Clear Sky Science · pl
Duży zbiór obrazów histologicznych z metadanymi dotyczący mikrośrodowiska raka jelita grubego
Dlaczego ważne jest mapowanie ukrytego sąsiedztwa nowotworu
Kiedy lekarze oglądają pod mikroskopem guz jelita grubego, nie widzą jedynie komórek nowotworowych; widzą tętniące życiem sąsiedztwo tkanki tłuszczowej, komórek odpornościowych, tkanki łącznej i innych elementów. Ta mieszanina typów komórek, nazywana mikrośrodowiskiem guza, silnie wpływa na to, jak pacjent reaguje na leczenie i jak długo przeżywa. Tymczasem systemy komputerowe, które mogłyby pomóc lekarzom zinterpretować te złożone obrazy, były ograniczone prostym problemem: brakowało dobrze oznakowanych obrazów do uczenia. W badaniu przedstawiono jeden z największych i najlepiej opisanych zbiorów obrazów tkanki raka jelita grubego, stworzony specjalnie do trenowania i testowania nowoczesnych systemów sztucznej inteligencji.
Budowanie ogromnej biblioteki obrazów guzów jelita
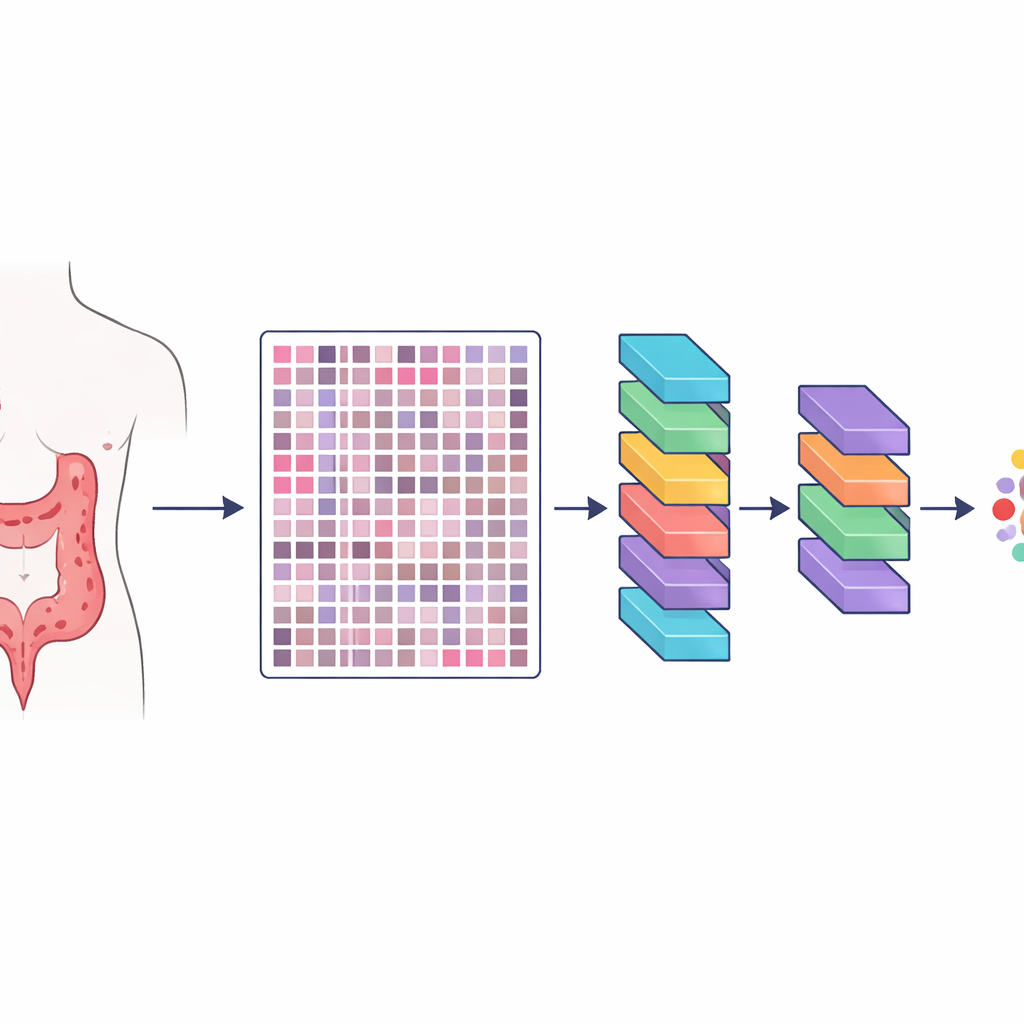
Naukowcy stworzyli zasób o nazwie HMU-CRC-Hist550K, zbudowany z próbek tkankowych od 500 pacjentów leczonych z powodu raka jelita grubego w dużym szpitalu onkologicznym w Chinach. Guzy każdego pacjenta zostały utrwalone, zabarwione w standardowy sposób stosowany w laboratoriach patologii i zeskanowane jako wysokorozdzielcze slajdy cyfrowe. Z tych slajdów zespół automatycznie wycinał małe kwadratowe kafelki obrazu, zbliżone rozmiarem do tego, co patolog mógłby zobaczyć przez mikroskop jednorazowo. W sumie wygenerowano około 550 000 takich kafelków, dając modelom sztucznej inteligencji ogromny i zróżnicowany zestaw przykładów, z którego mogą się uczyć, jak wyglądają różne tkanki.
Staranna ludzka anotacja krajobrazu nowotworu
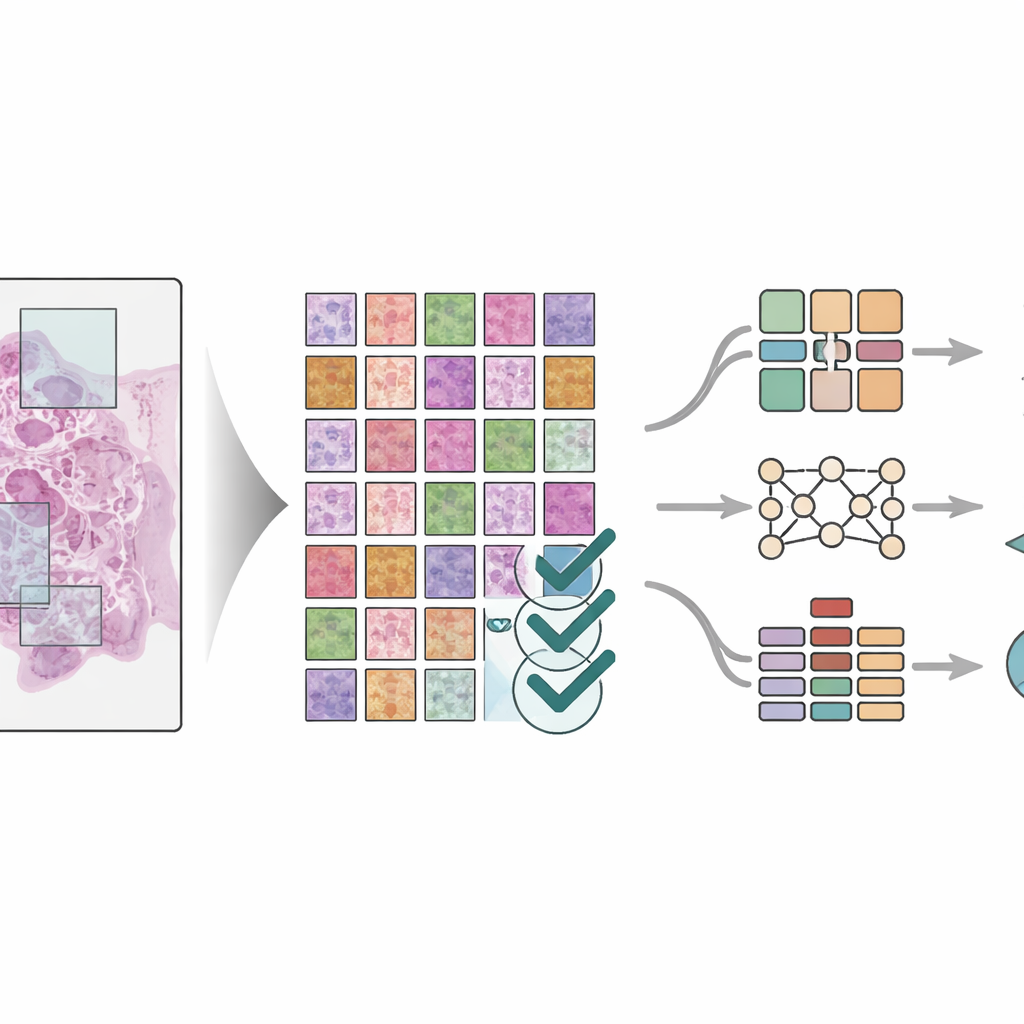
Samo stworzenie dużej biblioteki obrazów nie wystarcza; obrazy muszą być też dokładnie opisane. Trzech doświadczonych patologów pracowało wspólnie w trzyetapowym procesie, aby wyznaczyć osiem kluczowych komponentów otoczenia guza: tkankę tłuszczową, szczątki komórkowe, komórki odpornościowe zwane limfocytami, śluz, mięśniówkę gładką, prawidłowy nabłonek jelita, tkankę łączną wspierającą otaczającą guz oraz same komórki nowotworowe. Dwaj patolodzy najpierw niezależnie wyznaczyli regiony na dużych slajdach, a następnie sprawdzali nawzajem swoje oznaczenia. Starszy specjalista przeprowadził końcowy przegląd, rozstrzygając niezgodności i wyłączając obszary niejednoznaczne. Takie wzajemne sprawdzanie znacznie zmniejszyło wpływ indywidualnych uprzedzeń i wygenerowało wysoce spójne oznaczenia na szczegółowym poziomie, dzięki czemu każdy kafelek jest przypisany do konkretnego typu tkanki w sąsiedztwie guza.
Łączenie widoków z mikroskopu z historiami pacjentów
To, co czyni ten zbiór danych szczególnie wartościowym, to powiązanie obrazów z bogatymi informacjami klinicznymi dla każdego pacjenta. Dla każdego przypadku zespół zebrał podstawowe dane, takie jak wiek i płeć, a także stopień zaawansowania guza, lokalizację wzdłuż jelita grubego i odbytnicy, stopień atypii komórek nowotworowych, czy doszło do zajęcia nerwów lub węzłów chłonnych oraz czas przeżycia po leczeniu. Zarejestrowano również wyniki powszechnych badań laboratoryjnych odzwierciedlających genetyczny i białkowy obraz guza. Wszystkie identyfikatory osobiste zostały usunięte, aby uniemożliwić rozpoznanie pacjentów. Łącząc wzory tkankowe z tymi cechami klinicznymi, badacze mogą badać, jak konkretne układy mikrośrodowiska wiążą się z rzeczywistymi wynikami, takimi jak które grupy pacjentów radzą sobie lepiej lub gorzej.
Wystawienie sztucznej inteligencji na próbę z nowym zbiorem
Aby wykazać użyteczność zbioru danych, naukowcy wytrenowali trzy różne modele uczenia głębokiego — nowoczesne systemy rozpoznawania wzorców, które radzą sobie doskonale z zadaniami obrazowymi — do identyfikacji ośmiu typów tkanki na kafelkach. Zastosowali surowe zasady podziału pacjentów na grupy treningowe i testowe, tak aby modele oceniano na pacjentach, których wcześniej nie widziały. Modele, obejmujące zarówno klasyczne sieci obrazowe, jak i nowszą architekturę „vision transformer”, osiągnęły bardzo wysoką dokładność, z wynikami bliskimi doskonałości na kilku zestawach testowych. Zespół porównał również wyniki z innymi zaawansowanymi metodami segmentacji obrazów i odnotował podobnie silną wydajność. Narzędzia wizualne wykorzystano do podkreślenia fragmentów tkanki, na które modele zwracały uwagę, potwierdzając, że koncentrowały się na medycznie istotnych obszarach, a nie na przypadkowych wzorcach.
Co to oznacza dla przyszłej opieki onkologicznej
Dla osób spoza specjalizacji kluczowy przekaz jest taki, że praca ta nie wprowadza nowego leczenia, lecz stanowi potężną podstawę dla mądrzejszej diagnostyki i prognozowania. Udostępniając dużą, dobrze zorganizowaną i otwarcie dostępną bibliotekę obrazów powiązaną ze szczegółowymi rekordami pacjentów, autorzy umożliwiają badaczom na całym świecie budowanie i porównywanie narzędzi sztucznej inteligencji na tym samym solidnym gruncie. Takie narzędzia mogłyby ostatecznie pomóc patologom szybciej i bardziej konsekwentnie mapować sąsiedztwo guza, przewidywać, którzy pacjenci są w większym ryzyku, oraz sugerować bardziej spersonalizowane strategie leczenia. Chociaż obecne dane obejmują tylko pojedyncze punkty czasowe, a nie zmiany w ciągu miesięcy czy lat, zasób ten jest ważnym krokiem w kierunku wykorzystania patologii cyfrowej i AI do lepszego zrozumienia, a w efekcie lepszego leczenia raka jelita grubego.
Cytowanie: Wang, H., Li, H., Xue, J. et al. Large-Scale Histological Image Dataset with Metadata for Colorectal Cancer Microenvironment. Sci Data 13, 431 (2026). https://doi.org/10.1038/s41597-026-06675-9
Słowa kluczowe: rak jelita grubego, mikrośrodowisko guza, patologia cyfrowa, uczenie głębokie, zestaw danych obrazów medycznych