Clear Sky Science · pl
Syntezowanie literatury naukowej za pomocą modeli językowych wspieranych wyszukiwaniem
Dlaczego nadążanie za nauką jest tak trudne
Co roku w sieci pojawiają się miliony nowych artykułów naukowych. Żaden badacz nie jest w stanie ich wszystkich przeczytać, a tymczasem w tym potoku informacji mogą kryć się istotne terapie medyczne, spostrzeżenia klimatyczne czy przełomy technologiczne. W tym artykule badamy, czy zaawansowane systemy AI mogą pomóc naukowcom przeszukiwać ten ocean badań i składać je w przejrzyste, wiarygodne streszczenia — bez wynajdowania faktów.
Nowy rodzaj asystenta badawczego
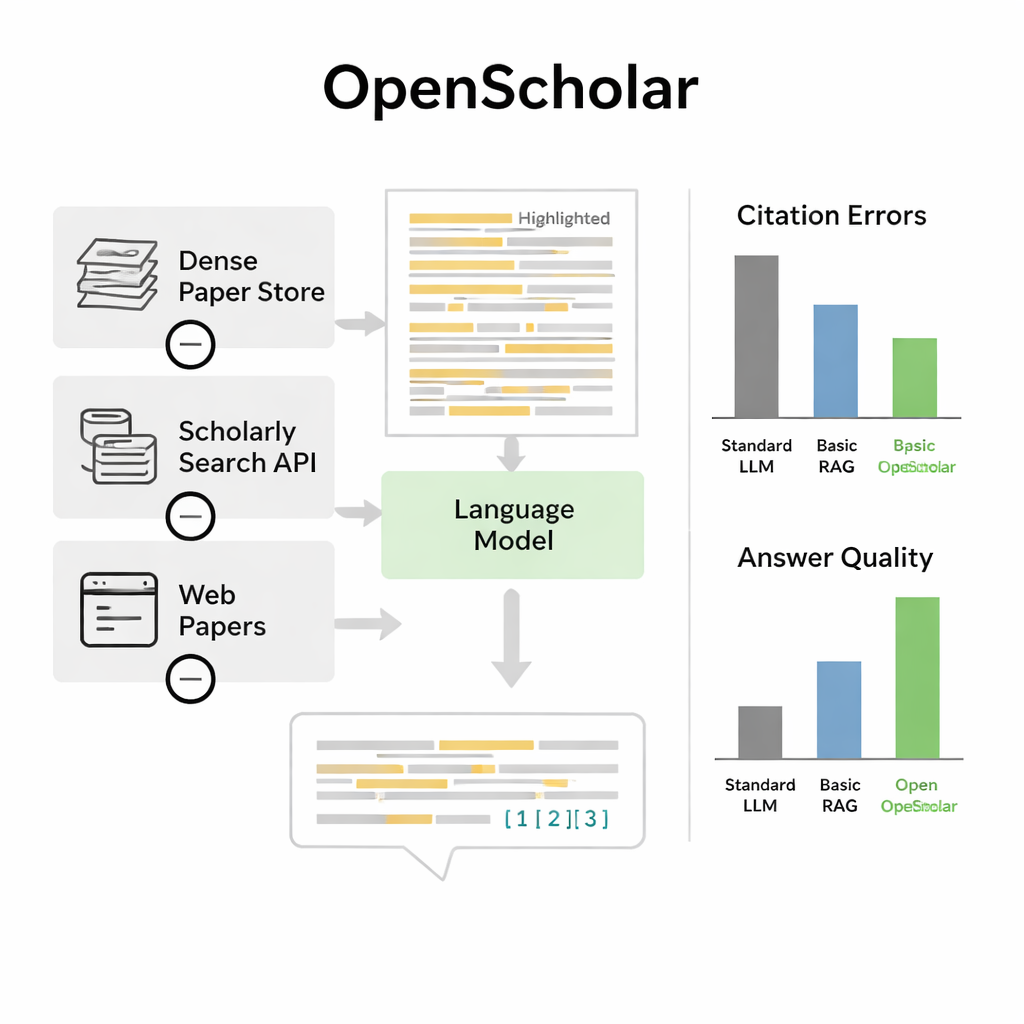
Autorzy przedstawiają OpenScholar, system sztucznej inteligencji zaprojektowany specjalnie do czytania i syntezowania literatury naukowej. W odróżnieniu od ogólnych chatbotów, OpenScholar jest ściśle powiązany z olbrzymią otwartą bazą danych obejmującą około 45 milionów artykułów badawczych, nazwaną OpenScholar DataStore. Gdy naukowiec zada pytanie — na przykład jak schładzać lewitujące nanocząstki lub które metody najlepiej sprawdzają się w obrazowaniu mózgu — system najpierw przeszukuje tę bazę w poszukiwaniu odpowiednich fragmentów, a następnie tworzy odpowiedź z cytowaniami w tekście, podobnie jak artykuł przeglądowy napisany przez człowieka. Proces ten jest powtarzany kilkakrotnie: system krytykuje i dopracowuje własne wersje, by poprawić jasność, kompletność i jakość cytowań.
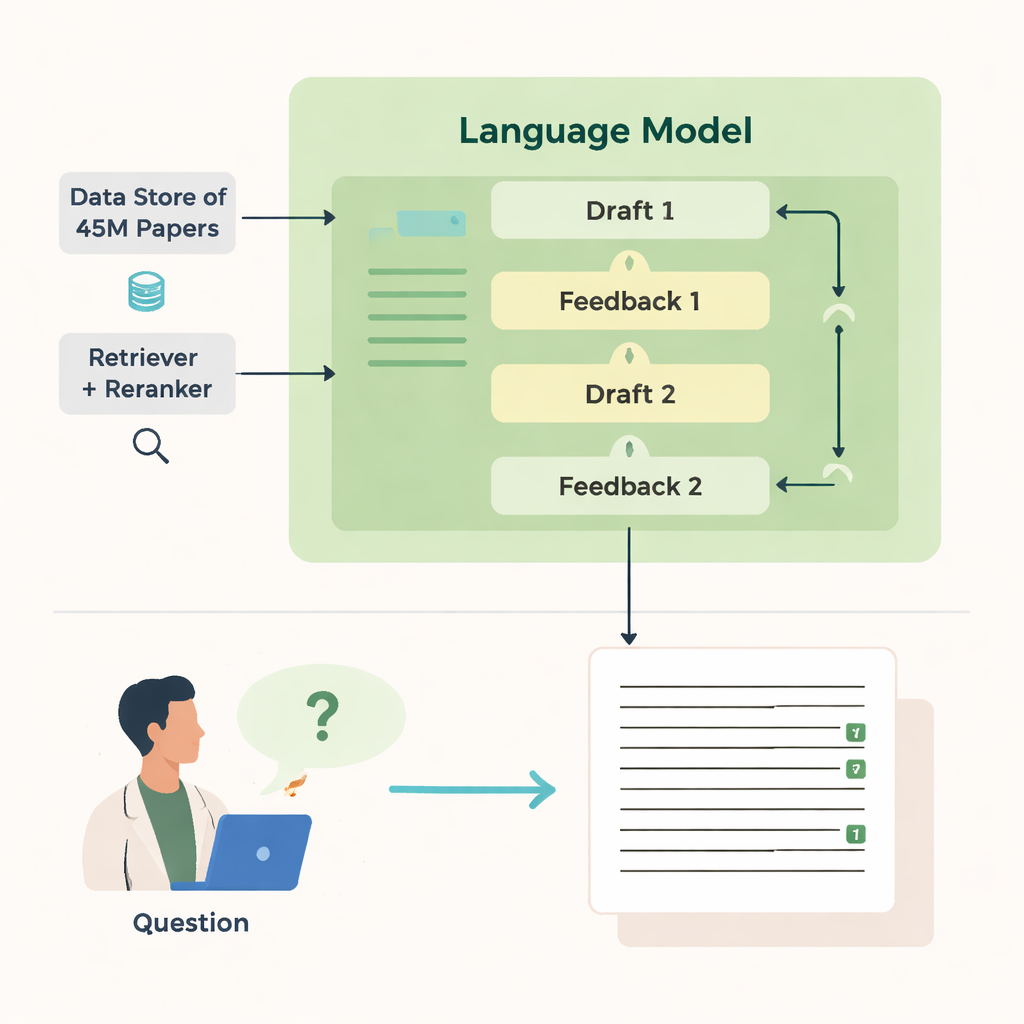
Jak wyszukuje i pisze
Moc OpenScholar wynika z kilku skoordynowanych komponentów. Moduł „retriever” skanuje uprzednio obliczone osadzenia tekstu (embeddings) z milionów artykułów, by znaleźć obiecujące fragmenty, podczas gdy „reranker” przearanżowuje te fragmenty, koncentrując się na najbardziej istotnych. Model językowy wykorzystuje następnie zebrane dowody do wygenerowania rozbudowanej odpowiedzi z numerowanymi odwołaniami. Po pierwszym szkicu model tworzy dla siebie informację zwrotną — wskazując brakujące perspektywy, słabą strukturę lub niedostateczne dowody — i w razie potrzeby uruchamia bardziej ukierunkowane wyszukiwania. Potem przepisuje odpowiedź, wplatając nowe artykuły i korygując cytowania. Ostateczna kontrola zabezpiecza, że twierdzenia wymagające wsparcia mają przynajmniej jedno odnalezione źródło.
Testowanie twierdzeń i cytowań
Aby sprawdzić, czy OpenScholar rzeczywiście pomaga, autorzy stworzyli ScholarQABench, duży benchmark zaprojektowany tak, by naśladować pytania spotykane w przeglądach literatury. Zawiera on prawie 3 000 pytań napisanych przez ekspertów oraz setki długich odpowiedzi z zakresu informatyki, fizyki, neuronauki i biomedycyny. Istotne jest to, że pytania te zwykle wymagają przeczytania kilku artykułów, nie tylko streszczenia jednego. Zespół ocenił systemy według wielu osi: poprawność faktograficzną, stopień pokrycia kluczowych punktów, jasność pisania oraz to, jak dokładnie cytowania odzwierciedlają treść źródłowych prac. Połączono automatyczne kontrole z szczegółowymi ocenami ekspertów z doktoratami, którzy porównywali odpowiedzi generowane przez AI z odpowiedziami napisanymi przez ludzi.
Pokonując silne chatboty i dorównując ekspertom
W tym benchmarku OpenScholar przewyższył zarówno standardowe modele językowe, jak i wcześniejsze narzędzia, które jedynie dołączały komponent wyszukiwania do ogólnego chatbota. Kompaktowa, ośmiomiliardowa wersja, trenowana wyłącznie na otwartych danych, poradziła sobie lepiej w wymagającym zadaniu syntezy obejmującej wiele artykułów niż GPT-4o oraz konkurencyjny system PaperQA2, mimo że te ostatnie korzystały z większych, zamkniętych modeli. Jednym z uderzających wyników było częste „halucynowanie” odniesień przez zwykłe chatboty: w 78–90 procent przypadków ich listy cytowań zawierały artykuły, które nie istniały lub nie popierały twierdzeń. Dla porównania, dokładność cytowań OpenScholar zbliżała się do poziomu ekspertów. Gdy eksperci porównywali odpowiedzi bezpośrednio, preferowali OpenScholar-8B w stosunku do odpowiedzi pisanych przez ekspertów w około połowie przypadków, a potok OpenScholar oparty na GPT-4o w około 70 procentach przypadków, głównie dlatego, że AI obejmowało więcej istotnych badań i organizowało je przejrzyście.
Ograniczenia i przyszłe usprawnienia
Pomimo tych postępów autorzy podkreślają, że OpenScholar nie zastąpi naukowców. System wciąż może pominąć najbardziej reprezentatywne prace, nadmiernie podkreślać mniej istotne badania lub wprowadzać błędy faktograficzne, szczególnie w bardziej kompaktowych modelach. Sam benchmark ma też ograniczenia: koncentruje się głównie na informatyce, biomedycynie i fizyce, a starannie anotowane pytania nadal są stosunkowo nieliczne, ponieważ czas ekspertów jest kosztowny. Oceny mają również trudność z pełnym uchwyceniem subtelniejszych cech, takich jak to, czy cytowania wskazują rzeczywiście prace przełomowe, czy też czy odpowiedź rzeczywiście poprowadziłaby do nowego eksperymentu.
Co to oznacza dla codziennej nauki
Dla osób spoza wąskich specjalizacji główny wniosek jest taki, że starannie zaprojektowane narzędzia AI już dziś mogą pomóc naukowcom skuteczniej poruszać się po literaturze naukowej, pod warunkiem że są powiązane z rzeczywistymi danymi i podlegają surowym standardom dowodów i przejrzystości. OpenScholar pokazuje, że gdy system AI jest zbudowany od podstaw z myślą o wyszukiwaniu, weryfikowaniu i cytowaniu prawdziwych artykułów — i gdy jego osiągi są testowane wobec ekspertów ludzkich — może tworzyć streszczenia literatury, które są nie tylko czytelne, ale i weryfikowalne. W praktyce takie narzędzia mogłyby uwolnić badaczy, by skupili się bardziej na projektowaniu eksperymentów i interpretacji wyników, przy jednoczesnym zachowaniu ludzkiej kontroli nad oceną tego, co jest prawdziwe i ważne.
Cytowanie: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Słowa kluczowe: przegląd literatury naukowej, modele językowe wspierane wyszukiwaniem, OpenScholar, dokładność cytowań, narzędzia AI dla badań