Clear Sky Science · pl
StatLLM: Zestaw danych do oceny wydajności dużych modeli językowych w analizie statystycznej
Dlaczego to ma znaczenie dla codziennych użytkowników danych
W miarę jak narzędzia sztucznej inteligencji, takie jak asystenci konwersacyjni, stają się elementem codziennej pracy, coraz więcej osób zleca im przetwarzanie liczb, przeprowadzanie eksperymentów i analizę danych. Gdy jednak AI generuje kod do badania statystycznego — na przykład, by sprawdzić, czy nowe leczenie medyczne działa, lub analizować dane dotyczące wyników szkół — skąd mamy wiedzieć, że wykonała zadanie poprawnie? W tym artykule przedstawiono StatLLM, publiczny zestaw danych stworzony do testowania, jak dobrze duże modele językowe radzą sobie z realistycznymi zadaniami analizy statystycznej, dając badaczom i praktykom wyraźniejszy obraz tego, kiedy można ufać kodowi wygenerowanemu przez AI — a kiedy zachować ostrożność.
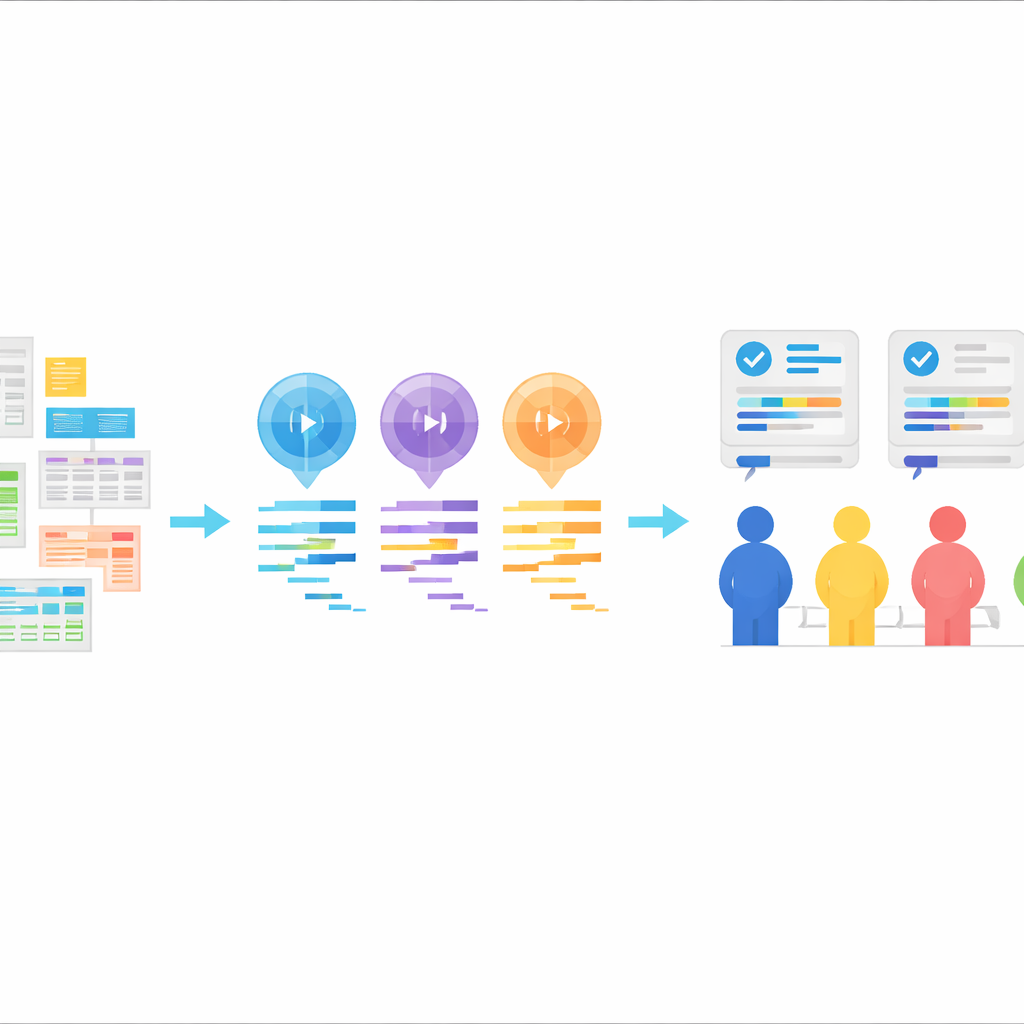
Nowe pole testowe dla kodu statystycznego pisanego przez AI
Rdzeniem StatLLM jest starannie złożony zbiór 207 zadań analizy statystycznej, opartych na 65 rzeczywistych zestawach danych pochodzących z dziedzin takich jak edukacja, medycyna, biznes, finanse, inżynieria i sport. Każde zadanie zawiera opis problemu w języku potocznym, szczegółowe objaśnienie zestawu danych i jego zmiennych oraz krótki fragment kodu SAS napisanego i sprawdzonego przez ekspertów. Zadania obejmują materiały, które mógłby opanować dobry student studiów licencjackich lub magisterskich ze statystyki: od prostych podsumowań danych i wykresów po regresję, analizę przeżycia i bardziej zaawansowane metody. Zapewnia to realistyczny test w kontekście dydaktycznym i przemysłowym, sprawdzający, czy narzędzia AI potrafią rozumieć praktyczne pytania i przekładać je na poprawne kroki analityczne.
Pozwolić AI napisać kod, a potem ocenić jego pracę
Wykorzystując te zadania, autorzy poprosili trzy duże modele językowe — GPT-3.5, GPT-4 oraz Llama‑3.1 70B — o wygenerowanie kodu SAS. Każdy model otrzymał te same składniki: opis zadania, opis zestawu danych, właściwy plik z danymi oraz wyraźne polecenie wygenerowania kodu SAS. Modele użyto w trybie „zero-shot”, co oznacza, że nie pokazywano im wcześniej przykładów poprawnego kodu SAS. Ich odpowiedzi zostały oczyszczone tak, by pozostał tylko kod, bez wyjaśnień. Taka konfiguracja naśladuje powszechny wzorzec z życia: użytkownik opisuje, czego chce, AI zwraca kod, a ten kod jest uruchamiany w pakiecie statystycznym.
Ludzie-eksperci jako złoty standard
Aby sprawdzić, jak dobry był rzeczywiście kod napisany przez AI, zespół zorganizował rygorystyczną ocenę ludzką. Dziewięciu doświadczonych użytkowników SAS utworzyło trzy grupy, z których każda koncentrowała się na innym aspekcie wydajności: czy sam kod był logicznie poprawny i czytelny, czy faktycznie uruchamiał się bez błędów oraz czy uzyskane wyniki odpowiadały jasno i trafnie na oryginalne pytanie. Dla każdego zadania programy SAS wygenerowane przez trzy modele zostały przemieszane, aby oceniający nie wiedzieli, który model stworzył dany kod. Przyznawano oceny w pięciopunktowej skali i łączono je w wynik całkowity, co daje niuansowany obraz mocnych i słabych stron w setkach par model–zadanie. Te eksperckie oceny są teraz dostępne obok całego kodu i zadań w zestawie StatLLM.
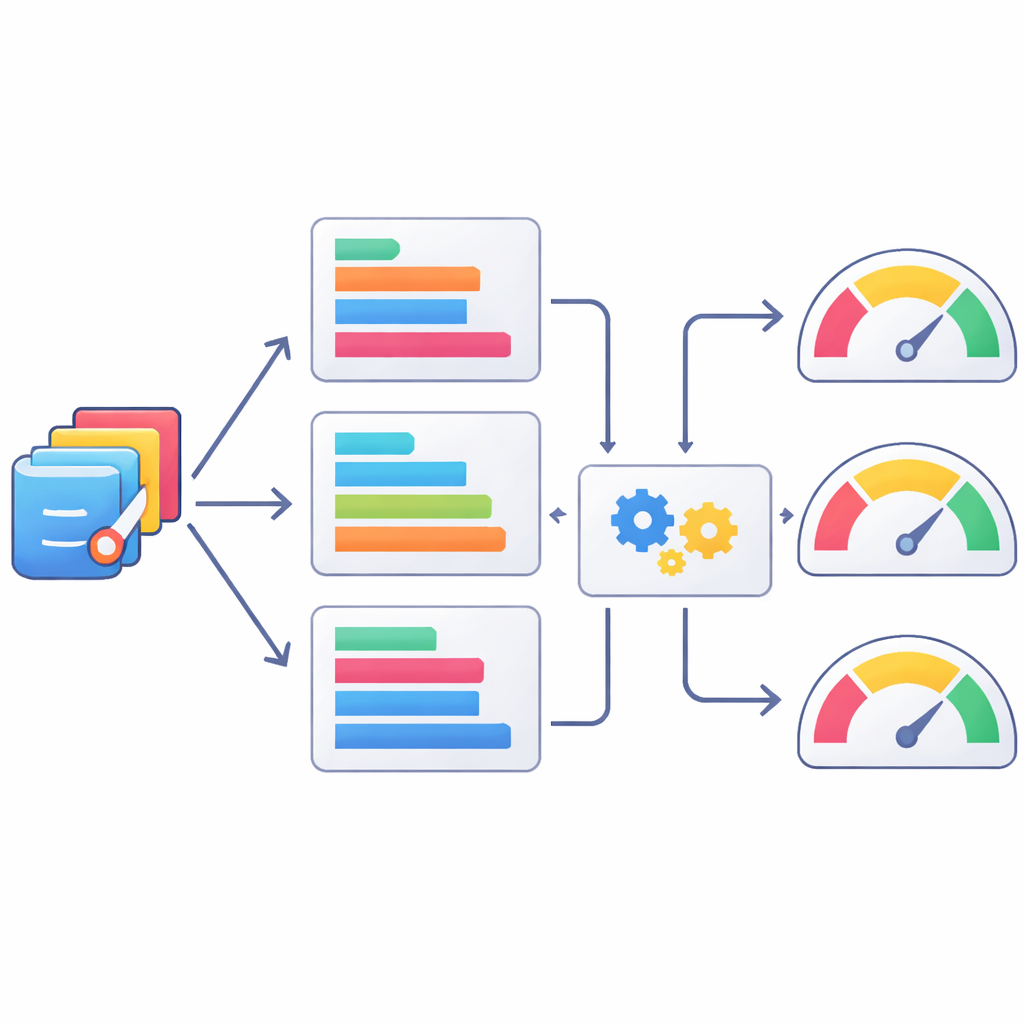
Uczenie maszyn, by oceniał kod jak ludzie
Ponieważ ocena ludzka jest powolna i kosztowna, autorzy zbadali także, jak dobrze automatyczne metryki tekstowe mogą służyć jako przybliżeniowy osąd jakości kodu statystycznego. Porównali programy SAS wygenerowane przez AI z wersjami zweryfikowanymi przez ludzi, używając zestawu dobrze znanych miar z przetwarzania języka naturalnego, a następnie sprawdzili, jak te miary korelują z ocenami ludzkimi. Niektóre metryki, jak warianty miary ROUGE śledzące nakładanie się krótkich sekwencji tokenów, korelowały lepiej z ocenami ekspertów niż inne, ale wszystkie były tylko umiarkowanie powiązane. Zespół posunął się dalej, trenując modele uczenia maszynowego do przewidywania ocen ludzkich na podstawie kombinacji tych metryk. Metody takie jak XGBoost poprawiły zgodność z ocenami ekspertów, lecz wciąż pozostawały daleko od idealnego odwzorowania oceny specjalistycznej, podkreślając, że automatyczne miary są co najwyżej częściowymi substytutami.
Budowanie przyszłych narzędzi statystycznych napędzanych przez AI
Ponad samym benchmarkiem, autorzy pokazują, jak StatLLM może wspierać nowe narzędzia i kierunki badań. Ponieważ każde zadanie jest opisane w ogólnych kategoriach, te same problemy można użyć do testowania generowania kodu w innych językach, takich jak R czy Python, a nawet do łączenia kodu z kilku języków. W artykule podkreślono podejścia zespołowe (ensemble), które mogłyby łączyć różne rozwiązania generowane przez AI dla większej niezawodności, oraz zaprezentowano prototyp aplikacji R Shiny, w której użytkownicy przesyłają zestaw danych i opis zadania, a system AI automatycznie generuje i uruchamia kod R. StatLLM zapewnia też platformę do projektowania i testowania kolejnej generacji oprogramowania statystycznego, które rozumie polecenia w języku naturalnym, przy jednoczesnym trzymaniu się jasnych, mierzalnych standardów.
Co to oznacza dla korzystania z AI w analizie danych
Dla osób niebędących specjalistami najważniejsze przesłanie jest takie, że AI potrafi już generować krótkie fragmenty kodu statystycznego — ale niezawodność daleka jest od gwarantowanej, szczególnie w przypadku zadań wykraczających poza proste przykłady. StatLLM oferuje przejrzysty, wielokrotnego użytku sposób oceniania, jak radzą sobie różne modele, poprawiania automatycznych kontroli ich pracy i projektowania bezpieczniejszych, bardziej odpornych narzędzi analizy danych. W miarę pojawiania się nowszych modeli językowych można je podłączać do tego żywego benchmarku, dzięki czemu pole pozostaje uczciwe co do tego, co AI potrafi, a czego jeszcze nie potrafi w poważnej pracy statystycznej.
Cytowanie: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Słowa kluczowe: duże modele językowe, analiza statystyczna, ocena kodu, zestaw danych benchmarkowych, programowanie w SAS