Clear Sky Science · pl
Dane o scenach filmowych z Amazon X-Ray na rynku USA połączone z IMDb
Dlaczego sceny filmowe mają znaczenie dla zrozumienia kultury
Filmy kształtują nasze postrzeganie świata, a jednak większość badań nad kinem koncentrowała się na wynikach kasowych, podstawowych gatunkach lub sile gwiazd, a nie na tym, co faktycznie rozgrywa się na ekranie scena po scenie. W tym artykule przedstawiono nowy zbiór danych, który pozwala badaczom przyjrzeć się z bliska pojedynczym scenom, postaciom i kwestiom dialogowym w ponad trzech tysiącach filmów dostępnych w streamingu w USA na Amazon Prime Video. Poprzez połączenie funkcji X-Ray Amazona z Internet Movie Database (IMDb) autorzy oferują szczegółową, ustandaryzowaną mapę tego, kto pojawia się gdzie i kiedy w każdym filmie, otwierając drogę do bogatszych badań nad reprezentacją, opowiadaniem historii, a nawet nad systemami sztucznej inteligencji uczącymi się z wideo.
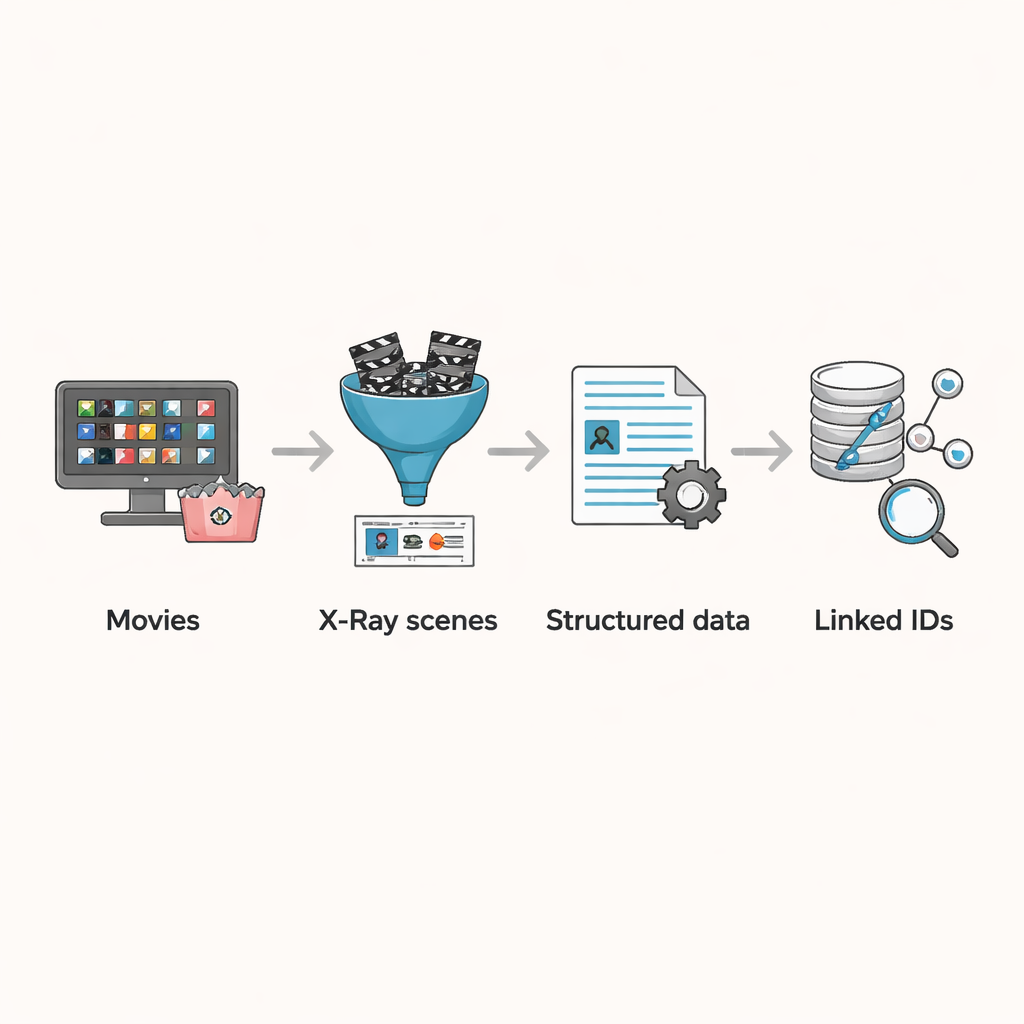
Od szkicowych scenariuszy do gotowych scen
Dotychczas większość badań na dużą skalę opierała się na scenariuszach lub plikach z napisami. Źródła te są użyteczne, lecz nieidealne. Scenariusze często są wczesnymi wersjami różniącymi się od ostatecznego montażu i mogą pomijać postaci drugoplanowe lub późne zmiany montażowe. Napisy oddają wypowiedziane kwestie, ale pomijają milczące postacie, statystów tła i czysto wizualne opowiadanie historii — na przykład długie ujęcie twarzy postaci. Z powodu tych luk wcześniejsze próby śledzenia, kto wchodzi w interakcje z kim na ekranie albo jak przedstawiane są różne grupy, musiały polegać wyłącznie na tekście, co może prowadzić do błędów w identyfikacji postaci i ich relacji.
Zamiana X-Ray w dane gotowe do badań
Funkcja X-Ray Amazona oferuje obejście tych problemów. Kiedy widz zatrzymuje film, X-Ray pokazuje, którzy aktorzy i postacie są aktualnie na ekranie — informacje kuratorowane i powiązane bezpośrednio z ostatecznym montażem filmu. Autorzy zbudowali pipeline do pozyskiwania danych na poziomie scen dla 3 265 filmów dostępnych w katalogu Prime Video w USA na sierpień 2023 r. Najpierw zebrali wszystkie filmy wliczone w Prime, odfiltrowali te bez informacji X-Ray i usunęli duplikaty wynikające z powtarzających się tytułów lub alternatywnych wersji. Dla każdego pozostałego filmu przechwycili strumienie danych używane przez odtwarzacz do ładowania informacji X-Ray i napisów, zapisując wyniki w uporządkowanych plikach, które wymieniają granice scen, postacie obecne w każdej scenie oraz, dla większości tytułów, precyzyjne czasy każdego segmentu z napisami.
Łączenie scen z szerszym światem filmowym
Prawdziwa siła zbioru danych wynika z połączenia tych podziałów scenicznych z zewnętrznymi informacjami. Choć X-Ray już wiąże każdą postać z profilem na IMDb, nie zawiera identyfikatora IMDb dla samego filmu. Autorzy opracowali algorytm dopasowujący, który zaczyna od tytułu filmu, pobiera kilka kandydatów z IMDb, a następnie porównuje obsadę wymienioną jako główna na IMDb z aktorami wskazanymi w danych X-Ray. Jeśli przynajmniej jeden kluczowy aktor się pokrywa, film traktowany jest jako dopasowany. Ten zautomatyzowany proces poprawnie dopasował przeważającą większość filmów, a zespół ręcznie zweryfikował pozostałe kilkaset trudniejszych przypadków, poprawiając błędne klasyfikacje i usuwając wpisy, które nie były fabularnymi filmami, takie jak występy stand-up. Ostateczny rezultat to starannie oczyszczony zbiór filmów, w którym każda scena, postać i napis można powiązać z bogatymi metadanymi, takimi jak rok, kraj i demografia obsady.
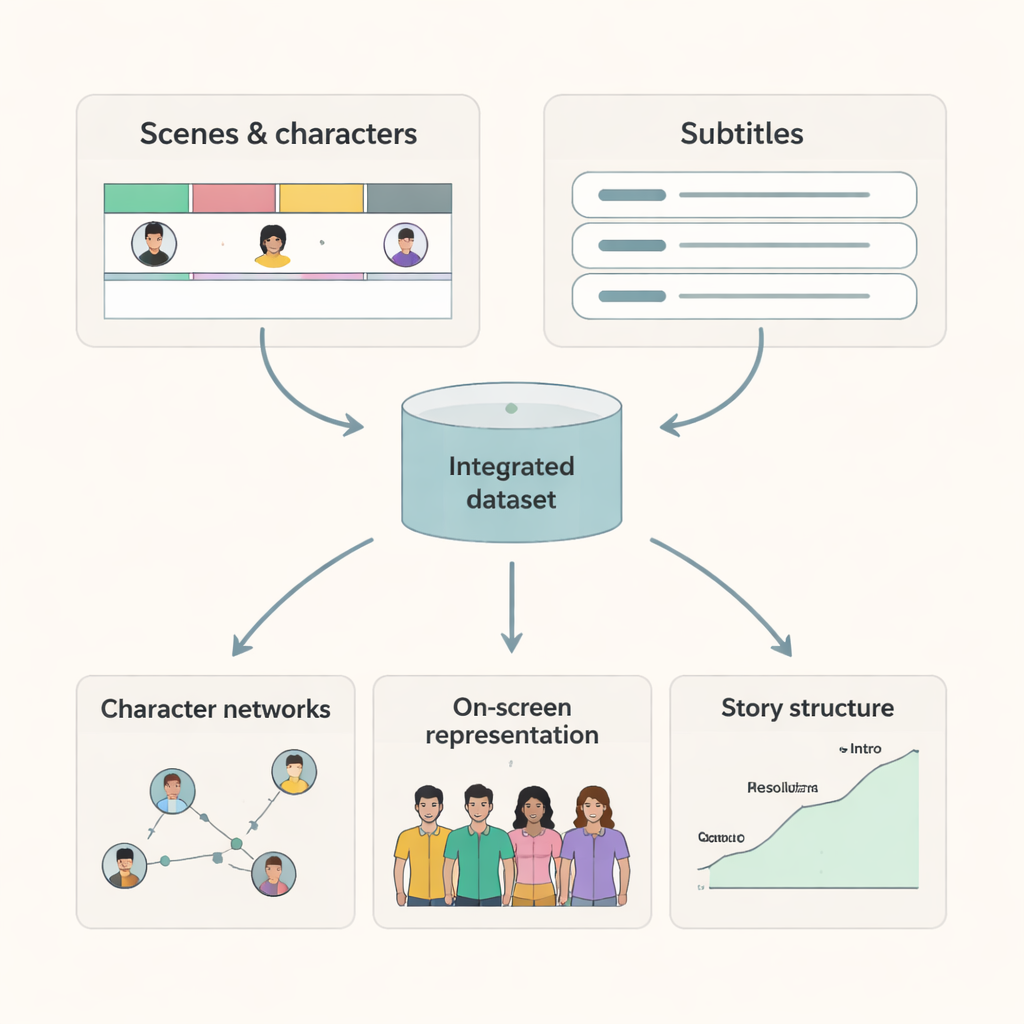
Co badacze mogą zrobić z tymi filmami
Dzięki temu, że każda scena ma wyraźne czasy rozpoczęcia i zakończenia oraz listę obecnych osób, badacze mogą teraz tworzyć precyzyjne mapy interakcji postaci i czasu ekranowego. Napisy wyrównane ze scenami umożliwiają badanie, jak język różni się między postaciami i kontekstami, albo jak pewne motywy rozwijają się poprzez dialog. Łącząc ten zbiór danych z dodatkowymi informacjami z IMDb i innych źródeł, naukowcy mogą badać pytania takie jak: jak zmieniała się równowaga płci na ekranie przez dekady? Czy postacie z różnych środowisk otrzymują równą uwagę narracyjną? Jak różnią się wzorce interakcji między gatunkami lub krajami? Zbiór danych oferuje także wysokiej jakości benchmark dla modeli sztucznej inteligencji dążących do rozumienia treści wideo, ponieważ dostarcza danych rzeczywistych dotyczących tego, kto jest widoczny i kiedy.
Nowe spojrzenie na codzienne filmy
Mówiąc prosto, ta praca zamienia tysiące filmów w przeszukiwalny katalog scena po scenie pokazujący, kto się pojawia, kto mówi i jak zbudowane są opowieści. Choć kolekcja ograniczona jest do tytułów dostępnych na amerykańskim Prime Video i zależy od wewnętrznych procesów X-Ray Amazona, obejmuje filmy z wielu dekad i gatunków, nie tylko słynne nagradzane produkcje. Taka szerokość pozwala badaczom badać codzienne filmy, a nie tylko klasyki, które przetrwały w pamięci. W miarę aktualizacji i rozszerzania zbioru danych, obiecuje on pogłębić nasze rozumienie tego, jak filmy odzwierciedlają społeczeństwo — i dostarczyć naukowcom społecznym oraz technologom wierniejszego obrazu tego, co faktycznie dzieje się na ekranie.
Cytowanie: Shrestha, S., Heo, Y., Barron, A.T.J. et al. Scene-level movie data from Amazon X-Ray in the US market combined with IMDb. Sci Data 13, 275 (2026). https://doi.org/10.1038/s41597-026-06602-y
Słowa kluczowe: zbiory danych filmowych, analiza na poziomie scen, Amazon X-Ray, metadane IMDb, reprezentacja na ekranie