Clear Sky Science · pl
Zestaw obrazów histopatologicznych w wysokim powiększeniu do diagnostyki i prognozowania raka płaskonabłonkowego jamy ustnej
Dlaczego to badanie ma znaczenie
Rak jamy ustnej może ukrywać się na widoku, zaczynając jako niewielka ranka w ustach i przekształcając się w chorobę zagrażającą życiu. Lekarze opierają decyzje o ciężkości nowotworu i ryzyku jego nawrotu lub przerzutów na obrazach tkanek oglądanych pod mikroskopem, ale analiza tych preparatów jest czasochłonna i wymagająca. Niniejsze badanie przedstawia bogaty, nowy zbiór obrazów zaprojektowany, by pomóc systemom sztucznej inteligencji (AI) w czytaniu tych skrawków razem z patologami, z długoterminowym celem dostarczania pacjentom szybszych i dokładniejszych informacji o chorobie i możliwościach leczenia.
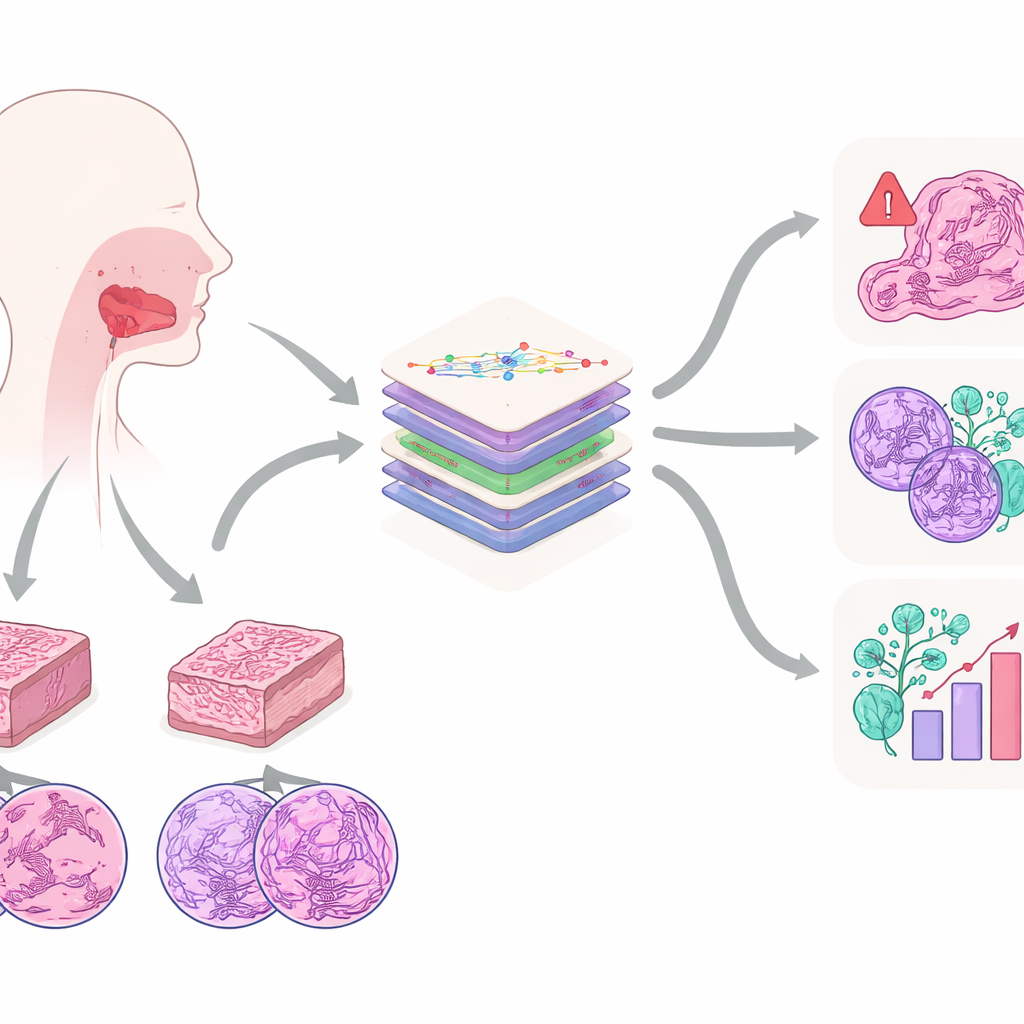
Bliższe spojrzenie na powszechny nowotwór jamy ustnej
Praca koncentruje się na raku płaskonabłonkowym jamy ustnej, jednym z najczęstszych i najbardziej agresywnych nowotworów w tej lokalizacji. Często rozwija się u osób z historią palenia tytoniu lub nadużywania alkoholu i może szerzyć się do pobliskich tkanek oraz węzłów chłonnych szyi. Obecnie złotym standardem diagnostycznym pozostaje ocena patologa preparatów barwionych pod mikroskopem. Na podstawie tych skrawków eksperci oceniają, jak bardzo komórki są nieprawidłowe, jak głęboko nacieka guz, czy doszło do zajęcia nerwów lub naczyń, oraz wiele innych cech wpływających na przeżycie. Autorzy twierdzą, że te mikroskopowe wzory zawierają znacznie więcej informacji, niż pojedynczy człowiek jest w stanie łatwo śledzić, co czyni je idealnym celem dla nowoczesnej AI.
Budowanie pełniejszego obrazu z obrazów tkanek
Aby odblokować te informacje, zespół stworzył zbiór danych Multi‑OSCC: obrazy mikroskopowe od 1 325 pacjentów leczonych z powodu raka jamy ustnej w jednym szpitalu w latach 2015–2022. Dla każdego pacjenta patolodzy przygotowali dwa bloki tkankowe — jeden z centrum guza i drugi z jego krawędzi inwazyjnej — a następnie zarejestrowali obrazy wysokiej rozdzielczości na trzech poziomach powiększenia, podobnie jak patrzenie na miasto z samolotu, z dachu i z narożnika ulicy. W efekcie powstało sześć starannie dobranych obrazów na pacjenta, z których każdy zawiera kluczowe struktury, takie jak gniazda komórek nowotworowych, spirale keratyny i wyraźnie nieprawidłowe jądra komórkowe. Równolegle do obrazów badacze zgromadzili szczegółowe dokumentacje medyczne i długoterminowe obserwacje, by ustalić, które guzy nawróciły lub dały przerzuty.
Sześć pytań, które naprawdę obchodzi lekarzy
To, co wyróżnia Multi‑OSCC, to odzwierciedlenie rzeczywistych pytań klinicznych zamiast skupiania się na pojedynczej etykiecie. Każdy pacjent w zbiorze jest oznaczony względem sześciu istotnych wyników. Jednym z nich jest to, czy guz nawrocił w ciągu dwóch lat po operacji — krytyczny okres, gdy występuje większość nawrotów. Innym jest to, czy komórki nowotworowe dotarły już do węzłów chłonnych szyi, co wpływa na decyzje o rozległości operacji szyi. Cztery dodatkowe etykiety odzwierciedlają stopień zróżnicowania komórek guza, głębokość nacieku oraz to, czy guz wszedł do naczyń krwionośnych lub rozprzestrzenił się wzdłuż nerwów — subtelne, lecz silne wskazówki dotyczące groźby choroby. Takie podejście pozwala modelom AI uczyć się nie tylko „rak kontra zdrowa tkanka”, lecz pełniejszego obrazu ryzyka i nasilenia choroby.
Nauczanie AI czytania złożonych preparatów
Następnie badacze ocenili, jak różne strategie AI radzą sobie z tym wymagającym zbiorem danych. Porównali kilka nowoczesnych rdzeni rozpoznawania obrazów, w tym klasyczne sieci konwolucyjne oraz nowsze modele oparte na transformatorach, i stwierdzili, że transformery wstępnie wytrenowane specjalnie na obrazach patologicznych sprawowały się najlepiej ogólnie. Testowali sposoby łączenia informacji z sześciu obrazów przypadających na pacjenta i odkryli, że prosta strategia — wydobycie cech z każdego obrazu i następnie ich konkatenacja — przewyższała bardziej złożone schematy fuzji. Zbadali także, jak standaryzacja barw barwienia wpływa na wydajność, ujawniając, że zachowanie oryginalnego koloru było kluczowe dla przewidywania nawrotu, podczas gdy łagodna normalizacja kolorów pomagała przy innych zadaniach diagnostycznych.
Ograniczenia, niespodzianki i co dalej
Jedną z niespodzianek było to, że wytrenowanie pojedynczego modelu AI do jednoczesnego rozwiązywania wszystkich sześciu zadań nie przewyższyło jeszcze modeli trenowanych osobno dla każdego zadania. Inną była obserwacja, że szczegółowe fragmenty mikroskopowe, choć bogate w detale komórkowe, nadal nie zastępują szerokiego architektonicznego widoku, jaki dają całe skrawki szkiełek. Mimo to modele trenowane na obrazach Multi‑OSCC wyraźnie przewyższały modele wykorzystujące wyłącznie dane kliniczne, takie jak wiek, nawyki czy historia chorób, szczególnie w przewidywaniu nawrotu guza. Autorzy przedstawiają Multi‑OSCC jako punkt wyjścia: publiczny, dobrze udokumentowany zbiór danych, którego inni mogą używać do rozwoju i porównywania metod. Dla pacjentów długoterminowa obietnica jest taka, że przyszłe narzędzia zbudowane na tej bazie mogłyby pomóc lekarzom bardziej niezawodnie wykrywać, które raki jamy ustnej mają większe prawdopodobieństwo nawrotu lub rozsiewu, prowadząc do lepiej dobranych terapii i w efekcie do poprawy szans przeżycia.
Cytowanie: Guan, J., Guo, J., Chen, Q. et al. A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis. Sci Data 13, 371 (2026). https://doi.org/10.1038/s41597-026-06736-z
Słowa kluczowe: rak jamy ustnej, obrazy histopatologiczne, sztuczna inteligencja, uczenie głębokie, zbiory danych obrazów medycznych