Clear Sky Science · pl
Duży zestaw danych komórek krwi obwodowej do zautomatyzowanej analizy hematologicznej
Dlaczego zdjęcia komórek krwi są ważne
Każde rutynowe badanie krwi kryje mikroskopijny świat komórek, które mogą ujawnić infekcje, anemię, a nawet nowotwory krwi na długo przed pojawieniem się oczywistych objawów. Lekarze tradycyjnie oglądają te komórki pod mikroskopem, co jest pracą wymagającą precyzji, ale czasochłonną. W tym badaniu przedstawiono bardzo dużą, starannie opisną kolekcję obrazów komórek krwi, zaprojektowaną tak, aby nauczyć komputery automatycznego rozpoznawania tych komórek. Celem jest przyspieszenie przyszłych badań krwi, zwiększenie ich spójności i dostępności przez dostarczenie sztucznej inteligencji wizualnego doświadczenia potrzebnego do wspierania lekarzy w dokładnym odczycie rozmazów krwi.
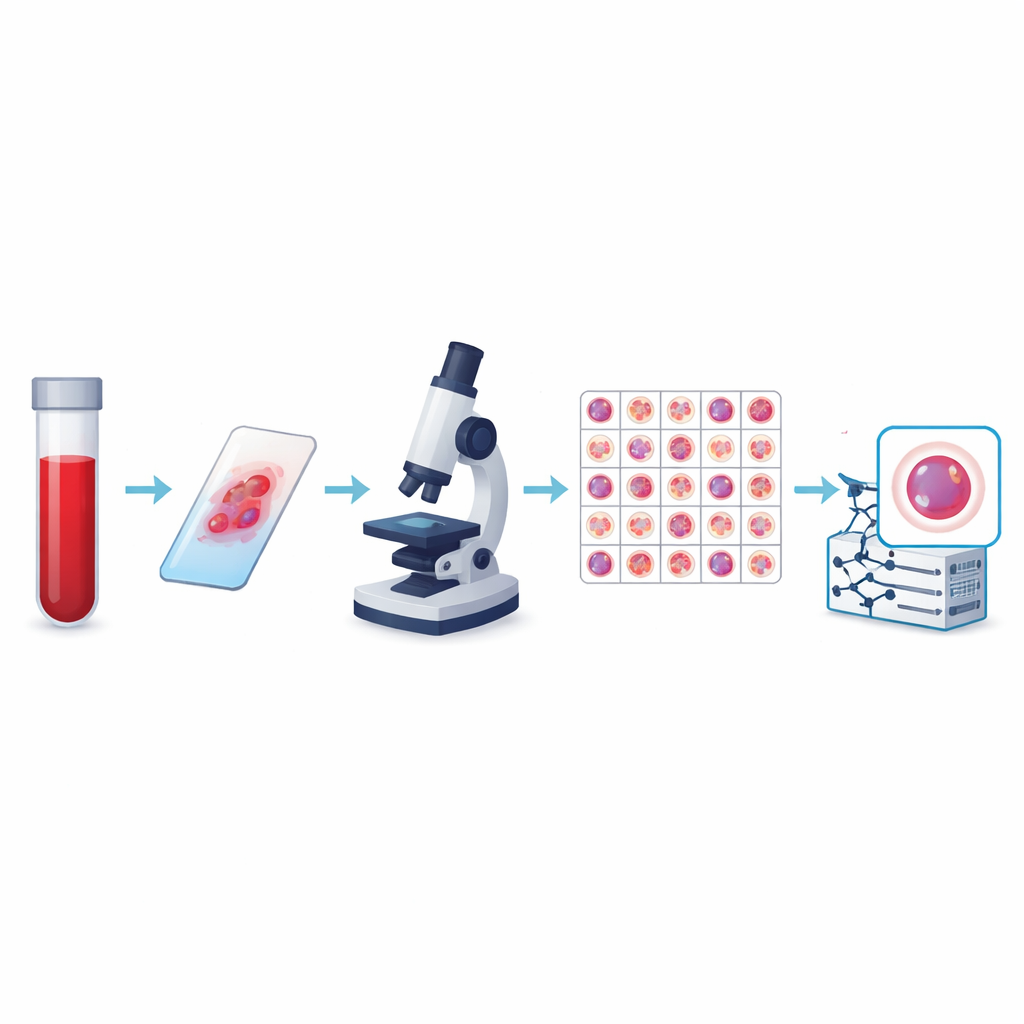
Od prostego liczenia do inteligentnego obrazowania
Leukocyty są kluczowymi obrońcami w naszym układzie odpornościowym, a ich skład i wygląd dostarczają istotnych wskazówek dotyczących stanu zdrowia. Wzrost liczby niektórych typów komórek może sygnalizować infekcję lub alergię, podczas gdy nagłe pojawienie się niedojrzałych komórek „blastów” może ostrzegać przed białaczką. Laboratoria już używają zautomatyzowanych maszyn do liczenia komórek, jednak subtelne zmiany kształtu wciąż często wymagają oceny eksperta. Recenzenci ludzkí mogą się nie zgadzać, a badanie po jednym preparacie zajmuje czas. W miarę jak medycyna przesuwa się w stronę obrazowania cyfrowego i sztucznej inteligencji, rośnie potrzeba dużych, wiarygodnych zbiorów obrazów, które mogą nauczyć komputery rozpoznawania tych charakterystycznych wzorców z taką samą niezawodnością jak doświadczony hematolog.
Budowanie ogromnej biblioteki komórek krwi
Autorzy stworzyli obecnie największą publiczną kolekcję obrazów komórek krwi obwodowej, nazwaną zestawem danych KU-Optofil PBC. Zawiera ona 31 489 obrazów w wysokiej rozdzielczości pojedynczych komórek podzielonych na 13 grup, w tym powszechne komórki obronne, takie jak limfocyty i neutrofile segmentowane, oraz rzadsze, lecz klinicznie istotne typy, takie jak blasty, myelocyty i limfocyty reaktywne. Wszystkie obrazy pochodzą z zabarwionych rozmazów przygotowanych według ustandaryzowanych procedur w jednym szpitalu, przy użyciu tego samego systemu obrazowania. Taka spójność oznacza, że komputery uczące się na tych danych widzą stabilny, dobrze kontrolowany obraz każdego typu komórki, zamiast mozaiki niekompatybilnych zdjęć.
Oczy ekspertów i staranna kuracja
Aby zestaw danych był wiarygodny, każdy obraz został oznaczony niezależnie przez dwóch doświadczonych techników laboratoryjnych, a ewentualne rozbieżności rozstrzygał trzeci ekspert. Kontrole statystyczne wykazały bardzo silną zgodność między recenzentami dla każdego głównego typu komórki, w niektórych przypadkach osiągając zgodność doskonałą. Zespół zastosował także surowe zasady decydujące o tym, które obrazy zachować, odrzucając rozmyte, nachodzące na siebie lub słabo wybarwione komórki. Końcowe obrazy mają jednolity rozmiar i format kolorów oraz są zorganizowane w foldery treningowe, walidacyjne i testowe, aby inni badacze mogli uczciwie porównywać algorytmy. Dodatkowe pliki łączą każdy obraz z anonimowym pacjentem, co pozwala na badania sprawdzające, czy model rzeczywiście uogólnia wiedzę z jednej osoby na drugą.
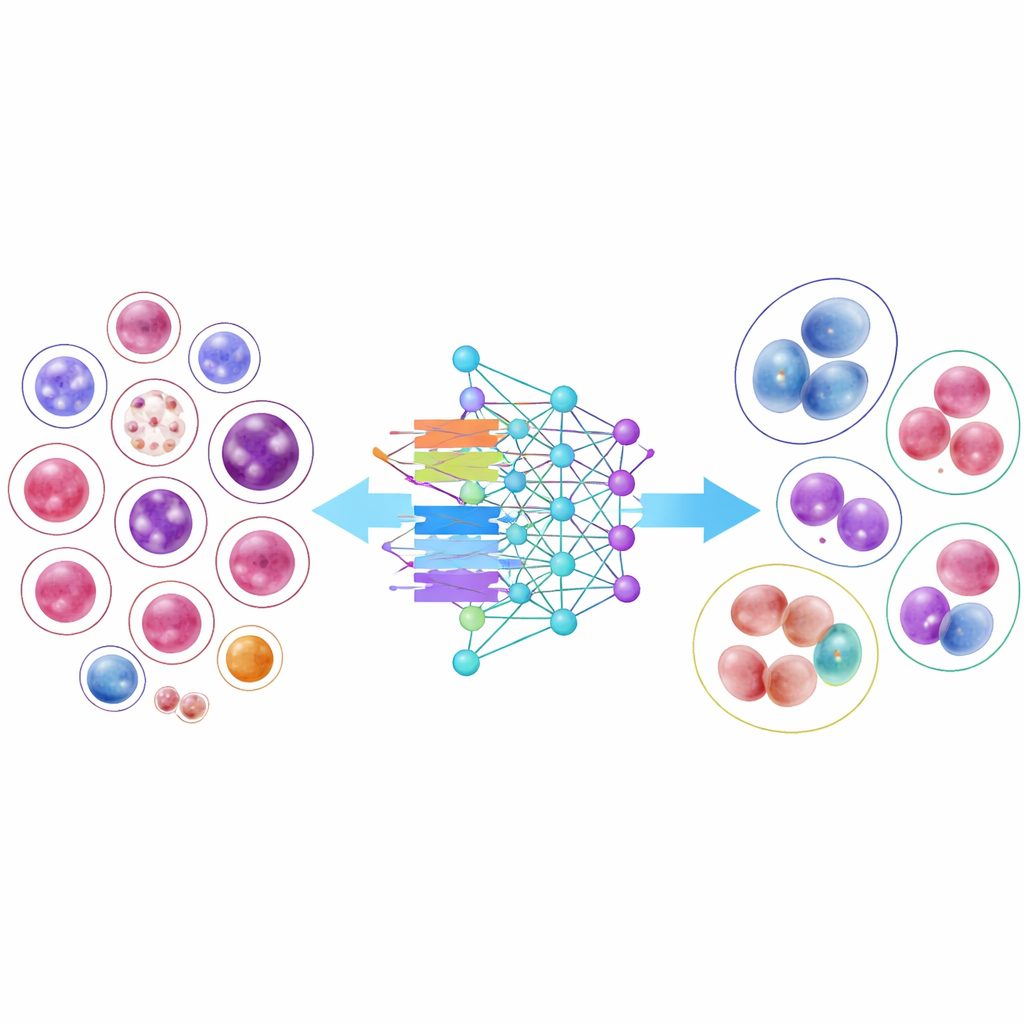
Testowanie modeli AI
Aby pokazać praktyczność tej biblioteki, badacze wytrenowali 14 nowoczesnych modeli rozpoznawania obrazów, od klasycznych konwolucyjnych sieci neuronowych po nowsze architektury oparte na transformatorach. Kilka kompaktowych, wydajnych modeli wypadło zaskakująco dobrze, a jedna architektura, DenseNet-121, sklasyfikowała komórki poprawnie ponad 95 procent czasu w ujęciu średnim. Wyniki uwypukliły jednak ważną trudność praktyczną: powszechne typy komórek mające tysiące przykładów były rozpoznawane niemal perfekcyjnie, podczas gdy bardzo rzadkie komórki, zaledwie kilkudziesięcioma obrazami, wciąż były znacznie trudniejsze do sklasyfikowania. Nawet gdy badacze dostosowali trening, aby „zwracać większą uwagę” na te nieliczne klasy, ogólna dokładność spadła, a poprawy dla rzadkich typów były umiarkowane, co podkreśla wyzwanie uczenia się z ograniczonych przykładów.
Co to oznacza dla przyszłych badań krwi
Dla osób niezwiązanych bezpośrednio ze specjalnością kluczowe przesłanie jest takie, że ta praca dostarcza surowego wizualnego doświadczenia, którego systemy komputerowe potrzebują, by stać się godnymi zaufania partnerami w odczycie rozmazów krwi. Poprzez zgromadzenie dużej, zróżnicowanej i starannie sprawdzonej biblioteki obrazów komórek krwi oraz pokazanie, że wiele różnych modeli AI potrafi się na niej uczyć, autorzy tworzą podstawy narzędzi, które mogą przyspieszyć diagnozę, zmniejszyć błąd ludzki i rozszerzyć analizę na poziomie eksperckim do klinik z mniejszą liczbą specjalistów. Jednocześnie mieszane wyniki dotyczące rzadkich typów komórek przypominają, że nawet duże zbiory danych mają swoje słabe punkty, i że poprawa opieki nad pacjentami z nietypowymi lub wczesnymi stadami chorób będzie wymagać dalszego rozszerzania i udoskonalania tych kolekcji obrazów.
Cytowanie: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Słowa kluczowe: obrazowanie komórek krwi, sztuczna inteligencja medyczna, hematologia, uczenie głębokie, zbiory danych medycznych