Clear Sky Science · pl
W kierunku zautomatyzowanego raportowania: zbiór raportów z bronchoskopii w celu usprawnienia multimodalnych modeli językowych dużej skali
Mądrzejsza pomoc dla lekarzy pulmonologów
Gdy lekarze patrzą do wnętrza dróg oddechowych przy pomocy malutkiej kamerki, dowiadują się wiele o płucach pacjenta — ale przekształcenie tego, co widzą, w klarowne, szczegółowe raporty wymaga czasu i doświadczenia. W tym badaniu przedstawiono nowy, starannie zbudowany zbiór prawdziwych obrazów z bronchoskopii i raportów, zaprojektowany tak, by nauczyć zaawansowane systemy AI, jak pomagać przy tworzeniu takich opisów. Dla pacjentów może to w przyszłości oznaczać szybsze, bardziej spójne raporty i mniejsze ryzyko pominięcia istotnych szczegółów.
Dlaczego badanie wnętrza płuc ma znaczenie
Bronchoskopia to zabieg, w którym cienka rurka z kamerą jest wprowadzana do dróg oddechowych, aby obejrzeć tchawicę i rozgałęziające się oskrzela. Pomaga lekarzom wykrywać problemy takie jak zapalenie, infekcja, guzy czy krwawienie, a także może prowadzić do zabiegów, np. usuwania ciał obcych lub zakładania drobnych stentów utrzymujących drożność dróg oddechowych. Po badaniu lekarz musi opisać zaobserwowane zmiany w formalnym raporcie, który trafia do dokumentacji medycznej pacjenta i wpływa na decyzje terapeutyczne. Pisanie tych raportów to praca wymagająca szczegółowości i powtarzalności, w dużej mierze zależna od szkolenia i doświadczenia lekarza.
Dlaczego istniejące dane były niewystarczające
W ostatnich latach potężne modele AI zdolne do pracy z obrazami i tekstem poczyniły postępy w odczytywaniu badań obrazowych i tworzeniu szkiców raportów. Jednak w przypadku bronchoskopii dostępne dane używane do trenowania takich systemów były wąskie i niepełne. Wcześniejsze zbiory danych często obejmowały tylko kilka zadań — na przykład wykrywanie guza lub oznaczanie pozycji kamery — pomijając wiele codziennych obserwacji, takich jak wydzielina, łagodne krwawienie czy obrzęk, które lekarze rutynowo opisują. Niektóre zbiory były też prywatne, małe lub skupiały się jedynie na prostych decyzjach „tak/nie”, co sprawiało, że nie nadawały się do uczenia AI tworzącej bogate, ludzkie opisy tego, co pokazuje kamera.
Budowanie bogatszej biblioteki obrazów
Aby wypełnić tę lukę, autorzy stworzyli BERD — nowy zbiór raportów z badań bronchoskopowych zbudowany na podstawie rzeczywistych procedur przeprowadzonych w dużym szpitalu w Chinach. Z 8 477 bronchoskopii wykonanych w latach 2022–2023 wybrano 3 692 reprezentatywne przypadki pacjentów oraz 6 330 kluczowych obrazów, które lekarze oznaczyli jako szczególnie informatywne. Dla każdego obrazu wyszkoleni klinicyści powiązali go z precyzyjnymi pisemnymi opisami tego, co było widoczne, takimi jak guzy, obrzęk, złogi czy prawidłowa tkanka. Gdy obraz nie wykazywał żadnych nieprawidłowości, stosowano prostą standardową frazę, np. „Jest prawidłowe”, by zachować spójność danych. Usunięto dane osobowe, a oryginalne chińskie raporty przetłumaczono na angielski przy użyciu lokalnie uruchomionego modelu językowego w celu ochrony prywatności.
Jak eksperci i AI współpracowali
Ponad zwykłymi opisami zespół chciał też, by każdy obraz był oznaczony jedną lub wieloma kategoriami medycznymi — takimi jak „guz”, „przekrwienie” czy „obrzęk” — tak aby modele AI mogły nauczyć się zarówno etykietować, jak i opisywać zmiany. Aby zrobić to wydajnie, starsi specjaliści od bronchoskopii najpierw zdefiniowali szczegółową listę kategorii opartą na wytycznych medycznych. Lokalnie wdrożony model językowy przeskanował następnie podpisy tekstowe, sugerując, które kategorie pasują do danego obrazu. Eksperci ludzie starannie sprawdzili i poprawili te sugestie, zachowując ostateczną kontrolę nad jakością medyczną. Rezultatem jest precyzyjnie anotowany zasób, w którym każdy obraz powiązany jest z jasnym opisem, lokalizacją anatomiczną i etykietami potwierdzonymi przez ekspertów, wszystko zorganizowane w prostych plikach, których badacze mogą używać bezpośrednio.
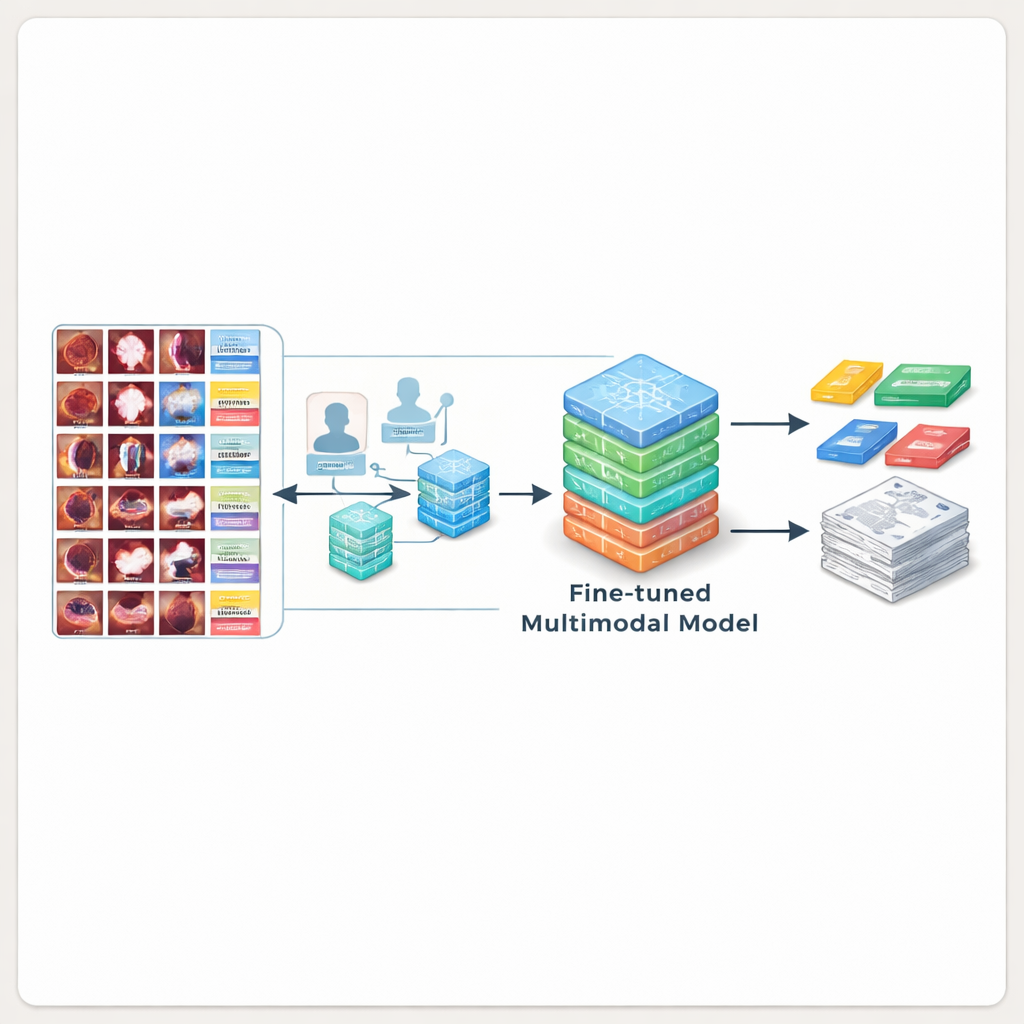
Nauczanie AI lepszego pisania raportów
Aby wykazać użyteczność BERD, badacze użyli go do trenowania kilku wiodących multimodalnych modeli AI. Najpierw przetestowali ogólnego przeznaczenia i medyczne systemy AI, które nigdy wcześniej nie widziały obrazów z bronchoskopii. Modele te często źle interpretowały to, co widziały — pomijały guzy lub dopisywały detale — i wypadały słabo w porównaniu z tekstami napisanymi przez ekspertów. Zespół następnie dopracował modele open-source na obrazach i podpisach z BERD. Po tym dodatkowym treningu najlepszy model generował opisy zgodne z sformułowaniami ekspertów znacznie częściej i w ponad 80% przypadków oceniano je jako akceptowalne przez klinicystów — co oznacza, że tekst wygenerowany przez AI mógł często zostać włączony bezpośrednio do rzeczywistego raportu przy minimalnej edycji.
Co to oznacza dla przyszłej opieki
Mówiąc wprost, ta praca dostarcza brakującej „biblioteki treningowej”, której systemy AI potrzebują, by stać się wiarygodnymi asystentami przy raportowaniu wyników bronchoskopii. Chociaż dane pochodzą z jednego szpitala i niektóre szczegóły liczbowe zostały celowo usunięte, by nie wprowadzać modeli w błąd, zbiór jest publiczny, dobrze udokumentowany i na tyle duży, by ustanowić nowy standard w tej dziedzinie. W miarę jak badacze będą rozwijać BERD, pacjenci mogą w efekcie zyskać szybsze, bardziej jednolite raporty z bronchoskopii, dając lekarzom więcej czasu na podejmowanie decyzji i leczenie zamiast na papierkową robotę.
Cytowanie: Luo, X., Huang, X., Liang, X. et al. Towards Automated Reporting: A Bronchoscopy Report Dataset for Enhancing Multimodality Large Language Models. Sci Data 13, 339 (2026). https://doi.org/10.1038/s41597-026-06692-8
Słowa kluczowe: bronchoskopia, obrazowanie medyczne, raporty kliniczne, multimodalna sztuczna inteligencja, zbiory danych medycznych