Clear Sky Science · pl
Zbiór danych cytowań naukowych w decyzjach Urzędu Patentowego USA
Dlaczego cytowania patentowe mają znaczenie dla codziennych innowacji
Kiedy słyszysz o nowym gadżecie, leku czy technologii czystej energii, zazwyczaj stoi za tym ślad pomysłów. Duża część tego śladu jest zapisana w patentach i dokumentach, które one cytują. Ten artykuł przedstawia duży, nowy zbiór danych, który ujawnia — w nietypowo szczegółowy sposób — na które prace naukowe powołują się egzaminatorzy patentowi, decydując, czy wynalazek zasługuje na ochronę. Otwierając to ukryte okno na proces egzaminacyjny, autorzy dają badaczom, decydentom i ciekawym obywatelom nowy sposób badania, jak wiedza naukowa napędza innowacje w rzeczywistości.
Ukryta warstwa w procesie patentowym
Większość badań nad patentami opiera się wyłącznie na cytowaniach widocznych na pierwszej stronie przyznanych patentów. Te listy wydają się proste, ale są wynikiem złożonej wymiany między wnioskodawcami a egzaminatorami państwowymi. W toku tego procesu egzaminatorzy wysyłają formalne pisma zwane Office Actions, w których wyjaśniają, dlaczego patent powinien zostać przyjęty lub odrzucony i odwołują się do wcześniejszych prac, które uznają za istotne. Wiele z cytowanych pozycji, zwłaszcza artykułów naukowych, nigdy nie pojawia się w ostatecznym patencie. Do teraz były one trudne do masowego pozyskania, co sprawia, że badania w dużej mierze ignorowały to bogate źródło informacji o tym, jak decyzje są faktycznie podejmowane.
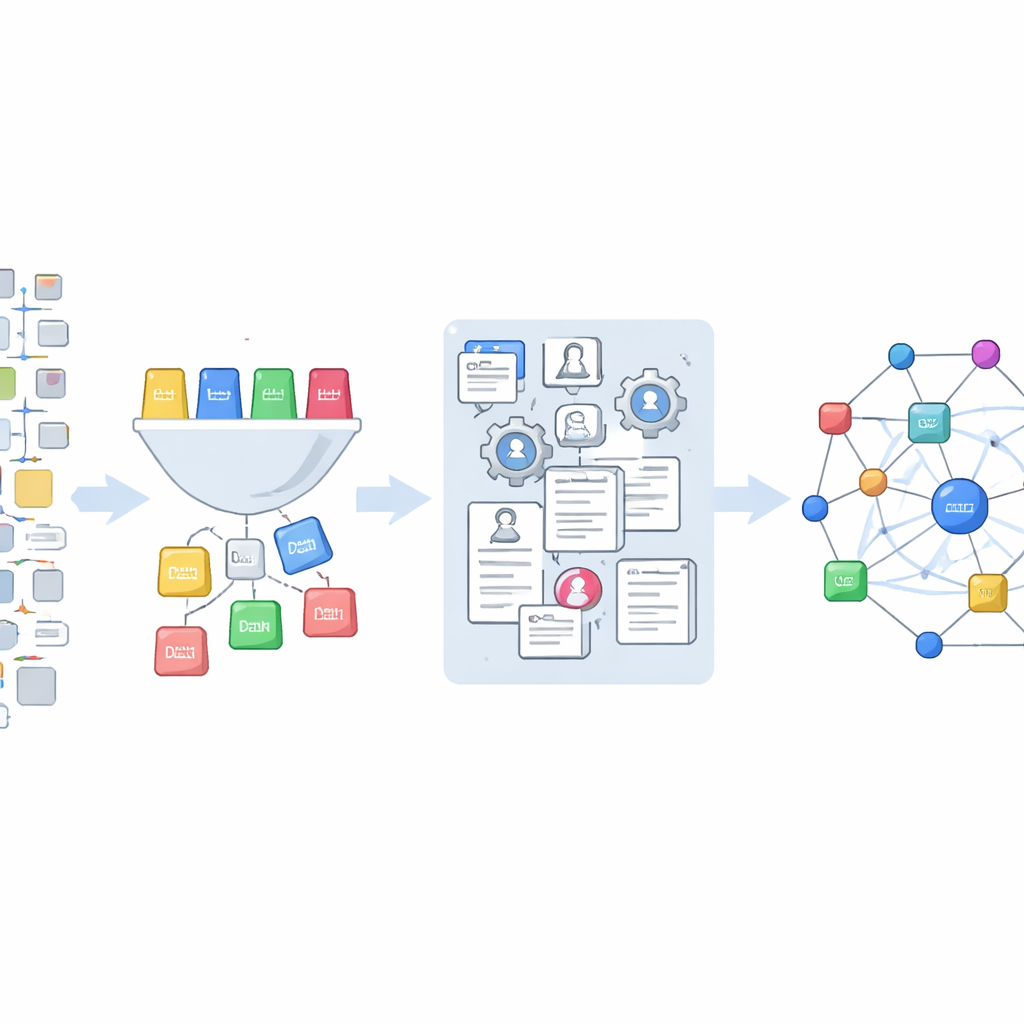
Budowanie nowej mapy na podstawie Office Actions
Autorzy korzystają z repozytorium danych Office Action udostępnionego przez Urząd Patentowy i Znaków Towarowych USA oraz hostowanego w Google Cloud. Z milionów odwołań wydzielają około 850 000, które nie wskazują na inne patenty, lecz na źródła zewnętrzne, takie jak artykuły czasopismowe, książki, strony internetowe i instrukcje produktowe. Projektują schemat z 14 codziennymi kategoriami — od książek i materiałów konferencyjnych po strony WWW i dokumentację produktów — a następnie trenują model uczenia maszynowego, aby przyporządkowywał każde cytowanie do jednego z tych typów. Model, udoskonalany przy użyciu przykładów oznaczonych z pomocą zaawansowanego systemu językowego, klasyfikuje prawie 847 000 unikalnych ciągów cytowań.
Z nieporządnych odwołań do uporządkowanych rejestrów badań
Identyfikacja, które cytowania mają charakter naukowy, to dopiero pierwszy krok. Źródła z rzeczywistości są nieporządne: tytuły mogą być niepełne, lata wpisane błędnie, numery stron pomieszane. Aby przekształcić ten splot w użyteczne dane, zespół wprowadza surowe ciągi do wyspecjalizowanego narzędzia, które rozbija je na elementy takie jak autor, rok, czasopismo i zakres stron, stosując przy tym staranne reguły czyszczenia. Następnie dopasowują te oczyszczone rekordy do OpenAlex, dużej otwartej bazy publikacji naukowych, używając dwóch strategii. Gdy dostępny jest tytuł, wyszukują po tytule i zachowują tylko dopasowania o wysokim poziomie ufności; gdy tytułu brak, polegają na kombinacjach nazwisk autorów, czasopisma, roku i stron. Jeśli OpenAlex nie znajduje dopasowania, sięgają do Crossref, innego głównego źródła identyfikatorów publikacji, i wracają do OpenAlex, wykorzystując odkryte identyfikatory obiektów cyfrowych (DOI).
Jak wiarygodny jest nowy zbiór danych?
Ponieważ zasób ten ma stanowić podstawę przyszłych badań, autorzy poświęcają znaczące wysiłki na testowanie jego dokładności. Ich klasyfikator przypisuje odniesienia do właściwego typu poprawnie w około 92 procentach przypadków ogółem, a zwłaszcza dobrze radzi sobie z najczęstszymi klasami, takimi jak artykuły czasopismowe i patenty. W kroku dopasowywania ręczne kontrole pokazują, że wyszukiwania oparte na tytule stają się bardziej trafne wraz ze wzrostem wyniku dopasowania, osiągając najwyższe wartości w połowie–90. percentyla w najlepszej grupie, podczas gdy wyszukiwania oparte na szczegółowych metadanych są poprawne w 99 procentach przypadków w próbie. Krzyżowe sprawdzenia rekordów odzyskanych przez Crossref również wykazują niemal doskonałą zgodność. Autorzy są otwarci co do słabszych punktów — takich jak rzadkie kategorie, np. prace magisterskie czy raporty techniczne — i zachęcają użytkowników do ich udoskonalania tam, gdzie to potrzebne.
Nowe sposoby badania, jak nauka napędza technologię
Gotowy zbiór danych łączy w przybliżeniu 265 000 odniesień naukowych z Office Actions z pojedynczymi wnioskami patentowymi w USA oraz z rozbudowanymi rekordami publikacji w OpenAlex. Umożliwia to badaczom stawianie nowych pytań: Na ile różne grupy egzaminatorów lub obszary technologii opierają się na artykułach naukowych? Które badania są uznawane za ważne podczas egzaminacji, ale zanikają w ostatecznym patencie? Czy porzucone patenty opierają się na innej części dorobku naukowego niż te udane? Ponieważ cały kod i dane są udostępnione otwarcie, inni mogą dostosowywać narzędzia, rozszerzać zasięg i udoskonalać klasyfikacje. Mówiąc prosto, praca ta przekształca niejasny i rozproszony zbiór dokumentów prawnych w przejrzystą, wielokrotnego użytku mapę tego, jak nauka i technologia spotykają się w systemie patentowym.
Cytowanie: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
Słowa kluczowe: cytowania patentowe, decyzje urzędowe, literatura naukowa, dane o innowacjach, OpenAlex