Clear Sky Science · pl
Zestaw danych językowych Kymata Soto: elektro‑magnetoencefalograficzny zestaw danych do przetwarzania mowy naturalnej
Podsłuchując, jak mózg słyszy prawdziwe rozmowy
Większość tego, co mówimy i słyszymy na co dzień, to swobodna rozmowa, a nie pojedyncze słowa czy starannie przeczytane zdania. Tymczasem większość badań nad językiem opierała się na sztucznych zadaniach. Zestaw danych językowych Kymata Soto zmienia to, udostępniając bogaty, otwarty zbiór zapisów aktywności mózgu u osób, które po prostu słuchały żywych dyskusji radiowych po angielsku i rosyjsku, dając naukowcom potężne nowe okno na to, jak nasze mózgi przetwarzają naturalną mowę.
Nowa biblioteka reakcji mózgu na prawdziwą mowę
Projekt łączy dwie zaawansowane metody rejestracji aktywności mózgu — elektroencefalografię (EEG) i magnetoencefalografię (MEG) — z 35 dorosłych uczestników: 20 rodzimych użytkowników angielskiego i 15 rodzimych użytkowników rosyjskiego. Gdy siedzieli spokojnie i słuchali około sześciu i pół minuty rozmowy w stylu radiowym w swoim języku, ich aktywność mózgu była rejestrowana tysiąc razy na sekundę. Każda osoba słyszała to samo nagranie wielokrotnie, co pozwoliło badaczom uśredniać powtórzenia i wyodrębniać wiarygodne reakcje mózgu z tła szumów. Efektem jest szczegółowy, czasowo powiązany zapis tego, jak mózg reaguje, moment po momencie, gdy słuchacze śledzą rozwijającą się dyskusję.

Rozmowy o lodach i kawie
Zamiast korzystać z klasycznych historii czy sztucznych zdań, zespół wybrał zajmujące, ale codzienne tematy: historię lodów dla słuchaczy anglojęzycznych oraz historię kawy kolumbijskiej dla słuchaczy rosyjskojęzycznych. Oba nagrania pochodziły z dyskusji studyjnych BBC z udziałem trzech rozmówców (dwóch mężczyzn i jednej kobiety). Rozmowy zostały zmontowane do około 400 sekund i podawane na wygodnych poziomach głośności przez słuchawki douszne. Po każdej powtórce uczestnicy odpowiadali na jedno lub dwa proste pytania wielokrotnego wyboru dotyczące treści — na tyle, by upewnić się, że pozostają skupieni i śledzą opowieść, ale nie w celu intensywnego testowania.
Utrzymanie wzroku zajętego, a uwagi na dźwięku
W czasie słuchania uczestnicy patrzyli na centralny krzyżyk na ekranie. Wokół niego unosiły się chmury kolorowych kropek, poruszające się i zmieniające w sposób pozornie losowy. Poruszające się kropki pełniły dwie funkcje: pomagały utrzymać wzrok uczestników w stałym miejscu, co poprawia jakość danych, oraz tworzyły kontrolowany wzorzec ruchu i koloru, który inni badacze mogą później analizować. Co ważne, kropki nie były zsynchronizowane z treścią mowy, więc nie „ilustrowały” historii ani nie nadawały jej znaczenia, lecz stanowiły stałe tło wizualne, które można badać równolegle z dźwiękiem.
Od surowych sygnałów mózgowych do danych gotowych do użycia
Badacze szczegółowo udokumentowali każdy aspekt eksperymentu i zorganizowali zestaw danych zgodnie z międzynarodowym standardem dla danych mózgowych zwanym BIDS. Dla każdego ochotnika dostępne są surowe zapisy EEG i MEG, znaczniki czasowe rozpoczęcia audio, zdarzenia wizualne co sekundę oraz fragmenty treningowe. Zespół dostarcza też oryginalne pliki audio, pełne transkrypcje i precyzyjne oznaczenia czasowe rozpoczęcia każdego słowa, a nawet każdego pojedynczego dźwięku mowy. Dołączono skrypty, dzięki którym inni mogą automatycznie odtworzyć dokładne fragmenty audio użyte w eksperymencie. Dla grupy anglojęzycznej udostępniono zanonimizowane skany MRI mózgu, aby móc mapować odpowiedzi mózgowe na indywidualną anatomię; dla grupy rosyjskojęzycznej zgoda nie pozwalała na udostępnienie obrazów MRI, dlatego zaleca się korzystanie ze standardowych uśrednionych szablonów mózgu.
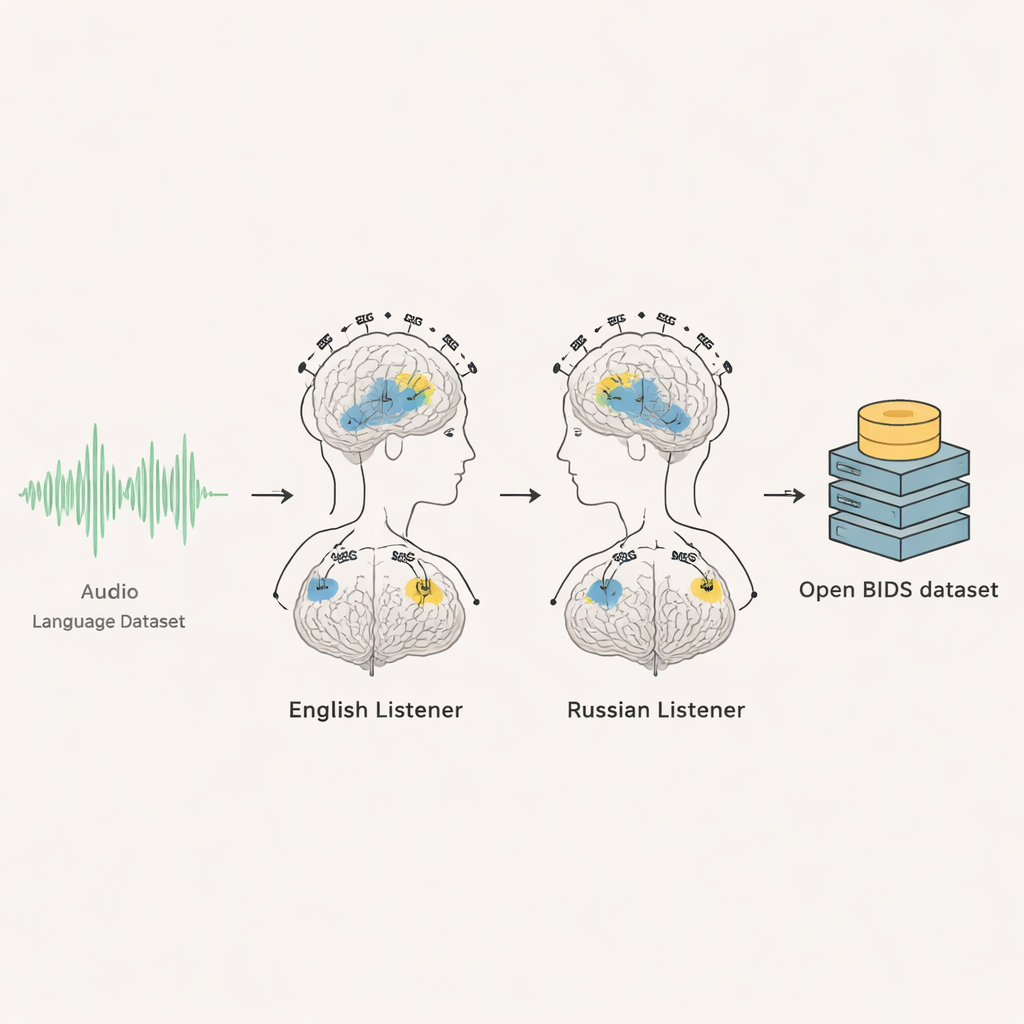
Sprawdzanie, czy sygnały mają sens
Aby upewnić się, że dane są naukowo wiarygodne, autorzy przeprowadzili analizy walidacyjne skoncentrowane na tym, jak mózg śledzi zmiany głośności dźwięku w czasie. Przekształcili audio w kilka matematycznych opisów „zmiennej w czasie głośności”, a następnie zbadali, gdzie i kiedy odpowiedzi mózgu pokrywały się z tymi wzorcami głośności. Zarówno u słuchaczy angielskich, jak i rosyjskich, mózg wykazał podobne wzorce czasowe, zgodne z wynikami wcześniejszych badań. Ta zgodność między językami oraz z wcześniejszymi pracami jest silnym sygnałem, że nagrania są czyste, wiarygodne i gotowe do wykorzystania przez innych badaczy.
Dlaczego to ma znaczenie dla przyszłych badań nad mózgiem i językiem
Dla osób niebędących specjalistami najważniejszy wniosek jest taki: ten zestaw danych to nowe wspólne źródło, które pozwala wielu zespołom badawczym badać, jak mózg przetwarza prawdziwą, spontaniczną mowę. Ponieważ jest otwarty, dobrze opisany i zarejestrowany w dwóch językach, może wspierać projekty od podstawowych pytań o to, jak rozumiemy rozmowy, po porównania międzyjęzykowe, aż po ambitne próby dekodowania mowy bezpośrednio z aktywności mózgowej. Krótko mówiąc, Zestaw danych językowych Kymata Soto to mniej pojedyncze rozwiązanie, a więcej wysokiej jakości, wspólna podstawa dla społeczności naukowej do badania, jak nasze mózgi nadają sens rozmowom, które wypełniają nasze codzienne życie.
Cytowanie: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
Słowa kluczowe: mózg i język, percepcja mowy, EEG MEG, konwersacja naturalistyczna, otwarte dane neuroobrazowe