraźnie odwraca sens, i wysokie, gdy podwójna negacja skutecznie go znosi — podczas gdy konkurencyjne modele wciąż mają tendencję do przeceniania podobieństwa. Badanie ablacjyjne potwierdza, że oba kluczowe składniki — warstwa rekurencyjna uwzględniająca sekwencję oraz jawne cechy negacji — są istotne dla tego poprawienia wydajności.
Co to oznacza dla uczniów i przyszłych narzędzi
Dla czytelnika niebędącego specjalistą rzecz jest prosta: sposób, w jaki mówimy „nie”, ma znaczenie i można nauczyć maszyny, by to zauważały. Poprzez łączenie wielu modeli językowych, przetwarzanie kontekstowe oraz proste zliczenia i pozycje słów negujących, proponowany oceniacz oferuje sprawiedliwszy i bardziej niezawodny sposób ustalania, czy dwa zdania naprawdę znaczą to samo. Może to pomóc systemom automatycznego oceniania unikać poważnych błędów, takich jak traktowanie „nie jest dozwolone” tak, jakby to było „jest dozwolone”. Chociaż metoda jest bardziej wymagająca obliczeniowo i wciąż skupiona na dziedzinach technicznych, wskazuje drogę ku przyszłym narzędziom lepiej uchwytującym drobną logikę języka codziennego, czyniąc technologie językowe bardziej inteligentnymi i godnymi zaufania.
Cytowanie: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Słowa kluczowe: podobieństwo zdań, negacja w języku, automatyczne ocenianie, przetwarzanie języka naturalnego, modele głębokiego uczenia