Clear Sky Science · pl
Zbiór danych PreprintToPaper: łączenie preprintów z bioRxiv z publikacjami w czasopismach
Dlaczego wczesne badania mają znaczenie dla nas wszystkich
Długo zanim odkrycie naukowe ukaże się w błyszczącym czasopiśmie, często pojawia się jako „preprint” – wczesna, swobodnie udostępniona wersja pracy. W czasie pandemii COVID‑19 preprinty kształtowały nagłówki wiadomości, debaty publiczne, a nawet polityki zdrowotne. Tymczasem zaskakująco trudno było śledzić, które wczesne badania później stały się formalnymi artykułami w czasopismach, a które nigdy tego nie dokonały. Niniejszy artykuł przedstawia zbiór danych PreprintToPaper, dułą, starannie sprawdzoną mapę łączącą preprinty z zakresu nauk życia na serwerze bioRxiv z ich ostatecznymi publikacjami w czasopismach, dając publiczności, dziennikarzom i badaczom jaśniejszy obraz tego, jak wczesne wyniki przemieszczają się w systemie naukowym.
Śledzenie drogi od szkicu do artykułu
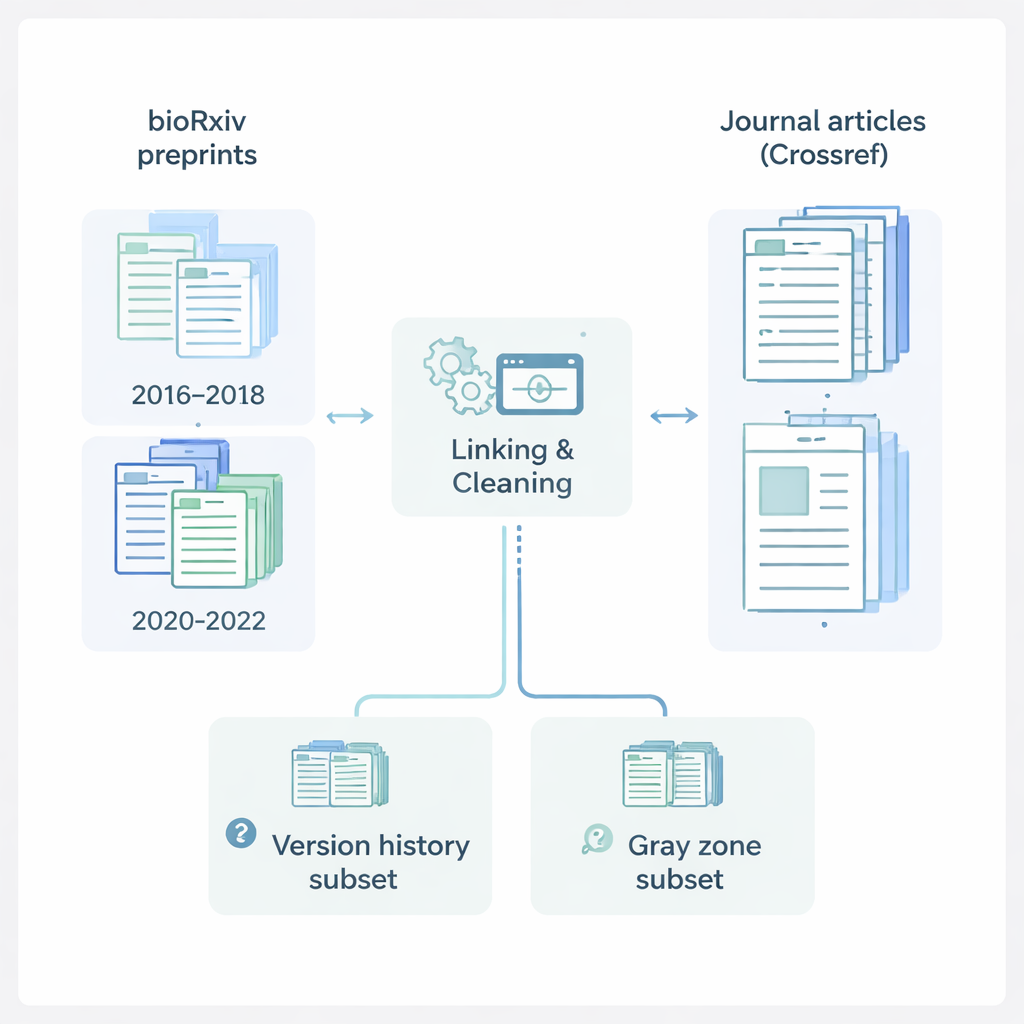
Autorzy skupili się na bioRxiv, ważnym serwerze internetowym, na którym badacze z nauk przyrodniczych publikują preprinty. Zebrali dane o 145 517 preprintach z dwóch kluczowych przedziałów czasowych: 2016–2018, przed pandemią COVID‑19, oraz 2020–2022, w trakcie intensywnego boomu publikacyjnego wywołanego pandemią. Dla każdego preprintu zapisali takie informacje jak tytuł, streszczenie, autorzy, instytucje, dziedzina, licencja i daty zgłoszenia. Następnie skorzystali z Crossref — centralnego rejestru artykułów czasopism — aby pobrać odpowiadające dane o opublikowanych pracach: nazwy czasopism, daty publikacji i pełne listy autorów. Łącząc te źródła, skonstruowali bogaty, zunifikowany zapis śledzący badanie od jego pierwszego publicznego ukazania się jako preprint po ostateczną formę w czasopiśmie naukowym.
Porządkowanie preprintów w klarowne grupy
Aby uporządkować tę dużą kolekcję, zespół pogrupował każdy preprint do jednej z trzech kategorii. Preprinty „Opublikowane” miały wyraźny cyfrowy link z bioRxiv do artykułu w czasopiśmie. Pozycje „Tylko preprint” zostały zamieszczone na serwerze, ale nie wykazywały oznak opublikowania gdzie indziej. Najbardziej intrygująca grupa, nazwana „Strefą szarości”, obejmuje przypadki, które wyglądają, jakby mogły zostać opublikowane w czasopiśmie, ale brakuje im oficjalnego linku na bioRxiv. Aby uchwycić, jak preprinty zmieniają się w czasie, badacze stworzyli też oddzielny plik historii wersji, wymieniający każdą dostępną wersję dla preprintów, które miały wersję pierwotną i co najmniej jedną późniejszą aktualizację. Pozwala to innym badać, jak zmieniają się tytuły, listy autorów i inne szczegóły między pierwszym szkicem a ostatnią wersją preprintu.
Wykrywanie ukrytych dopasowań i ich ręczne sprawdzanie
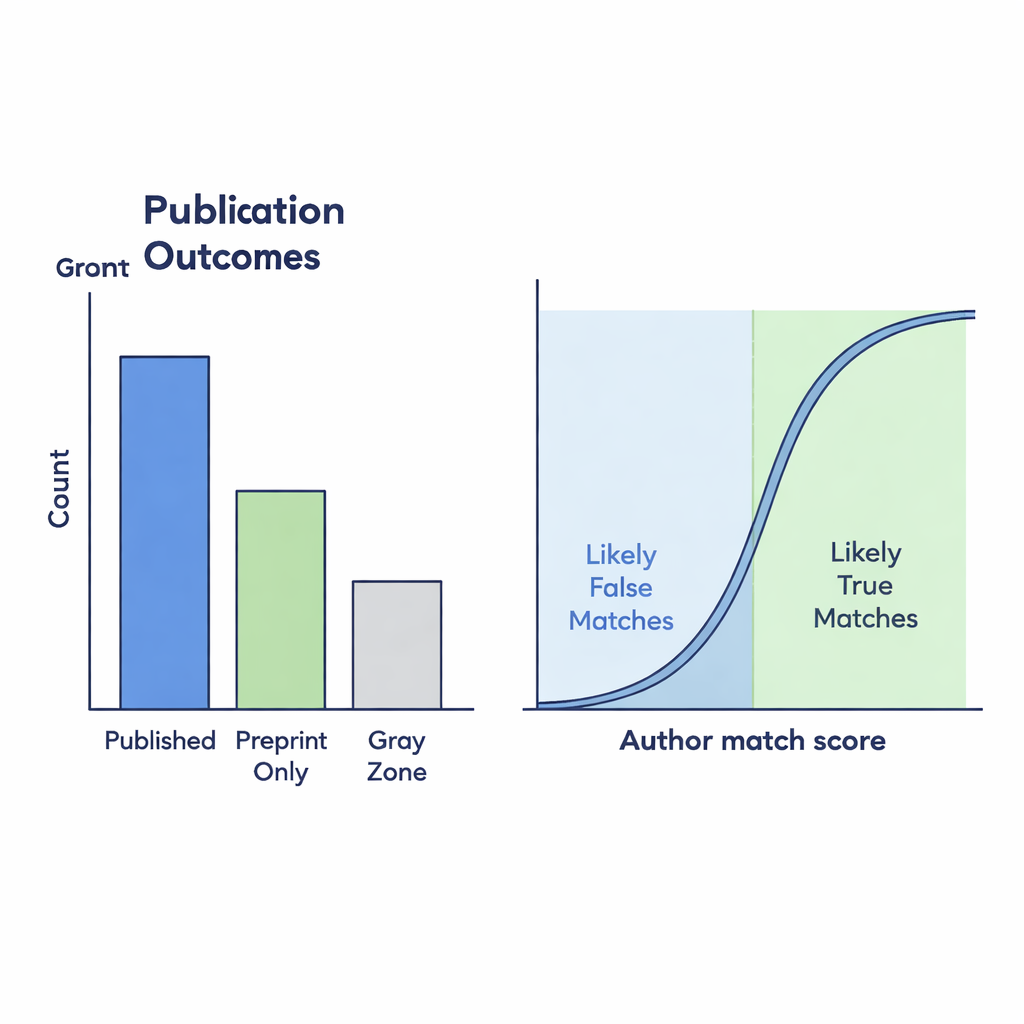
Wiele preprintów, które faktycznie zostały opublikowane, nigdy nie otrzymuje poprawnego linku zwrotnego na bioRxiv, tworząc martwe punkty dla każdego, kto próbuje śledzić dorobek naukowy. Aby odkryć te brakujące powiązania, autorzy porównali tytuły preprintów i listy autorów z rekordami czasopism w Crossref. Użyli współczynnika podobieństwa w skali od 0 do 1, aby zmierzyć, jak ściśle dopasowują się dwa tytuły; potencjalne łącza ze Strefy szarości musiały uzyskać wynik co najmniej 0,75. Następnie dopracowali te kandydatury miarami opartymi na autorach: jak bardzo różniła się liczba autorów i jak podobne były podane nazwy. Aby sprawdzić, czy te automatyczne reguły są wiarygodne, dwaj ludzcy adnotatorzy ręcznie przejrzeli 299 przypadków granicznych. Ich oceny były mocno zgodne, a model statystyczny wykazał, że gdy listy autorów dobrze pasowały, przypuszczalne powiązanie miało dużą szansę być prawdziwe.
Co liczby ujawniają o produkcji naukowej
Gotowy zbiór danych pokazuje, jak wzorce preprintowania i publikowania zmieniły się przed i podczas pandemii. Ogólnie zawiera ponad 90 000 wyraźnie opublikowanych preprintów, ponad 35 000, które wydają się pozostać tylko na serwerze, oraz około 19 000 przypadków ze Strefy szarości, gdzie powiązanie z artykułem w czasopiśmie wymagało detektywistycznej pracy. Gdy liczy się tylko oficjalnie powiązaną grupę „Opublikowane”, wydaje się, że znacznie mniejszy odsetek preprintów przekształca się w artykuły czasopism w czasie. Jednak gdy uwzględni się prawdopodobne dopasowania ze Strefy szarości — te o silnym podobieństwie autorów — spadek wskaźników publikacji jest znacznie mniej dramatyczny. Sugeruje to, że brakujące linki w infrastrukturze mogą wprowadzać w błąd co do tego, jak zmienia się krajobraz naukowy.
Dlaczego to źródło jest przydatne poza specjalistami
Dla osób spoza danej dziedziny głównym przesłaniem jest to, że wczesne wyniki naukowe nie znikają po prostu w czarnej skrzynce. Dzięki zbiorowi danych PreprintToPaper staje się możliwe zobaczenie, które szybko pojawiające się wyniki ostatecznie przechodzą przez recenzję, ile trwa ta droga i jakie rodzaje badań nie opuszczają etapu preprintu. Decydenci mogą wykorzystać te informacje do oceny, jak dobrze działają praktyki otwartej nauki; dziennikarze mogą lepiej ocenić, jak solidny jest dany wynik; a badacze mogą budować narzędzia, które przesiewają i podsumowują przytłaczający napływ prac. Krótko mówiąc, ten zbiór danych przekształca chaotyczny potok wczesnych badań w bardziej śledzalny, odpowiedzialny zapis tego, jak pomysły przechodzą od pierwszego opublikowania do dopracowanej publikacji.
Cytowanie: Badalova, F., Sienkiewicz, J. & Mayr, P. PreprintToPaper dataset: connecting bioRxiv preprints with journal publications. Sci Data 13, 301 (2026). https://doi.org/10.1038/s41597-026-06867-3
Słowa kluczowe: preprinty, publikacje naukowe, otwarta nauka, badania nad COVID-19, bibliometria