Clear Sky Science · pl
Zapobieganie cyfrowym grobowcom danych proteomicznych przez wspólną odpowiedzialność i zaangażowanie społeczności
Dlaczego twoje dane medyczne nie powinny trafiać do cyfrowego cmentarza
Współczesna medycyna coraz częściej opiera się na ogromnych zbiorach danych opisujących tysiące białek działających w naszych komórkach. Pliki te często są udostępniane publicznie w sieci z obietnicą, że inni naukowcy będą mogli sprawdzić wyniki lub postawić nowe pytania bez przeprowadzania dodatkowych eksperymentów. Jednak gdy dane są publikowane w mylących formatach, pozbawione istotnych informacji lub zależne od zamkniętego oprogramowania, stają się „grobami danych”: widoczne dla wszystkich, a praktycznie bezużyteczne. Artykuł pokazuje, jak kurs uniwersytecki przemienił studentów w detektywów danych, ujawniając ten ukryty problem — i proponuje proste poprawki, które mogą uczynić udostępnione dane naprawdę nadające się do ponownego wykorzystania.
Nauka przez powtarzanie prawdziwych badań
Na Uniwersytecie Helsińskim studenci studiów magisterskich na kursie proteomiki wykorzystującej spektrometrię mas mieli podjąć ambitne zadanie: wybrać rzeczywiste, publicznie dostępne zestawy danych białkowych z dużego repozytorium i spróbować odtworzyć opublikowane wyniki. Pracując w małych zespołach, pobrali sześć projektów z sieci ProteomeXchange, która gromadzi wyniki spektrometrii mas z wielu laboratoriów na całym świecie. Korzystając ze wspólnego pipeline’u analitycznego w języku R, studenci przeprowadzili te same ogólne kroki co pierwsi autorzy: identyfikowali białka, mierzyli ich obfitość, porządkowali dane i testowali, które białka zmieniają się między warunkami, na przykład między tkanką chorą a zdrową.
Wielkie obietnice, brak instrukcji
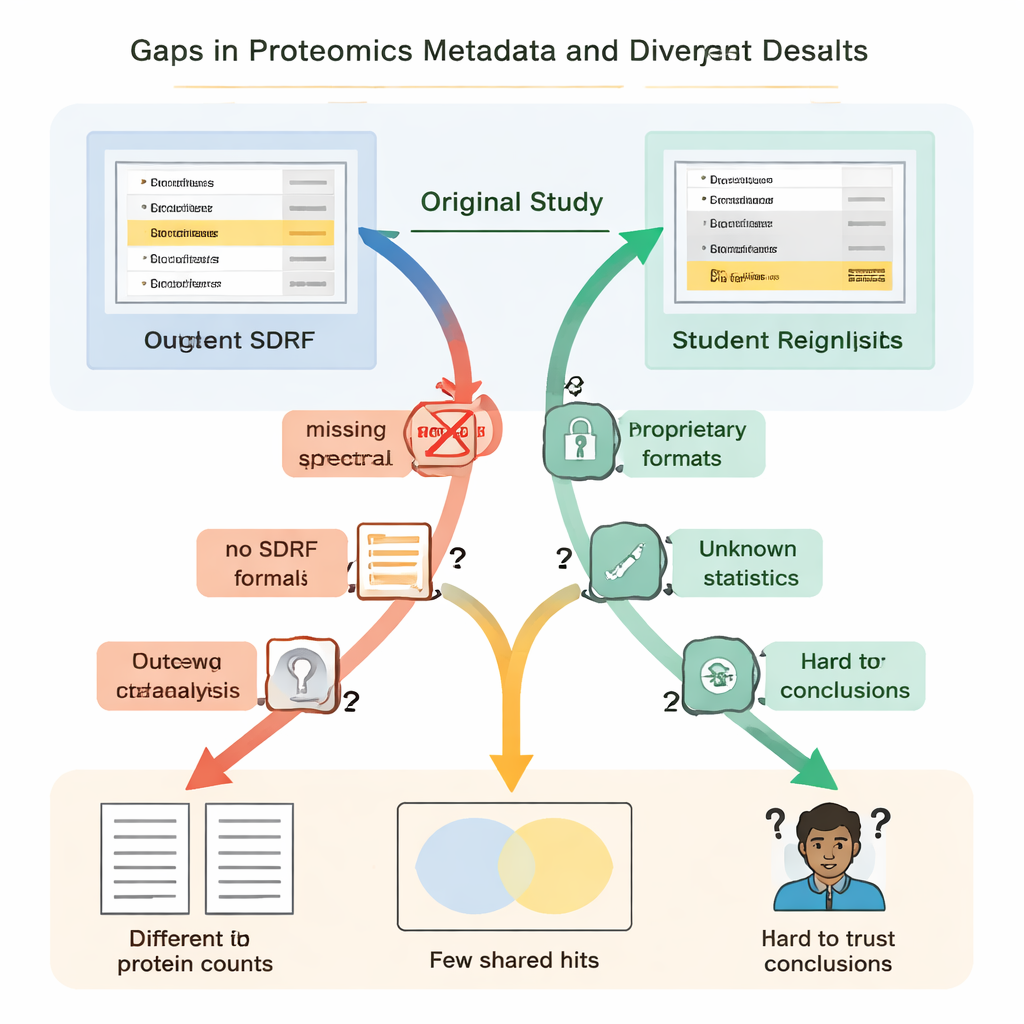
Studenci szybko odkryli, że „otwarte” nie zawsze znaczy „ponownie używalne”. W każdym przypadku brakowało istotnych instrukcji lub były one trudne do znalezienia. Kluczowe powiązania między próbkami a plikami danych nie były opisane w prostym, czytelnym dla maszyn formacie, więc zespoły musiały zgadywać, które surowe pliki odpowiadają którym grupom biologicznym, czytając artykuły i rozszyfrowując nazwy plików. Brakowało informacji o tym, jak kontrolowano fałszywe pozytywy — na przykład o użyciu specjalnych sekwencji „dekoy” białek — co uniemożliwiało rygorystyczną ocenę wiarygodności wykazanych list białek. W kilku projektach główne wyniki były zamknięte w zastrzeżonych formatach plików lub zależały od komercyjnego oprogramowania, do którego studenci nie mieli dostępu, zmuszając ich do odtwarzania dużych części analizy od podstaw.
Gdy drobne braki powodują wielkie różnice
Te brakujące elementy nie były jedynie drobnymi niedogodnościami; prowadziły do dramatycznie odmiennych wyników naukowych. W jednym badaniu nad chorobą nerek autorzy oryginalni zgłosili nieco poniżej pięciu tysięcy białek, podczas gdy reanaliza studentów — używając otwartego narzędzia i własnej biblioteki spektralnej — wykryła ponad trzynaście tysięcy. Białko podkreślone w oryginalnym artykule jako szczególnie istotne nie pojawiało się przekonująco w pliku identyfikacyjnym i w ogóle nie zostało wykryte w przepływie pracy studentów. W innym przypadku oryginalne badanie wykazało 108 białek zmieniających się między warunkami, ale studenci, pracując z tymi samymi surowymi danymi, lecz bez pełnych informacji o zastosowanej statystyce, pewnie wskazali tylko 11. Gdzie indziej brak replikatów biologicznych w przesłanych plikach uniemożliwiał przeprowadzenie prawidłowych testów statystycznych.
Czego naprawdę powinien zawierać „ponownie używalny” zestaw danych
Z tych sześciu studiów przypadków wyłonił się jasny wzorzec: główne przeszkody dla powtarzalności nie wynikały z samych maszyn do spektrometrii mas, lecz z tego, jak wyniki były pakowane i udostępniane. Autorzy argumentują, że każdy zestaw danych proteomicznych powinien być dostarczony z minimalnym pakietem do ponownej analizy. Powinien on zawierać dane surowe wraz z otwartymi, wspólnotowymi formatami wyników; zstandaryzowaną tabelę łączącą każdą próbkę z jej warunkami eksperymentalnymi; podstawowe podsumowania kontroli jakości; wszelkie biblioteki spektralne lub pliki sekwencji białek niezbędne do powtórzenia wyszukiwania; oraz pełne parametry analizy i kod, najlepiej przechowywane razem z wersjonowanymi kontenerami oprogramowania. Repozytoria, czasopisma i recenzenci mogliby pomóc, zachęcając lub wymagając od nadawców dostarczenia takiego pakietu od razu, aby inni nie musieli rekonstruować procedury z porozrzucanych wskazówek.
Szkolenie naukowców i naprawa systemu jednocześnie
Samo zajęcie pełniło podwójną funkcję. Dla studentów było praktycznym sposobem opanowania złożonych metod proteomiki, statystyki i programowania, jednocześnie ujawniając, jak kruche mogą być opublikowane wnioski, gdy dokumentacja jest niekompletna. Dla szerszej społeczności zmagania studentów stanowiły test wysiłku obecnych praktyk udostępniania danych, wskazując dokładnie, gdzie metadane i zapisy analiz zawodzą. Autorzy sugerują, że podobne kursy można organizować gdzie indziej, przekształcając sale wykładowe w silniki kontroli jakości, które nieustannie będą wymagać jaśniejszych, bardziej przejrzystych danych.
Z cyfrowych grobowców do żywych zasobów
Mówiąc wprost, artykuł dochodzi do wniosku, że wiele zestawów danych białkowych zalegających dziś w publicznych repozytoriach grozi staniem się cyfrowymi cmentarzami — kosztownymi eksperymentami, których wyników nie da się wiarygodnie sprawdzić ani rozszerzyć. Rozwiązanie jest jednak stosunkowo proste: traktować metadane, otwarte formaty i udostępnialny kod jako integralne części eksperymentu, a nie dodatek. Jeśli badacze, recenzenci i repozytoria wspólnie będą nalegać na prosty, dobrze udokumentowany pakiet przy udostępnianiu danych proteomicznych, te zestawy danych mogą pozostać „żywe”: gotowe do reanalizy, łączenia z nowymi badaniami i wzmacniania dowodów stojących za odkryciami biomedycznymi.
Cytowanie: Vadadokhau, U., Soliman, M., Castillon, L. et al. Preventing Proteomics Data Tombs Through Collective Responsibility and Community Engagement. Sci Data 13, 287 (2026). https://doi.org/10.1038/s41597-026-06614-8
Słowa kluczowe: proteomika, powtarzalność danych, otwarta nauka, spektrometria mas, udostępnianie danych badawczych