Clear Sky Science · pl
Ekstrakcja relacji i normalizacja pojęć oparta na transformatorach z wykorzystaniem anotowanego korpusu badań klinicznych
Pomaganie lekarzom szybciej odnaleźć właściwych pacjentów
Każde badanie kliniczne wymaga odnalezienia pacjentów spełniających długą listę warunków medycznych, terapii i ram czasowych. Obecnie lekarze często muszą ręcznie przeglądać elektroniczne dokumentacje medyczne i opisy badań, co jest czasochłonne i podatne na błędy. W artykule przedstawiono dużą, starannie sprawdzoną kolekcję hiszpańskich tekstów badań klinicznych oraz pokazano, jak współczesna sztuczna inteligencja może zamienić ten nieuporządkowany język w uporządkowane dane, torując drogę do szybszych, bardziej sprawiedliwych i precyzyjniejszych badań medycznych.
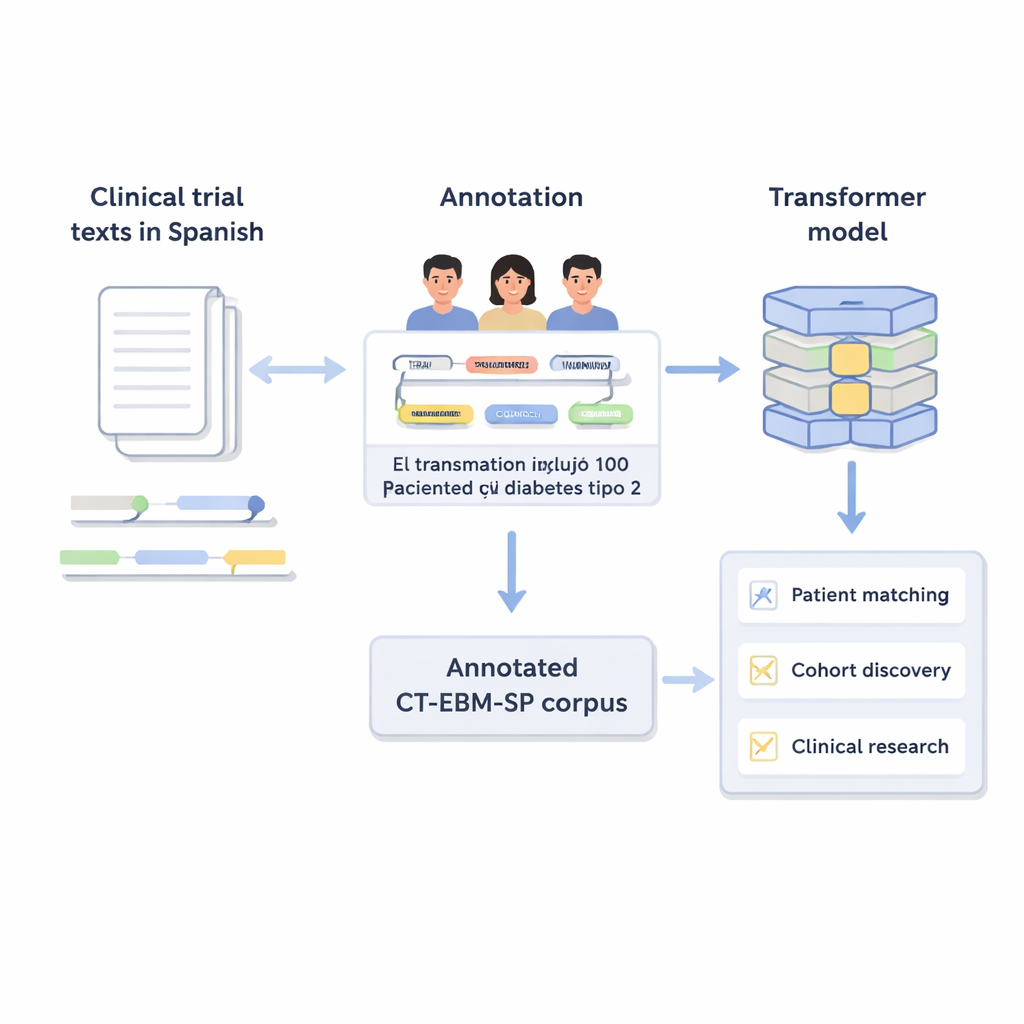
Przekształcanie tekstu swobodnego w uporządkowane informacje
Opisy badań klinicznych określają, kto może, a kto nie może uczestniczyć, używając potocznego języka medycznego: ograniczeń wiekowych, przebyłych chorób, wyników badań laboratoryjnych i stosowanych terapii. Komputery mają trudności z analizą takiego tekstu swobodnego. Autorzy stworzyli wersję 3 korpusu CT‑EBM‑SP — zbiór 1200 hiszpańskich tekstów badań klinicznych zawierających prawie 300 000 słów. Eksperci ludzie przejrzeli te teksty i oznaczyli 23 typy jednostek medycznych, takich jak choroby, leki, wyniki badań i wyrażenia czasu, a także sygnały zaprzeczenia (na przykład „brak przebiegu”) i niepewności. Oznaczono także 11 atrybutów, które uchwycają szczegóły, np. czy zdarzenie miało miejsce w przeszłości czy w przyszłości oraz czy dotyczyło pacjenta czy członka rodziny.
Ujednolicanie terminów medycznych
Istotnym wyzwaniem w medycynie jest to, że ten sam koncept może być zapisany na wiele sposobów. Aby temu zaradzić, zespół powiązał większość oznaczonych jednostek ze znormalizowanymi kodami z Unified Medical Language System (UMLS) — obszernego wielojęzycznego słownika medycznego. Ten etap, zwany normalizacją pojęć, sprawia, że różne pisownie czy sformułowania wskazują ten sam unikalny identyfikator. Przykładowo kilka wariantów „25‑hydroksywitamina D” zostało przypisanych do jednego konceptu UMLS. W sumie korpus obejmuje ponad 87 000 jednostek i ponad 68 000 relacji, a około 82% jednostek udało się znormalizować. Dwa niezależne przeglądy ekspertów potwierdziły te powiązania z bardzo wysoką zgodnością, co świadczy o rzetelności anotacji.
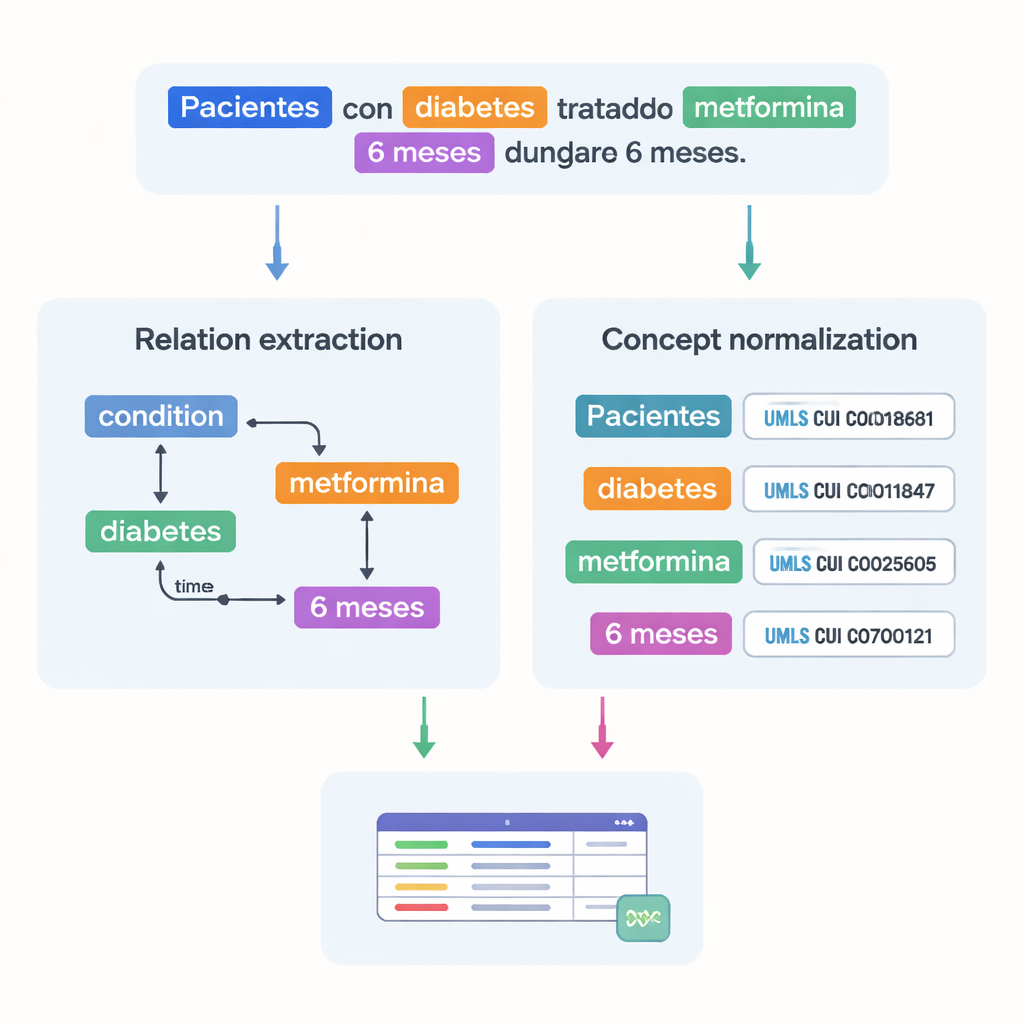
Uchwycenie powiązań między faktami medycznymi
Powyżej listowania terminów medycznych, zbiór danych rejestruje także, jak się one łączą. Autorzy zaprojektowali 18 typów relacji, które odzwierciedlają istotne wzorce w badaniach, takie jak która dawka należy do którego leku, jak długo trwa leczenie, czy też której dolegliwości doświadcza pacjent. Relacje temporalne pokazują, czy jedno zdarzenie następuje przed czy po innym, a inne linki zaznaczają, gdzie choroba występuje w ciele lub czy fraza wyraża zaprzeczenie albo przypuszczenie. Razem te relacje pozwalają komputerom budować grafy sytuacji pacjenta — kim jest pacjent, jaką ma chorobę, jakie otrzymuje leczenie i w jakim czasie — zamiast jedynie rozpoznawać pojedyncze słowa.
Trenowanie i testowanie nowoczesnych modeli AI
Aby pokazać praktyczną użyteczność korpusu, autorzy dostrojili kilka modeli AI opartych na transformatorach, w tym wielojęzyczne wersje BERT i RoBERTa. Trenowali te modele w dwóch zadaniach: ekstrakcji relacji, która uczy się odtwarzać powiązania między jednostkami, oraz normalizacji pojęć medycznych, która mapuje tekst na kody UMLS. W zadaniu ekstrakcji relacji najlepszy model osiągnął wynik F1 bliski 0,88, co oznacza, że poprawnie zidentyfikował większość relacji przy stosunkowo niewielu błędach. W przypadku normalizacji pojęć model wielojęzyczny o nazwie SapBERT, użyty bez dodatkowego treningu, prawidłowo wskazał właściwy koncept w pierwszej próbie prawie w 90% przypadków. Wyniki te pokazują, że dobrze anotowane, średniej wielkości zbiory danych mogą zasilać dokładne i wydajne modele nawet bez olbrzymich ogólnych systemów językowych.
Dlaczego to zasób ważny dla przyszłej opieki
Korpus CT‑EBM‑SP i powiązane modele stanowią podstawę narzędzi, które mogą automatycznie analizować hiszpańskie opisy badań klinicznych, dopasowywać je do dokumentacji pacjentów i wspierać wyszukiwanie kohort w szpitalach. Ponieważ dane są zgodne z międzynarodowymi standardami medycznymi i zostały starannie sprawdzone przez ekspertów, mogą też pomóc w tworzeniu podobnych zasobów dla innych języków, w których brakuje narzędzi cyfrowych. W praktycznym ujęciu chodzi o to, by ułatwić i zwiększyć bezpieczeństwo proponowania właściwych badań właściwym pacjentom, przyspieszając odkrycia medyczne i zmniejszając obciążenie personelu opieki zdrowotnej.
Cytowanie: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Słowa kluczowe: badania kliniczne, wydobywanie informacji z tekstu medycznego, hiszpańska opieka zdrowotna, modele transformatorowe, medycyna oparta na dowodach