Clear Sky Science · pl
Szacowanie percentylowego rangu wykształcenia na poziomie społeczności w Chinach przy użyciu wieloźródłowych big data i uczenia maszynowego
Dlaczego poziom wykształcenia w twoim sąsiedztwie ma znaczenie
Miejsce, w którym mieszkamy, kształtuje szkoły, do których chodzą nasze dzieci, bezpieczeństwo ulic i nawet wartość naszych domów. Jednak w Chinach podstawowe informacje o tym, jak wykształcone są różne dzielnice, przez długi czas były trudno dostępne. To badanie zmienia ten stan rzeczy, wykorzystując zdjęcia satelitarne, fotografie uliczne i zaawansowane algorytmy komputerowe do oszacowania względnego poziomu wykształcenia w ponad 120 000 społecznościach w całym kraju, oferując nowe spojrzenie na nierówności społeczne i życie miejskie.
Wykraczając poza liczbę lat nauki
Większość statystyk porównuje wykształcenie, licząc lata spędzone w szkole. Może to jednak wprowadzać w błąd między pokoleniami. Dyplom ukończenia szkoły średniej kiedyś lokował kogoś wysoko w jego grupie wiekowej; dziś wielu ich dzieci ma dyplomy uniwersyteckie. Autorzy używają zamiast tego „percentylowego rangu wykształcenia”, który pokazuje, na jakiej pozycji dana osoba znajduje się w obrębie własnej kohorty urodzeniowej — od 0 (najmniej wykształcony) do 100 (najbardziej wykształcony). W ten sposób starsza osoba z jedynie wykształceniem średnim i młodsza z tytułem licencjata mogą być uznane za mające podobny status społeczny, jeśli obie plasują się, powiedzmy, w okolicach 70. percentyla swojego pokolenia.
Przekształcanie miejskiego krajobrazu w wskazówki społeczne
Aby odwzorować percentylowe rangi wykształcenia na poziomie społeczności, zespół sięgnął po sześć fal obszernego badania krajowego oraz szeroki zestaw „big data” opisujących zbudowane środowisko. Badano, jakie rodzaje miejsc otaczają każdą dzielnicę — sklepy, szkoły, szpitale, parki i biura — jak gęste są zabudowa i sieć drogowa, jak jasny obszar wygląda nocą ze zdjęć satelitarnych oraz jak wiele osób zwykle się tam pojawia. Z milionów zdjęć ulicznych wykorzystano komputerowe rozpoznawanie obrazów do pomiaru przestrzeni zielonych, chodników, natężenia ruchu, oznak zaniedbania, takich jak śmieci czy graffiti, a także tego, jak zamożna lub bezpieczna wydaje się ulica dla obserwatorów. Uwzględniono też ukształtowanie terenu, takie jak wysokość i nachylenie, ponieważ strome lub odległe obszary często pozostają w tyle z rozwojem. 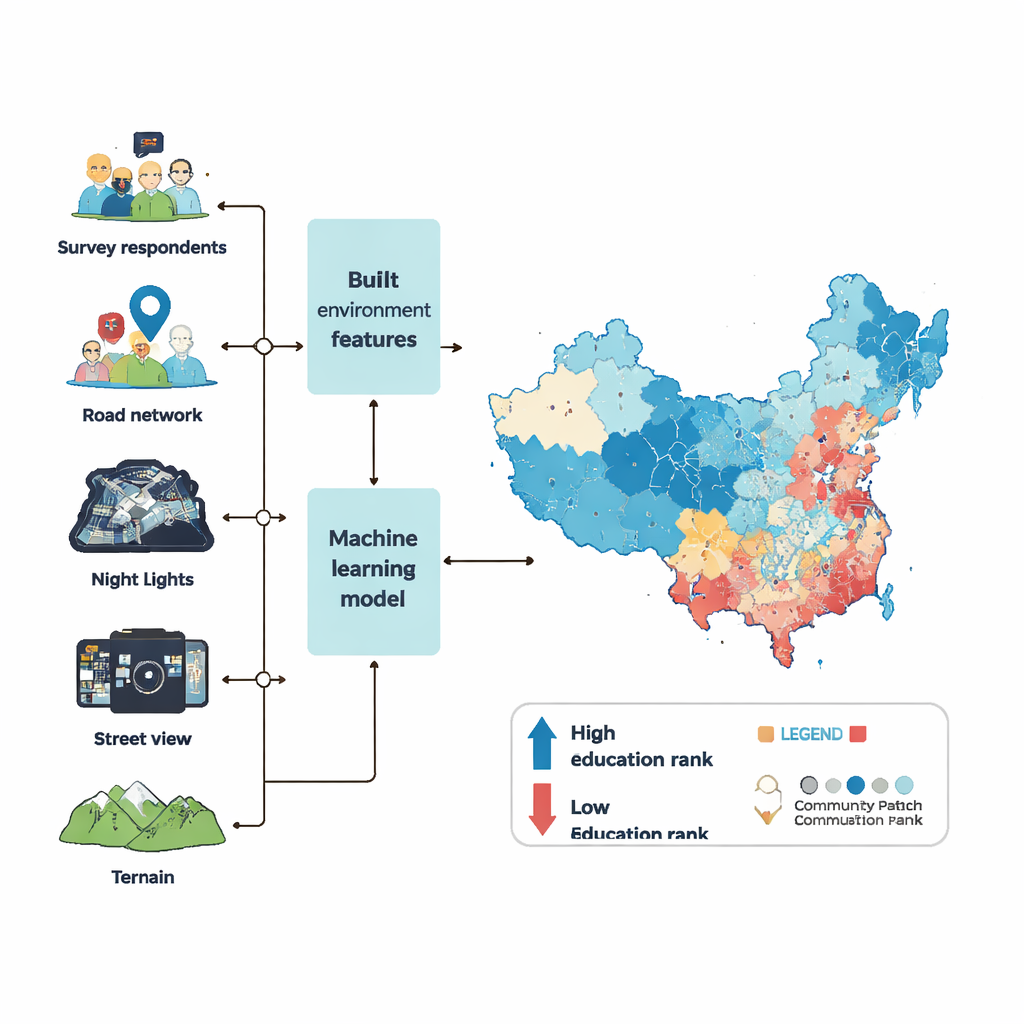
Nauczanie maszyn „czytania” miasta
Z tymi danymi badacze wytrenowali potężny model uczenia maszynowego (zwany XGBoost), aby uchwycić związek między cechami fizycznymi społeczności a średnim percentylowym rangiem wykształcenia jej mieszkańców. Najpierw uzupełnili luki w danych środowiskowych za pomocą starannego statystycznego procesu imputacji, aby brakujące wartości nie zniekształcały wyników. Następnie dostrajali wewnętrzne ustawienia modelu poprzez setki prób optymalizacyjnych, oceniając działanie po tym, jak dobrze model potrafił przewidywać rangi wykształcenia dla społeczności z badań, których wcześniej nie widział. Końcowy model był w stanie wyjaśnić ponad 90 procent różnic między społecznościami w danych testowych, przy niewielkich błędach — co stanowi lepszy wynik niż podobne próby w innych krajach.
Co ujawnia nowa mapa krajowa
Posługując się wytrenowanym modelem, autorzy przewidzieli średnie percentylowe rangi wykształcenia dla 122 126 społeczności w 2020 roku na terenie Chin kontynentalnych, obejmując większość obszarów miejskich i około 85 procent ludności. Centra miast zwykle wyłaniają się jako najlepiej wykształcone, potem następują ośrodki drugorzędne, a dalej odległe przedmieścia, choć każdy metropolia ma swój własny wzór. Historyczne centrum Pekinu, na przykład, nie skupia najwyższych rang, podczas gdy wysoce wykształcone strefy Shenzhen rozłożone są w wielu centrach. Aby sprawdzić wiarygodność, zespół porównał swoje szacunki z oficjalnymi danymi spisowymi oraz z dostępnymi komercyjnymi zapisami usług lokalizacyjnych. Na poziomie prefektury i powiatu obszary z wyższymi przewidywanymi percentylami wykazują też większą liczbę lat nauki w spisie. Na poziomie sąsiedztwa w Pekinie i Kantonie ich mapa zgadza się ściśle zarówno z benchmarkami korporacyjnymi, jak i spisowymi. 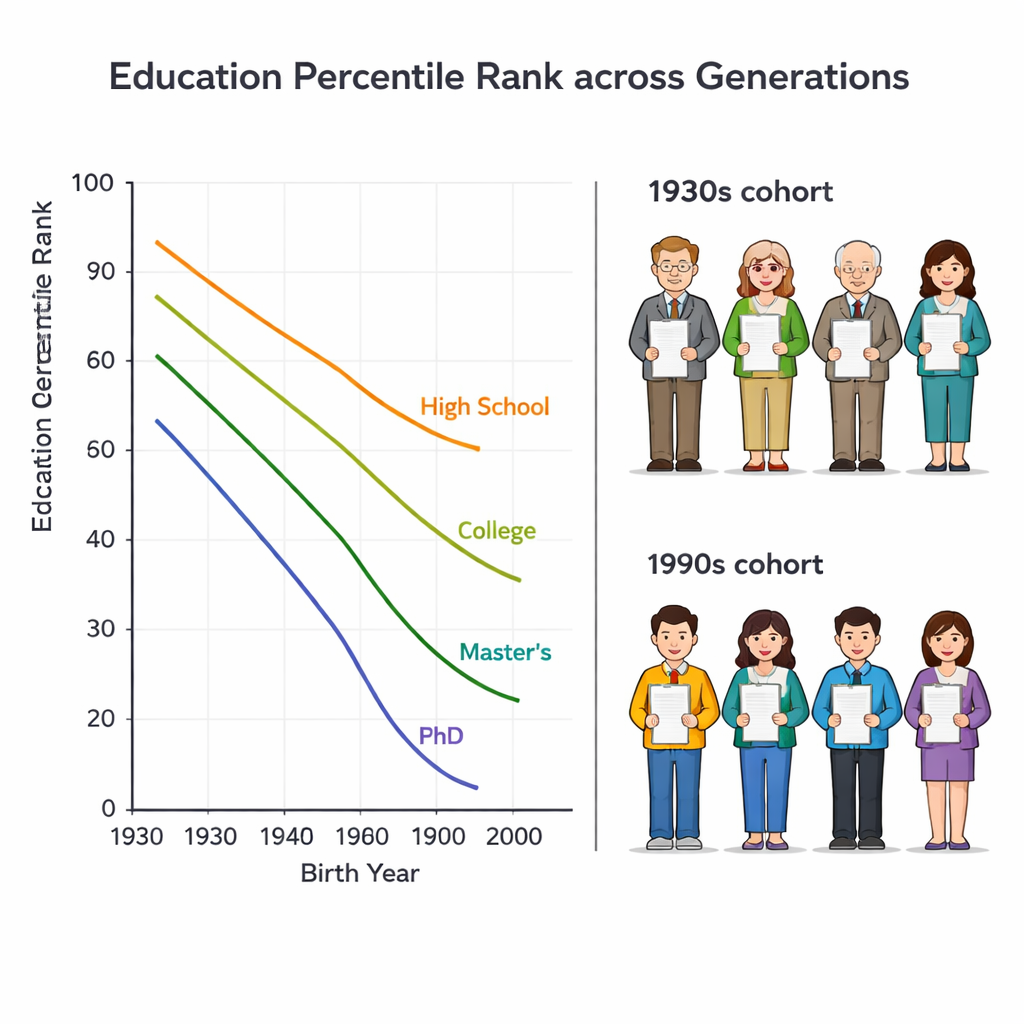
Dlaczego to ma znaczenie w codziennym życiu
Dla decydentów, planistów i badaczy ten nowy otwarty zestaw danych oferuje szczegółowy, aktualny obraz przewag i braków edukacyjnych w chińskich miastach. Może być używany do badania, gdzie formują się enklawy klasy średniej, jak daleko rozprzestrzeniła się gentryfikacja lub które dzielnice mogą potrzebować lepszych szkół, usług społecznych czy transportu publicznego. Dla czytelników niebędących specjalistami główne przesłanie jest proste: poprzez „czytanie” ulic, świateł i budynków w sąsiedztwie nowoczesne narzędzia danych potrafią z zaskakującą precyzją przybliżyć pozycję społeczną jego mieszkańców. Ta praca nie zastępuje tradycyjnych spisów ludności, ale zapewnia szybki, niskokosztowy sposób wypełnienia luk między nimi i lepszego zrozumienia, jak miejsca, które budujemy, odzwierciedlają i utrwalają nasze podziały społeczne.
Cytowanie: Zhang, Y., Pan, Z., You, Y. et al. Community-level education percentile rank estimation in China using multi-source big data and machine learning. Sci Data 13, 304 (2026). https://doi.org/10.1038/s41597-026-06664-y
Słowa kluczowe: nierówności w edukacji, miejskie Chiny, big data, uczenie maszynowe, sąsiedztwa