Clear Sky Science · pl
Semantyczne wyrównanie modelu metadanych Niemieckiego Archiwum Genomu i Fenomu człowieka w europejskim środowisku genomiki
Dlaczego udostępnianie danych genetycznych to coś więcej niż pliki
Nowoczesna medycyna coraz częściej opiera się na odczytywaniu naszego DNA, żeby diagnozować choroby i dopasowywać terapie. Prawdziwa siła genomiki ujawnia się jednak wtedy, gdy dane z wielu szpitali i krajów można połączyć. To działa tylko wtedy, gdy każdy zestaw danych jest opisany w sposób jasny i zgodny oraz gdy rygorystycznie przestrzega się przepisów o ochronie prywatności, takich jak europejskie RODO. W artykule wyjaśniono, jak Niemieckie Archiwum Genomu i Fenomu człowieka (GHGA) buduje szczegółowy „system opisu” badań genomowych, aby cenne dane można było odnaleźć, zrozumieć i bezpiecznie udostępniać w całej Europie.
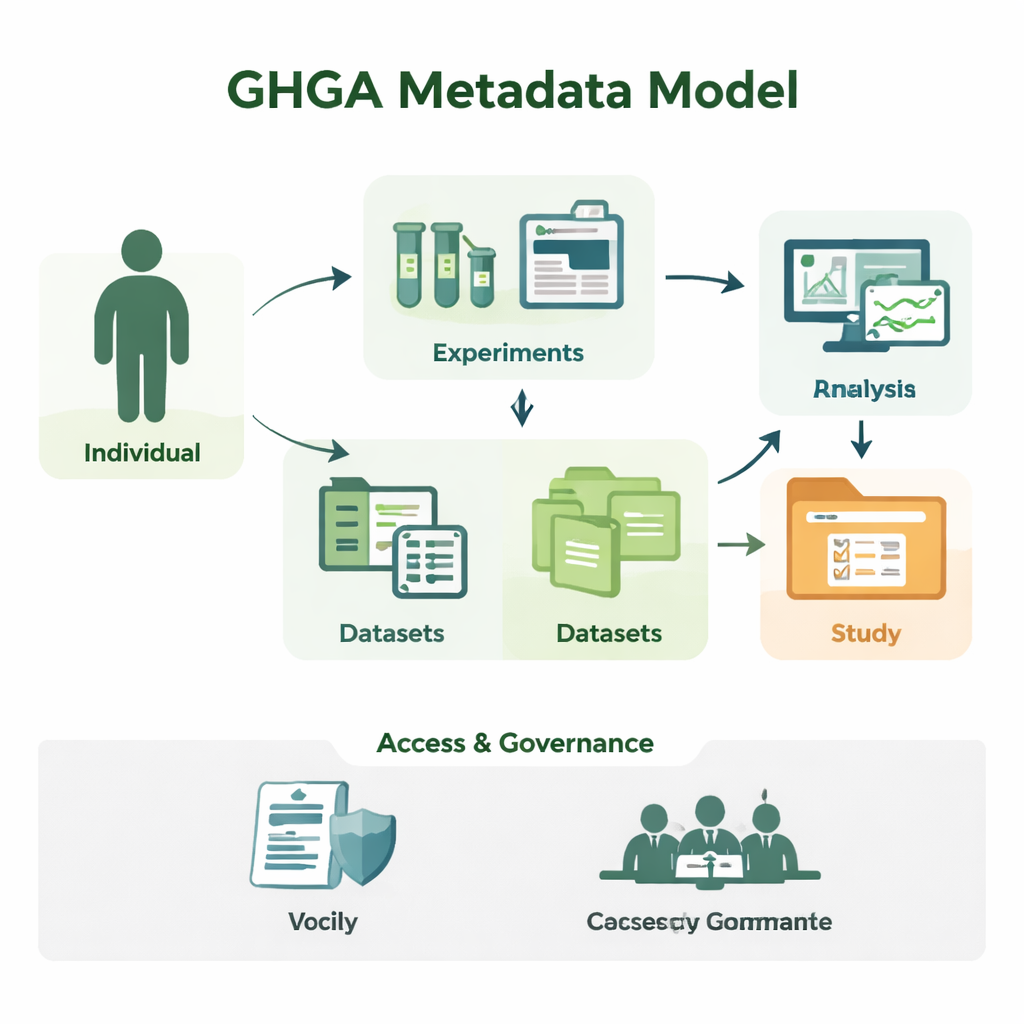
Od surowych sekwencji do zrozumiałych badań
Badania genomowe generują ogromne ilości danych sekwencyjnych, ale sam plik z literami DNA niewiele mówi. Naukowcy muszą wiedzieć, od kogo pochodzi próbka, z jakiej tkanki, jak przeprowadzono eksperyment i na jakich warunkach można ponownie użyć danych. GHGA rejestruje te informacje kontekstowe jako metadane. Jego model porządkuje metadane w 16 bloków konstrukcyjnych, takich jak osoba uczestnicząca w badaniu („Indywiduum”), pobrana próbka, przeprowadzony eksperyment i analiza, powstałe pliki danych oraz zbiory danych i badania, które je grupują. Oddzielając szczegóły naukowe od administracyjnych, np. warunków dostępu, model odzwierciedla sposób funkcjonowania rzeczywistego laboratorium i portalu danych, ale w formie, którą komputery potrafią niezawodnie przetwarzać.
Utrzymanie użyteczności danych przy zachowaniu anonimowości osób
Ponieważ GHGA przetwarza wrażliwe dane zdrowotne dotyczące ludzi, zespół musiał zaprojektować model tak, by był naukowo bogaty, a jednocześnie nie ułatwiał identyfikacji osób. Europejskie przepisy RODO traktują jako dane osobowe informacje, które można rozsądnie powiązać z jednostką, nawet jeśli usunięto imiona. W artykule opisano szczegółową analizę prywatności, która wykazała, że łączenie cech takich jak wiek, kod pocztowy czy rzadkie rozpoznania może prowadzić do ujawnienia tożsamości. W odpowiedzi publiczny portal GHGA unika dokładnych danych lokalizacyjnych, grupuje wiek w szerokie przedziały zamiast podawać lata życia, oraz agreguje szczegółowe kody diagnoz do grubszych kategorii. Dzięki temu badacze wciąż widzą, czy dany zbiór może być dla nich istotny, podczas gdy wysiłek konieczny do wyodrębnienia pojedynczej osoby staje się nierealistyczny.
Sprawdzanie zgodności z europejskim ekosystemem genomiki
Aby być naprawdę użyteczny, model metadanych GHGA musi pasować do szerszej europejskiej sieci archiwów genomowych i narzędzi. Autorzy porównali więc swój model, element po elemencie, z czterema innymi powszechnie używanymi ramami: dwiema wersjami European Genome-phenome Archive (EGA), standardem ISA-tab oraz modelem FAIR Genomes z holenderskiej ochrony zdrowia. Przeprowadzili szczegółowy „crosswalk”, pytając dla każdego pola GHGA, czy istnieje mu równoważnik w innych modelach i odwrotnie. Stwierdzili, że większość kluczowych właściwości GHGA ma wyraźne odpowiedniki gdzie indziej, zwłaszcza w opisie badań, próbek, eksperymentów, analiz i formatów plików. Oznacza to, że zbiory danych GHGA można rozumieć i integrować obok danych przechowywanych w innych europejskich systemach.
Wyszukiwanie wspólnego gruntu — i tego, czego wciąż brakuje
Z tego porównania zespół wyodrębnił 25 „konsensualnych” pól metadanych, które występują przynajmniej w trzech z pięciu modeli. Obejmują one elementy niezbędne, takie jak płeć i stan zdrowia uczestników, użyta tkanka, rodzaj sekwencjonowania i instrument, metoda analizy, formaty plików oraz podstawowe opisy badania i dane kontaktowe. Te wspólne pola pokrywają się z istniejącymi minimalnymi wytycznymi raportowania i mogą służyć jako podstawowa lista kontrolna dla projektujących nowe portale danych genomowych. Jednocześnie analiza ujawniła informacje, które niektóre modele zbierają, a które GHGA obecnie pomija lub przyjmuje jedynie w elastycznej formie tekstowej, takie jak dokładne daty pobrania próbki i sekwencjonowania, wykluczone diagnozy czy szczegółowe imiona kontaktów. Wiele z tych braków to świadome kompromisy na rzecz prywatności i anonimowości.
Co to oznacza dla przyszłych badań zdrowotnych
Podsumowując, badanie pokazuje, że model metadanych GHGA jest szczegółowy, elastyczny i ściśle zgrany z międzynarodową praktyką, przy jednoczesnym zachowaniu surowych europejskich reguł prywatności. Obejmuje już wszystkie pola, które inne archiwa traktują jako obowiązkowe, i można go rozszerzyć o nowe technologie, takie jak omiki pojedynczych komórek czy omiki przestrzenne. Oferując przejrzysty sposób opisu, kogo i co obejmuje badanie genomowe, jak powstały dane i na jakich warunkach mogą być ponownie użyte, GHGA pomaga przekształcać izolowane silosy danych w połączone zasoby badawcze. Dla pacjentów zwiększa to szanse, że ich oddane dane będą mogły w bezpieczny sposób przyczynić się do odkryć i lepszych terapii ponad granicami przez wiele lat.
Cytowanie: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
Słowa kluczowe: udostępnianie danych genomowych, standardy metadanych, prywatność i RODO, GHGA, medycyna spersonalizowana