Clear Sky Science · pl
Wiarygodność LLM jako asystentów medycznych dla ogółu: losowe badanie z prerejestracją
Dlaczego twój telefon może nie być najlepszym pierwszym lekarzem
Coraz więcej osób zwraca się do czatbotów opartych na sztucznej inteligencji, gdy źle się czują, licząc na szybkie odpowiedzi: czy warto się martwić, co mogą oznaczać objawy i czy jechać do szpitala. Badanie stawia proste, ale pilne pytanie: jeśli zwykli ludzie korzystają w domu z potężnych modeli językowych jako pomocników medycznych, czy naprawdę podejmują dzięki temu lepsze decyzje dotyczące zdrowia — czy też technologia może dawać fałszywe poczucie bezpieczeństwa?
Testowanie inteligentnych maszyn na realistycznych przypadkach
Aby to sprawdzić, badacze z Wielkiej Brytanii opracowali dziesięć realistycznych historii medycznych, takich jak nagły silny ból głowy czy problemy z oddychaniem, bazujących na powszechnych dolegliwościach, z którymi można się spotkać. Zespół doświadczonych lekarzy uzgodnił najlepszy „kolejny krok” dla każdej historii — od pozostania w domu i samopielęgnacji po wezwanie karetki — oraz wymienił kluczowe stany chorobowe, które rozważna osoba powinna brać pod uwagę. Następnie 1 298 dorosłych z całej Wielkiej Brytanii losowo przydzielono do jednej z czterech opcji: skorzystać z jednego z trzech wiodących czatbotów AI albo polegać na tym, co zwykle wykorzystaliby w domu, np. wyszukiwarce internetowej czy własnym doświadczeniu.
Jak wypadły ludzie i maszyny — oddzielnie i razem
Gdy modele językowe testowano samodzielnie, podając im pełne opisy przypadków i pytając bezpośrednio o diagnozę i zalecaną akcję, wypadły imponująco dobrze. We wszystkich trzech systemach poprawnie zasugerowano przynajmniej jedno istotne schorzenie w około 95% przypadków, a właściwy poziom pilności wybrano w więcej niż połowie przypadków — znacznie lepiej niż losowe zgadywanie. Na papierze systemy wyglądały więc na silnych kandydatów do wspierania zaniepokojonych pacjentów.
Gdy porada AI spotyka się z prawdziwymi ludźmi
Ale gdy w grę weszli zwykli użytkownicy, obraz się zmienił. Uczestnicy korzystający z AI nie byli bardziej trafni niż grupa kontrolna w wyborze kolejnego kroku, a w nazewnictwie istotnych schorzeń wypadali nawet gorzej. Osoby w grupie bez AI były około 1,8 razy bardziej skłonne wskazać poprawne schorzenie niż ci korzystający z czatbotów. Większość uczestników we wszystkich grupach bagatelizowała powagę sytuacji. Innymi słowy, dostęp do zaawansowanego modelu językowego nie pomógł ludziom lepiej zrozumieć objawów i nie skłonił wyraźnie do bezpieczniejszych decyzji.
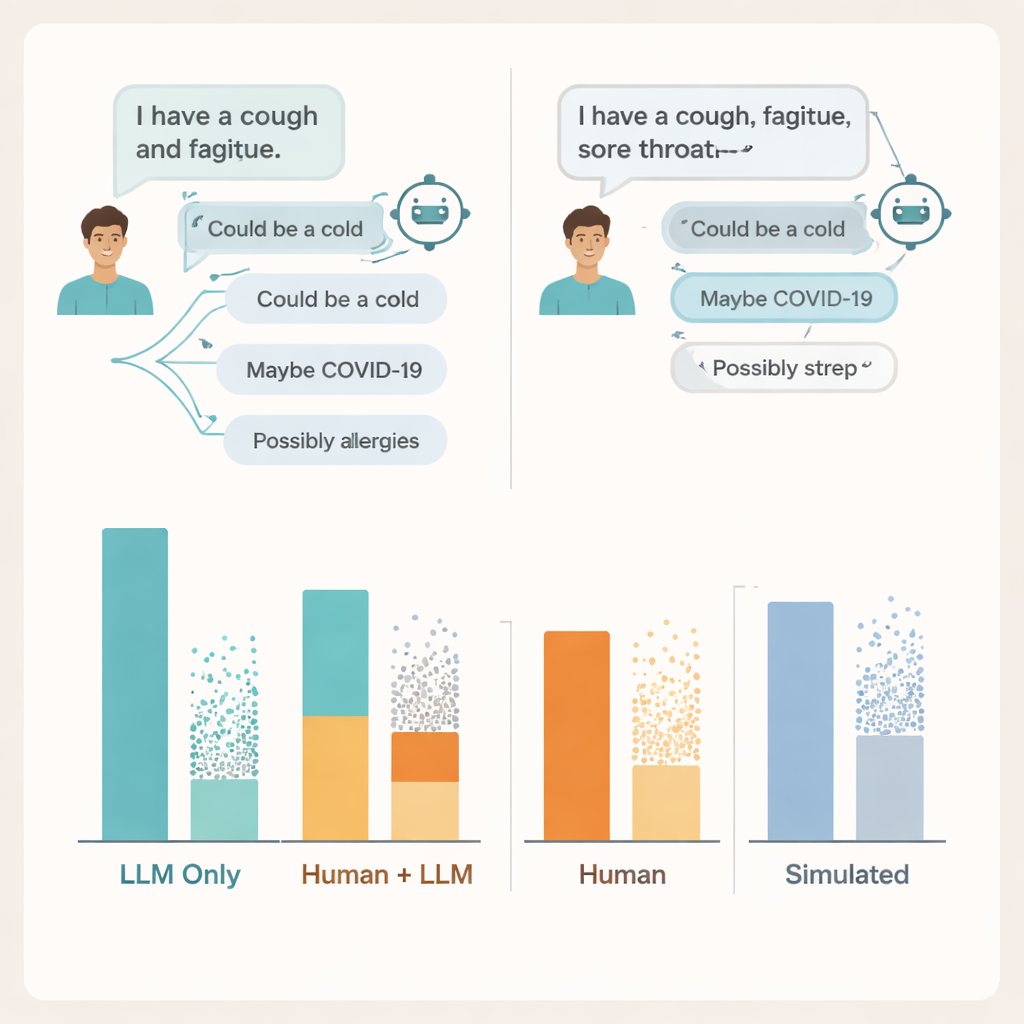
Gdzie rozmowa się załamuje
Aby zrozumieć dlaczego, badacze przeanalizowali rzeczywiste transkrypcje czatów. Znaleźli problemy po obu stronach konwersacji. Wielu użytkowników nie podało wystarczająco szczegółów dotyczących objawów, by AI mogła udzielić rzetelnej porady — podobnie jak pacjenci czasem pomijają kluczowe informacje podczas rozmowy z lekarzem. Same modele często wymieniały przynajmniej jedno istotne schorzenie, ale dodawały też kilka błędnych lub mylących możliwości, i użytkownicy mieli trudności z rozróżnieniem, które sugestie są istotne. W niektórych przypadkach niemal identyczne opisy objawów prowadziły do zdecydowanie różnych porad od tego samego modelu, co utrudniało ludziom wyrobienie sobie jasnego wyczucia, kiedy ufać temu, co widzą na ekranie.
Dlaczego standardowe testy nie wykrywają prawdziwych zagrożeń
Zespół porównał też te wyniki z dwoma popularnymi sposobami oceny medycznych AI: pytaniami w formie testu wielokrotnego wyboru oraz w pełni symulowanymi czatami „pacjent–lekarz” prowadzonymi między dwoma modelami. W obu przypadkach systemy znów wyglądały dobrze, osiągając lub przewyższając typowe progi zdawalności w pytaniach egzaminacyjnych i radząc sobie lepiej w rozmowach z symulowanymi pacjentami niż z prawdziwymi. Jednak wysokie wyniki na egzaminach i dopracowane symulacje nie przekładały się na to, jak radzili sobie realni ludzie używający tych samych narzędzi. Autorzy twierdzą, że benchmarki testujące wiedzę w izolacji nie uchwytują chaotycznej, kruchiej natury rzeczywistych interakcji człowiek–AI.
Co to oznacza dla pacjentów i systemów opieki zdrowotnej
Na razie, konkluduje badanie, obecne ogólnego przeznaczenia modele językowe nie są gotowe, by działać jako niesuperwizowani doradcy pierwszego kontaktu dla społeczeństwa. Zawierają wprawdzie dużą ilość wiedzy medycznej, ale ta wiedza nie przekłada się automatycznie na bezpieczniejsze decyzje, gdy zaniepokojeni ludzie wpisują w domu niepełne, zdezorientowane pytania. Uczynienie AI rzeczywiście pomocną w sytuacjach o wysokich stawkach, takich jak opieka zdrowotna, będzie wymagać czegoś więcej niż lepszych wyników egzaminacyjnych — potrzebnego będzie staranne projektowanie, testy z różnorodnymi rzeczywistymi użytkownikami oraz surowsze kontrole sposobu, w jaki informacje są zbierane, wyjaśniane i obdarzane zaufaniem w toku rozmowy.
Cytowanie: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Słowa kluczowe: czatboty medyczne, samodiagnoza, AI w opiece zdrowotnej, podejmowanie decyzji przez pacjenta, duże modele językowe