Clear Sky Science · pl
Wysokowydajne wyszukiwanie adresów IP przyspieszone przez GPU wspierające skalowalne i efektywne trasowanie w sieciach komunikacji opartych na danych
Dlaczego szybsze internetowe „drogi” mają znaczenie
Każde zdjęcie, które udostępniasz, każdy film, który oglądasz, czy wiadomość, którą wysyłasz, musi przejść przez sieć cyfrowych rozdroży zwanych routerami. Każdy router musi błyskawicznie zdecydować, dokąd wysłać kolejny pakiet danych. W miarę jak globalne użycie Internetu rośnie wykładniczo, te decyzje zapadają miliardy razy na sekundę, a nawet niewielkie opóźnienia mogą skutkować wolniejszym przeglądaniem lub przeciążeniem sieci. W artykule badane jest nowe podejście do przyspieszenia jednego z najbardziej czasochłonnych etapów tego procesu decyzyjnego poprzez wykorzystanie ogromnej mocy równoległej procesorów graficznych — tych samych układów, które napędzają gry wideo i zastosowania AI — aby utrzymać przyszłe sieci szybkie i skalowalne.
Ukryta książka adresowa Internetu
W sercu każdego routera znajduje się ogromna książka adresowa, zwana tablicą przekazywania, która mapuje zakresy adresów IP na następny przystanek w podróży. Gdy pakiet przybywa, router musi znaleźć wpis najlepiej pasujący do docelowego adresu, stosując zasadę „najdłuższego dopasowania prefiksu”: spośród wszystkich częściowych dopasowań wybiera to najbardziej szczegółowe. Tradycyjne metody programowe przechowują te prefiksy w strukturach przypominających drzewa i przeszukują je krok po kroku. To działa, ale w miarę jak tablice rosną do dziesiątek czy setek tysięcy wpisów, proces staje się wolniejszy i bardziej pamięciochłonny, zwłaszcza na zwykłych procesorach centralnych, które obsługują ograniczoną liczbę zadań jednocześnie.
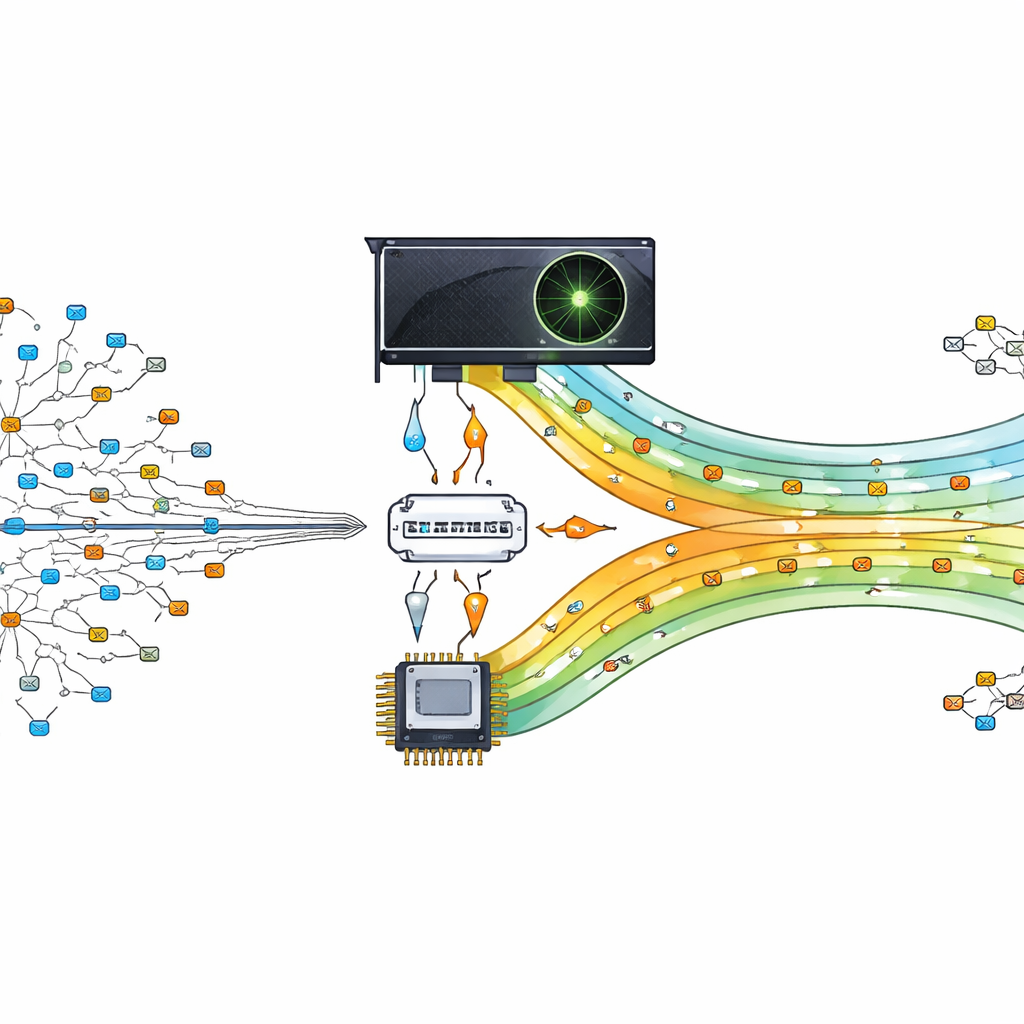
Przemiana układu graficznego w kierowcę ruchu
Autorzy proponują przeniesienie ciężkiej pracy związanej z wyszukiwaniem na procesor graficzny (GPU), układ zaprojektowany do wykonywania tysięcy drobnych zadań równolegle. Ich projekt traktuje GPU jako pomocnika głównego procesora. Procesor centralny przygotowuje i organizuje tablicę trasowania, a następnie przesyła do GPU skompresowane wersje danych. Gdy przychodzą pakiety, ich adresy docelowe są dzielone i wysyłane do GPU, gdzie wiele wątków jednocześnie szuka najlepszego dopasowania. Pozwalając, by setki lub tysiące wyszukiwań odbywały się równolegle, router jest w stanie nadążyć za współczesnym, opartym na danych zapotrzebowaniem komunikacyjnym.
Zmniejszanie adresów, by przyspieszyć decyzje
Kluczowym spostrzeżeniem pracy jest to, że krótsze adresy łatwiej przeszukiwać. Zamiast używać surowych adresów IP, autorzy kompresują je z wykorzystaniem bezstratnej metody zwanej kodowaniem Huffmana, która przypisuje krótsze kody najczęściej występującym wzorom adresowym. To zmniejsza średnią liczbę bitów potrzebnych do reprezentacji każdego wpisu, redukując zarówno zużycie pamięci, jak i wysokość struktury przeszukiwania. Następnie przechowują prefiksy w drzewie „wielobitowym”, które analizuje kilka bitów naraz zamiast pojedynczego, co dodatkowo ogranicza liczbę wymaganych kroków. Aby dopasować się do zalet GPU, przekształcają to drzewo w proste jednowymiarowe tablice, zastępując złożone śledzenie wskaźników regularnymi obliczeniami indeksów, które tysiące wątków mogą wykonywać wydajnie.
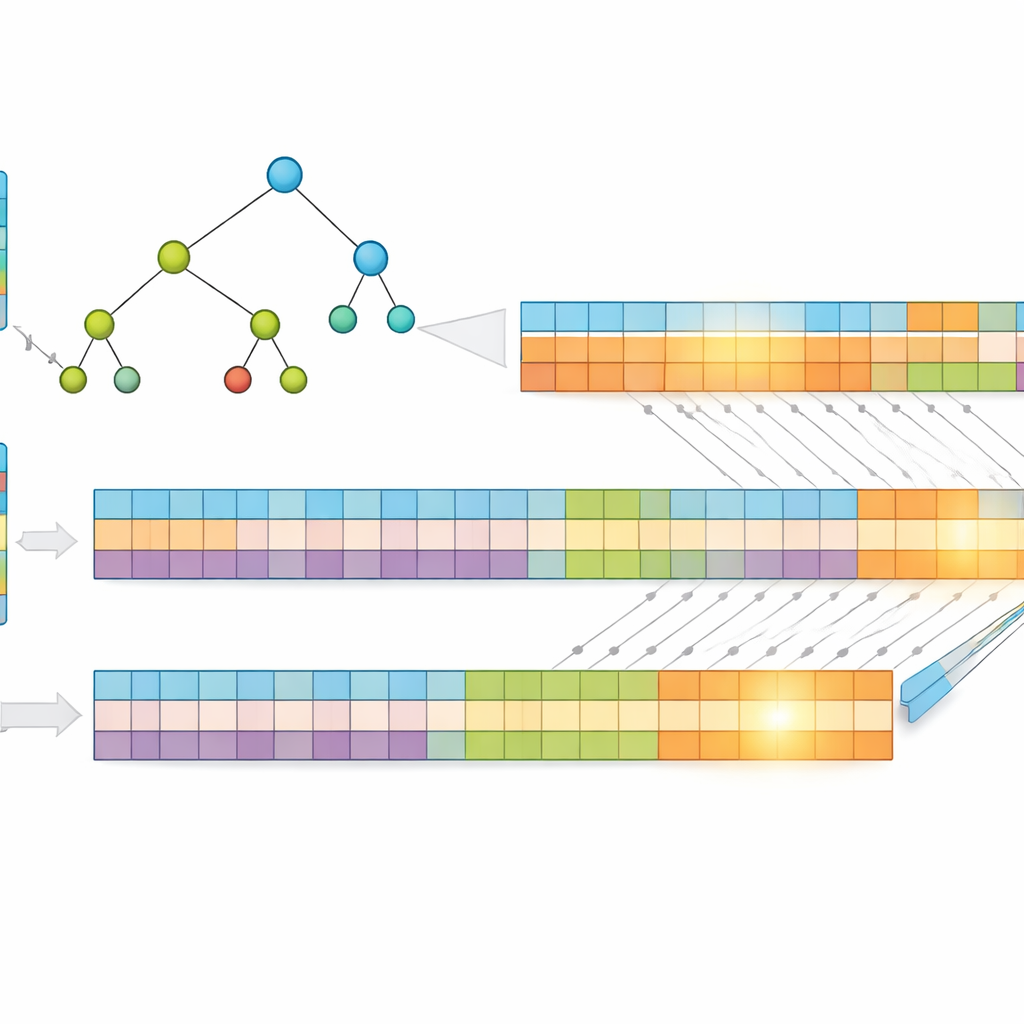
Podział problemu dla masowej równoległości
Aby jeszcze bardziej zwiększyć wydajność, badacze dzielą każdy skompresowany adres na dwie równe połówki i budują dwa oddzielne drzewa — jedno dla pierwszej połowy, drugie dla drugiej. Gdy pakiet przychodzi, GPU przeszukuje oba drzewa równolegle. Każde przeszukiwanie zwraca niewielki zbiór możliwych dopasowań, a ostateczna odpowiedź powstaje poprzez przecięcie tych zbiorów w celu znalezienia wspólnego, najbardziej szczegółowego prefiksu. Ponieważ praca jest podzielona i przetwarzana jednocześnie, czas wykonania zależy głównie od maksymalnej długości prefiksu i liczby badanych bitów na krok, a nie od liczby wpisów w tablicy. Testy z użyciem rzeczywistych danych trasowania Internetu pokazują, że ten projekt utrzymuje niemal stały czas wyszukiwania nawet w miarę wzrostu rozmiaru tablicy.
Co ujawniają eksperymenty
Zespół porównał swoją metodę opartą na GPU z wieloma dobrze znanymi podejściami, w tym klasycznymi drzewami binarnymi, drzewami skompresowanymi oraz innymi schematami przyspieszonymi przez GPU, takimi jak haszowanie i drzewa wyszukiwania binarnego. Na rzeczywistych zbiorach danych trasowania ich system przyniósł znaczące poprawy: około 83–91 procent szybszy niż popularne metody drzewowe oparte na procesorach centralnych oraz 89–97 procent szybszy niż wcześniejsze metody GPU. Kompresja także zmniejszyła zużycie pamięci średnio o około jedną trzecią, zmniejszając obciążenie ograniczonej pamięci na układzie i pomagając utrzymać struktury wyszukiwania na GPU płytkie i wydajne. Co ważne, wydajność metody pozostała stabilna przy różnych rozmiarach tablic trasowania, co podkreśla jej przydatność dla rosnących sieci.
Co to oznacza dla zwykłych użytkowników
Dla osób niebędących specjalistami konkluzja jest taka, że autorzy pokazują, jak przekształcić układ graficzny w wysoce wydajnego „policjanta ruchu” dla danych internetowych, stosując sprytne zmniejszanie i dzielenie informacji adresowych. Łącząc kompresję, inteligentniejsze układy drzew oraz masowe równoległe wyszukiwanie, ich podejście znajduje najlepszą trasę dla każdego pakietu znacznie szybciej niż wiele istniejących technik, nie zwalniając w miarę rozszerzania się „książek adresowych” Internetu. Chociaż praca jest demonstrowana głównie dla dzisiejszego systemu adresowania, te same pomysły można rozszerzyć na większą przestrzeń adresową przyszłości, pomagając utrzymać responsywność przyszłych usług online w miarę wzrostu zapotrzebowania na dane.
Cytowanie: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Słowa kluczowe: trasowanie GPU, wyszukiwanie IP, skalowalność sieci, przekazywanie pakietów, obliczenia równoległe