Clear Sky Science · pl
Zestaw danych do rozpoznawania nazwanych bytów w języku chińskim dla niematerialnego dziedzictwa kulturowego
Dlaczego ochrona żywych tradycji wymaga inteligentnego czytania
Na całym świecie żywe tradycje — takie jak muzyka ludowa, rękodzieło czy lokalne festiwale — grożą zaniknięciem w codziennym życiu. W Chinach istnieją ogromne zasoby tekstów opisujących te praktyki, lecz większość z nich znajduje się na długich stronach internetowych, które dla ludzi — a także komputerów — są trudne do przeszukania i analizy. Niniejsze badanie przedstawia starannie przygotowany zbiór danych w języku chińskim oraz zaawansowany model sztucznej inteligencji, które potrafią automatycznie wyłapać kluczowe informacje w tych tekstach, takie jak nazwy rzemiosł, mistrzów, materiały czy miejsca. Razem stanowią nowe narzędzia wspierające zachowanie i badanie niematerialnego dziedzictwa kulturowego w skali cyfrowej.
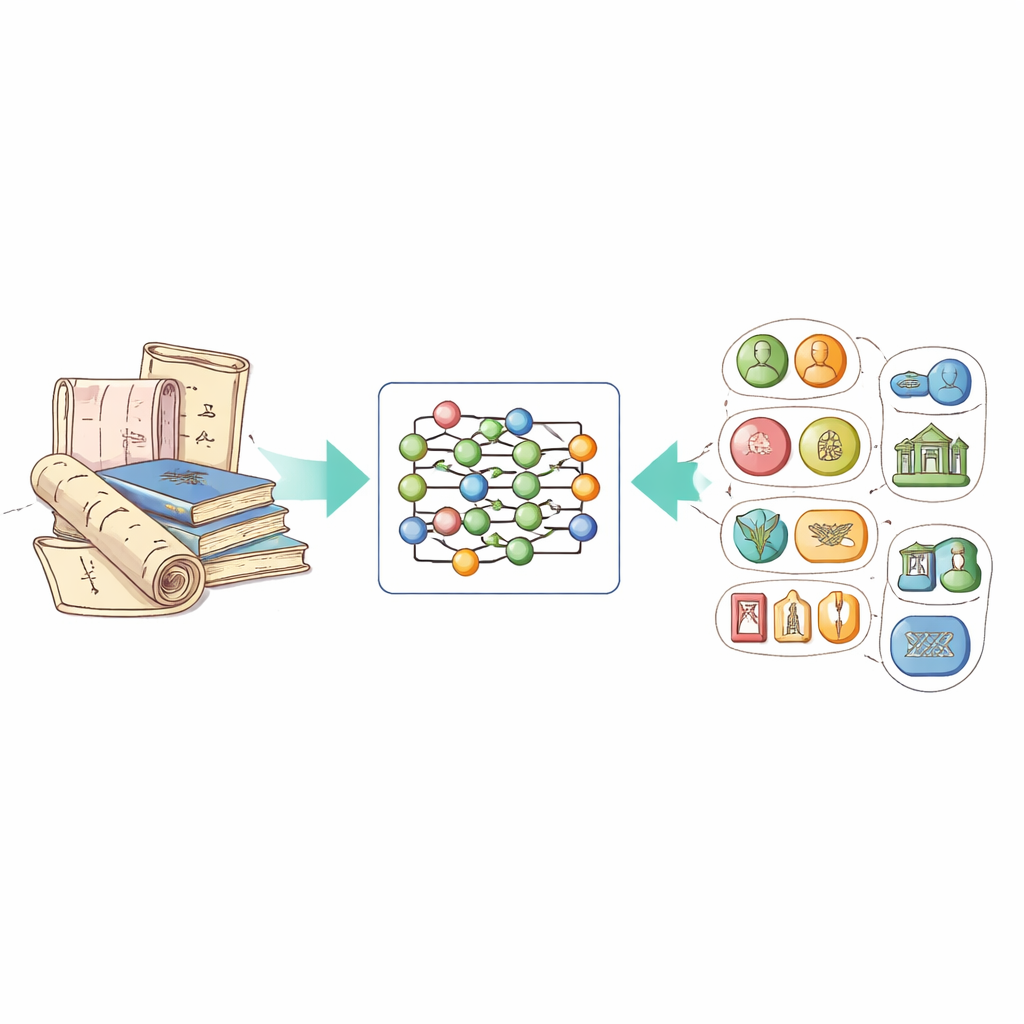
Przekształcanie nieuporządkowanego tekstu w uporządkowaną wiedzę
Główną ideą pracy jest technologia zwana rozpoznawaniem nazwanych bytów, która uczy komputery wyróżniać ważne elementy w tekście: ludzi, miejsca, czasy, organizacje i inne. W kontekście niematerialnego dziedzictwa oznacza to także rozpoznawanie specyficznych typów bytów, takich jak nazwy projektów dziedzictwa, konkretne techniki rzemieślnicze czy używane materiały. Problem polega na tym, że dotąd nie było publicznie dostępnego zbioru danych dostosowanego do tej domeny w języku chińskim, a systemy ogólnego przeznaczenia miały trudności z barwnymi opisami, poetyckim językiem i wyrażeniami regionalnymi występującymi w dokumentach o dziedzictwie.
Budowanie ukierunkowanego zbioru tekstów o dziedzictwie
Aby wypełnić tę lukę, autorzy zgromadzili nowy zbiór danych, nazwany ICH-NER, pochodzący z oficjalnej chińskiej Sieci Niematerialnego Dziedzictwa Kulturowego. Skupili się na wpisach związanych z rzemiosłem — takich jak tradycyjne tekstylia, ceramika, metalurgia czy rzeźba — ponieważ opisy te są bogate w szczegóły dotyczące procesów i materiałów. Po usunięciu ogłoszeń i duplikatów opracowali osiem kluczowych kategorii bytów: nazwy elementów dziedzictwa, lokalizacje, osoby, organizacje, okresy czasu, grupy etniczne, materiały i techniki rzemieślnicze. Każdy znak chiński w tekstach został oznaczony prostym kodem wskazującym, czy należy do bytu, a jeśli tak, to jakiego typu. W sumie zbiór danych zawiera 7 779 próbek i ponad 21 000 oznaczonych bytów, co czyni go solidnym punktem odniesienia dla przyszłych badań.
Dokładne zasady dla spójnego oznaczania
Ponieważ nie istniał standardowy system klasyfikacji dla tego typu tekstów o dziedzictwie, badacze najpierw opracowali szczegółowe wytyczne oparte na krajowych listach dziedzictwa i oficjalnych opisach. Przeprowadzili fazę pilotażową, aby rozstrzygnąć trudne przypadki, takie jak miejsca będące jednocześnie częścią nazw projektów, czy zagnieżdżone frazy, gdzie jeden byt występuje wewnątrz innego. Pojedynczy przeszkolony adnotator oznaczył następnie cały zbiór, korzystając z oprogramowania open-source, wielokrotnie przeglądając wcześniejsze etapy, by skorygować niespójności. Końcowe dane zostały podzielone na zbiory treningowe i deweloperskie, z zachowaniem podobnych proporcji każdego typu bytu oraz dobrego miksu terminów regionalnych i stylów pisania w obu częściach.
Projektowanie modelu AI dostrojonego do języka dziedzictwa
Wraz ze zbiorem danych badanie proponuje wyspecjalizowany model rozpoznawczy łączący kilka nowoczesnych komponentów AI. Najpierw potężny enkoder językowy (RoBERTa) przekształca znaki chińskie w kontekstowe reprezentacje numeryczne odzwierciedlające, jak słowa są używane w otaczającym tekście. Następnie moduł sieci Kolmogorowa–Arnolda uczy się subtelnych, nieliniowych wzorców — na przykład tego, jak pewne materiały zwykle łączą się z określonymi technikami czy regionami. Warstwa wielogłowej uwagi bada relacje w całym zdaniu z różnych perspektyw, a na końcu warstwa dekodująca wybiera najbardziej prawdopodobną sekwencję tagów bytów. Ta architektura została zaprojektowana do obsługi długich, złożonych zdań pełnych metafor i wielowarstwowych odniesień kulturowych.
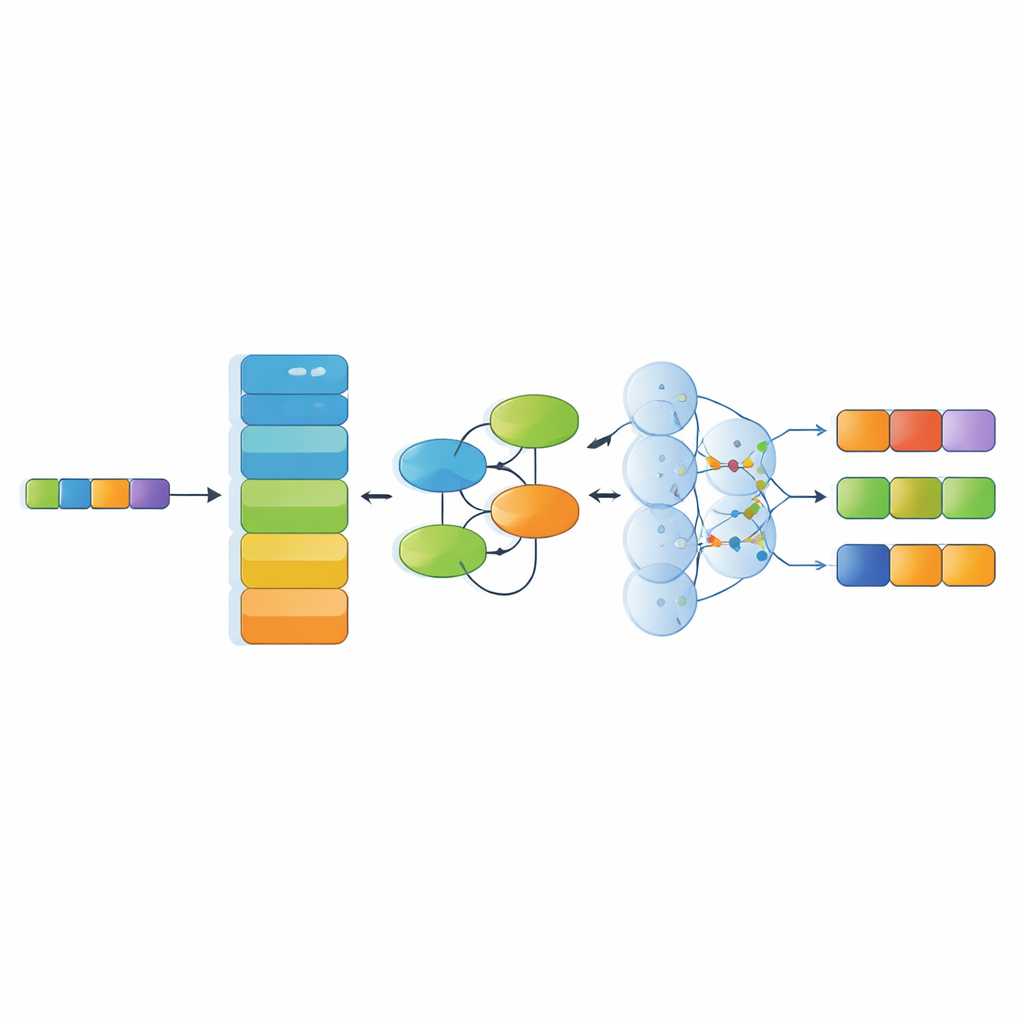
Jak dobrze system rozumie teksty o dziedzictwie
Autorzy porównali swój model z kilkoma silnymi punktami odniesienia powszechnie stosowanymi w badaniach językowych, w tym systemami opartymi na sieciach rekurencyjnych, strukturach kratowych dla tekstu chińskiego oraz niedawną metodą traktującą byty jako segmenty dopracowywane krok po kroku. Na zbiorze ICH-NER metody wykorzystujące nowoczesne wstępnie wytrenowane modele językowe zdecydowanie przewyższały starsze podejścia. Ich złożony system RoBERTa–KAN–uwaga–dekoder osiągnął najlepszą ogólną równowagę precyzji i czułości, szczególnie w wymagających kategoriach, takich jak materiały, organizacje i techniki rzemieślnicze, gdzie dane są stosunkowo skąpe, a opisy często złożone lub niejednoznaczne.
Co to oznacza dla żywej kultury w erze cyfrowej
W praktyce nowy zbiór danych i model ułatwiają komputerom wychwytywanie kto, co, gdzie i kiedy w bogatych opisach tradycyjnych rzemiosł. Taka ustrukturyzowana informacja może zasilać grafy wiedzy, interaktywne mapy czy narzędzia wyszukiwania, które pomagają badaczom, kuratorom i publiczności badać, jak rozprzestrzeniają się techniki, jak pewne rodziny lub regiony kształtują rzemiosło oraz jak praktyki ewoluują w czasie. Choć praca ma charakter techniczny, jej wpływ jest ludzki: oferuje sposób przekształcenia rozproszonych, tekstowo ograniczonych opisów żywych tradycji w uporządkowaną wiedzę, która lepiej wspiera zachowanie i zrozumienie niematerialnego dziedzictwa kulturowego.
Cytowanie: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Słowa kluczowe: niematerialne dziedzictwo kulturowe, rozpoznawanie nazwanych bytów, przetwarzanie języka chińskiego, zbiory danych kulturowych, cyfrowa ochrona