Clear Sky Science · pl
Ujednolicony zestaw danych do projektowania przeciwciał i nanoprzeciwciał obejmujący sekwencje, struktury i dane o powinowactwie wiązania
Dlaczego małe narzędzia odpornościowe i wielkie zbiory danych mają znaczenie
Przeciwciała i ich mniejsi kuzyni, nanoprzeciwciała, to precyzyjne „pociski” organizmu walczące z infekcjami i rakiem. Twórcy leków próbują dziś projektować te cząsteczki za pomocą komputerów, podobnie jak inżynierowie projektują samoloty. Jednak do niedawna surowy materiał dla takiego projektowania opartego na sztucznej inteligencji — wiarygodne dane o składnikach przeciwciał, ich kształtach i sile wiązania z celami — był rozproszony w wielu niekompatybilnych bazach danych. Artykuł przedstawia Antibody and Nanobody Design Dataset (ANDD), ujednolicony, publiczny zasób stworzony, by zapewnić badaczom czyste, wszechstronne dane potrzebne do opracowywania kolejnej generacji terapii celowanych.
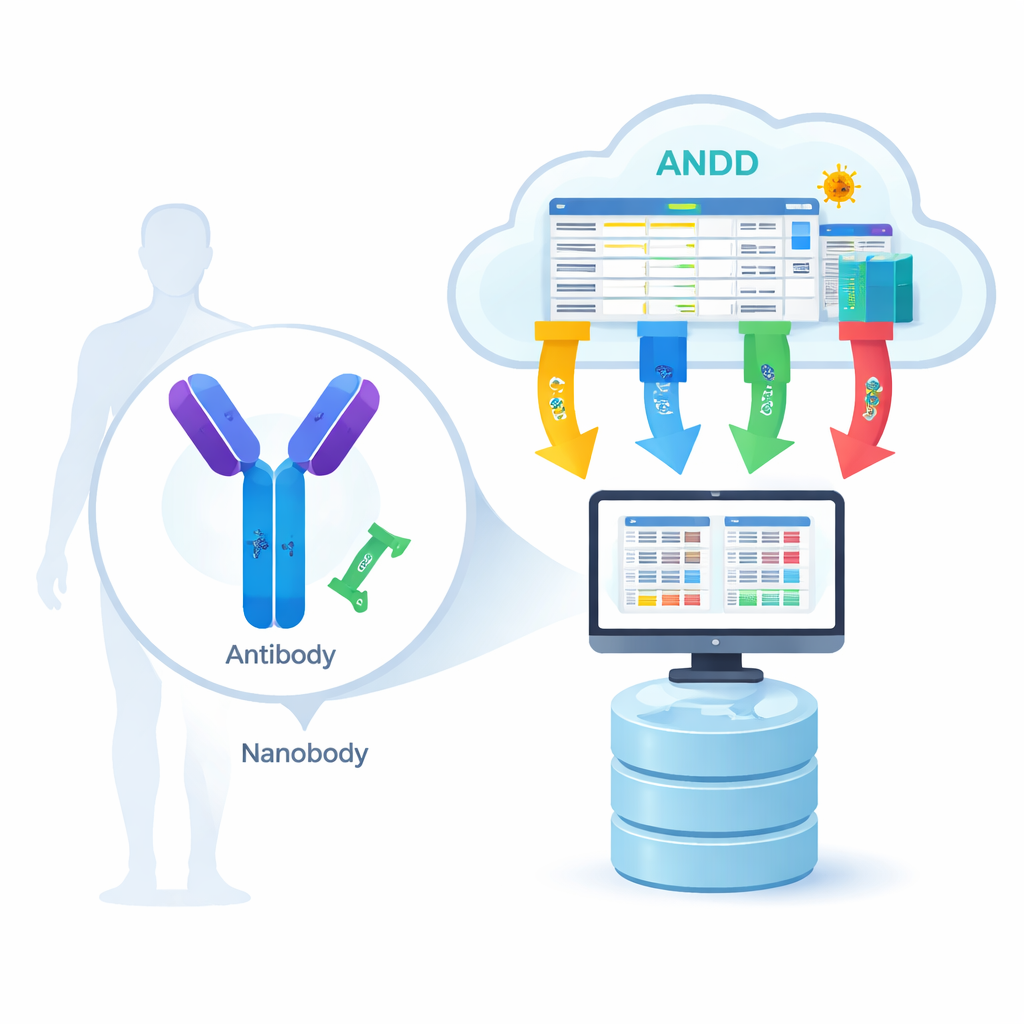
Od biologicznego zamka i klucza do cyfrowego planu
Przeciwciała to duże białka w kształcie litery Y, natomiast nanoprzeciwciała to znacznie mniejsze, jednoczęściowe wersje występujące u zwierząt takich jak lamy i alpaki. Oba rozpoznają specyficzne „zamki” na wirusach, komórkach nowotworowych lub innych białkach związanych z chorobą. Aby modele komputerowe mogły nauczyć się, jak działa to rozpoznawanie, potrzebują czterech rodzajów informacji dla wielu przykładów: sekwencji aminokwasowej (lista części), struktury 3D (kształt), antygenu (cel) oraz siły wiązania (jak mocno ze sobą przylegają). Do tej pory większość zasobów zawierała tylko jeden lub dwa z tych elementów naraz, zmuszając naukowców do przeskakiwania między bazami i ręcznego scalania danych, co spowalniało postęp i wprowadzało błędy.
Zgromadzenie rozproszonych elementów w jednej uporządkowanej bibliotece
Zespół ANDD zebrał dane z 15 głównych źródeł, w tym dedykowanych baz danych przeciwciał i nanoprzeciwciał, ogólnych repozytoriów białek, a nawet dokumentów patentowych. Surowe dane przeszły następnie przez starannie opracowany pipeline: pobieranie, przekonwertowanie do wspólnego schematu, weryfikację identyfikatorów, usuwanie duplikatów i ujednolicanie zasad nazewnictwa. Gdy bazy danych nie zgadzały się ze sobą, priorytet nadawano źródłom skuratowanym i bezpośrednim eksperymentom. Efektem końcowym jest jedna tabela oraz zestaw plików strukturalnych łączących sekwencję, strukturę, cel i informacje o wiązaniu w spójny sposób, a każdy rekord jest oznaczony tak, by użytkownicy mogli dokładnie śledzić jego pochodzenie i sposób przetworzenia.
Warstwowe szczegóły dopasowane do różnych potrzeb badawczych
Niekiedy wpisy w ANDD różnią się bogactwem informacji, dlatego autorzy uporządkowali zbiór w warstwy o rosnącym poziomie szczegółu. Na najszerszym poziomie znajduje się 48 683 wpisów przeciwciał i nanoprzeciwciał ze znaną sekwencją. Duża podgrupa zawiera dodatkowo struktury 3D, a mniejsza — także sekwencje białek antygenów. Najbardziej szczegółowa warstwa — obejmująca tysiące wpisów — zawiera zmierzone lub przewidywane wartości powinowactwa wiązania. Dla przeciwciał, na przykład, 18 464 wpisów ma sekwencje, ta sama liczba łączy sekwencję ze strukturą, ponad 8 000 obejmuje także sekwencje antygenów, a 7 737 posiada pełne dane: sekwencję, strukturę, antygen i powinowactwo. Równoległa hierarchia istnieje dla nanoprzeciwciał, dając zarówno eksperymentatorom, jak i twórcom modeli elastyczność: można wybierać duże, proste zbiory danych lub mniejsze, bogatsze w informacje podzbiory.
Uzupełnianie luk w danych o sile wiązania
Siła wiązania jest kluczowa dla projektowania leków, lecz wartości eksperymentalne są rzadkie i raportowane nierównomiernie. Aby zniwelować tę lukę, nie zacierając przy tym granicy między danymi a przewidywaniami, autorzy użyli specjalistycznego narzędzia głębokiego uczenia, ANTIPASTI, by oszacować siłę wiązania tylko dla wpisów, które miały strukturę, ale brakowało dla nich pomiarów. Te 2 271 przewidywanych wartości są wyraźnie oznaczone i przechowywane oddzielnie od około 7 000 wartości zmierzonych eksperymentalnie. Zespół następnie sprawdził ogólną spójność za pomocą innego modelu, AlphaBind, oraz porównując matematycznie powiązane miary wiązania. Silne korelacje i niskie błędy sugerowały, że skuratowane wartości eksperymentalne są wiarygodne, a przewidywane wartości podążają za sensownymi trendami, bez traktowania ich jako ostatecznej prawdy.
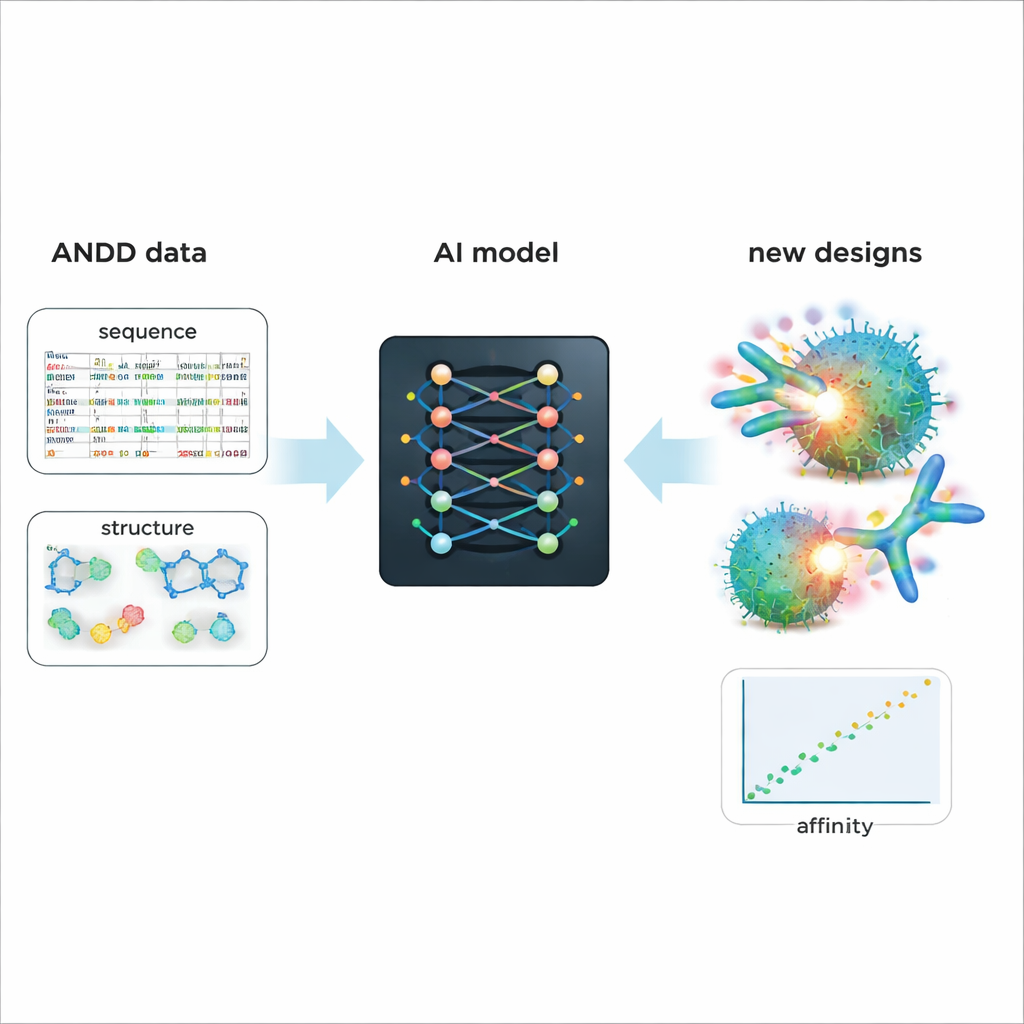
Wzmacnianie inteligentniejszego projektowania przyszłych leków
Aby pokazać praktyczną wartość ANDD, autorzy dopracowali istniejący generatywny model AI projektujący przeciwciała i nanoprzeciwciała. Trening na połączonych danych ANDD — sekwencjach, strukturach, celach i powinowactwie — dał w efekcie wygenerowane cząsteczki o lepiej przewidywanym wiązaniu i bardziej realistycznych kształtach niż model bazowy trenowany na starszych, prostszych danych. Poza tym studium przypadku ANDD jest ogólnodostępny na licencji dopuszczającej szerokie użycie, zawiera pełną dokumentację oraz powtarzalny pipeline budowy i jest zaprojektowany do regularnych aktualizacji. Dla osób niebędących specjalistami kluczowy wniosek jest taki, że ANDD przekształca chaotyczny zbiór danych o przeciwciałach w spójną, wiarygodną bibliotekę — dając narzędziom AI znacznie lepszy punkt wyjścia do projektowania precyzyjnych, skuteczniejszych leków biologicznych.
Cytowanie: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
Słowa kluczowe: projektowanie przeciwciał, nanoprzeciwciała, powinowactwo wiązania, terapie biologiczne, AI w odkrywaniu leków