Clear Sky Science · pl
Modele językowe wspomagające przewidywanie i odkrywanie metabolitów ssaków
Ukryta chemia wewnątrz naszych ciał
Każda kropla krwi czy moczu zawiera tysiące drobnych cząsteczek, które odzwierciedlają to, co jemy, jak żyjemy i czy zaczynamy chorować. Jednak dla większości tych związków naukowcy nie znają ich nazw ani funkcji. Artykuł przedstawia DeepMet — system sztucznej inteligencji, który „czyta” język tych cząsteczek i przewiduje, które z nich brakuje na obecnych mapach chemii ludzi i zwierząt. Skierowując eksperymenty ku najbardziej obiecującym kandydatom, DeepMet pomaga badaczom odsłonić tę chemiczną ciemną materię i lepiej zrozumieć funkcjonowanie naszych ciał.
Dlaczego tak wiele cząsteczek pozostaje nieznanych
Nowoczesne instrumenty potrafią jednocześnie zważyć i częściowo „odcisnąć” tysiące cząsteczek w próbce tkanki. Ale przełożenie tych odcisków na dokładne struktury jest trudne. Istniejące bazy danych zawierają wiele znanych metabolitów, jednak większość sygnałów wykrywanych w rzeczywistych próbkach nie pasuje do żadnego wpisu w tych katalogach. Ta luka sugeruje, że obecne mapy metabolizmu są niekompletne i że wiele naturalnych związków u ssaków nigdy nie zostało opisanych. Autorzy postanowili zbudować narzędzie, które nauczy się na znanych metabolitach, a następnie wyobrazi sobie najbardziej prawdopodobne brakujące związki — w sposób podobny do tego, w jaki modele językowe przewidują prawdopodobne słowa w zdaniu.
Nauka maszynie gramatyki metabolizmu
Zespół wytrenował sieć neuronową nazwaną DeepMet na około 2000 dobrze udokumentowanych metabolitach ludzkich, kodując każdy jako krótką sekwencję opisującą jego strukturę. Po początkowym treningu na cząsteczkach podobnych do leków, aby poznać ogólne zasady chemii, DeepMet został dopracowany (fine-tuned) na zbiorze metabolitów. Gdy poproszono go o generowanie nowych struktur, model tworzył cząsteczki mieszczące się w tych samych obszarach przestrzeni chemicznej co realne metabolity i nawet odtwarzał wiele znanych typów reakcji enzymatycznych, mimo że nie podano mu tych reguł wprost. Innymi słowy, DeepMet wydawał się internalizować niepisaną gramatykę łączącą podstawowe bloki konstrukcyjne, takie jak cukry i aminokwasy, w biologicznie realistyczne małe cząsteczki.
Przewidywanie, które nowe cząsteczki prawdopodobnie istnieją
Naukowcy następnie wygenerowali miliard kandydatów z DeepMet i policzyli, jak często pojawiała się każda unikalna struktura. Struktury pojawiające się często miały tendencję do przypominania znane metabolity, dzielenia z nimi wspólnych rdzeni chemicznych i pasowania do prawdopodobnych przekształceń enzymatycznych. Aby sprawdzić, czy te często występujące kandydatury odpowiadają realnym cząsteczkom, zespół porównał przewidywania DeepMet z metabolitami dodanymi do Human Metabolome Database po zamknięciu danych treningowych modelu. DeepMet wygenerował już większość z tych późniejszych odkryć i przypisał wiele z nich do grona najbardziej prawdopodobnych kandydatów. Z tysięcy wysoko ocenionych struktur nieobecnych w bazach autorzy zakupili lub zsyntetyzowali 80 i sprawdzili obecność w rzeczywistych próbkach ludzkich za pomocą spektrometrii mas. Potwierdzili obecność kilku wcześniej nierozpoznanych metabolitów, niektóre z nich były wcześniej pomijane, mimo że pojawiają się w literaturze.
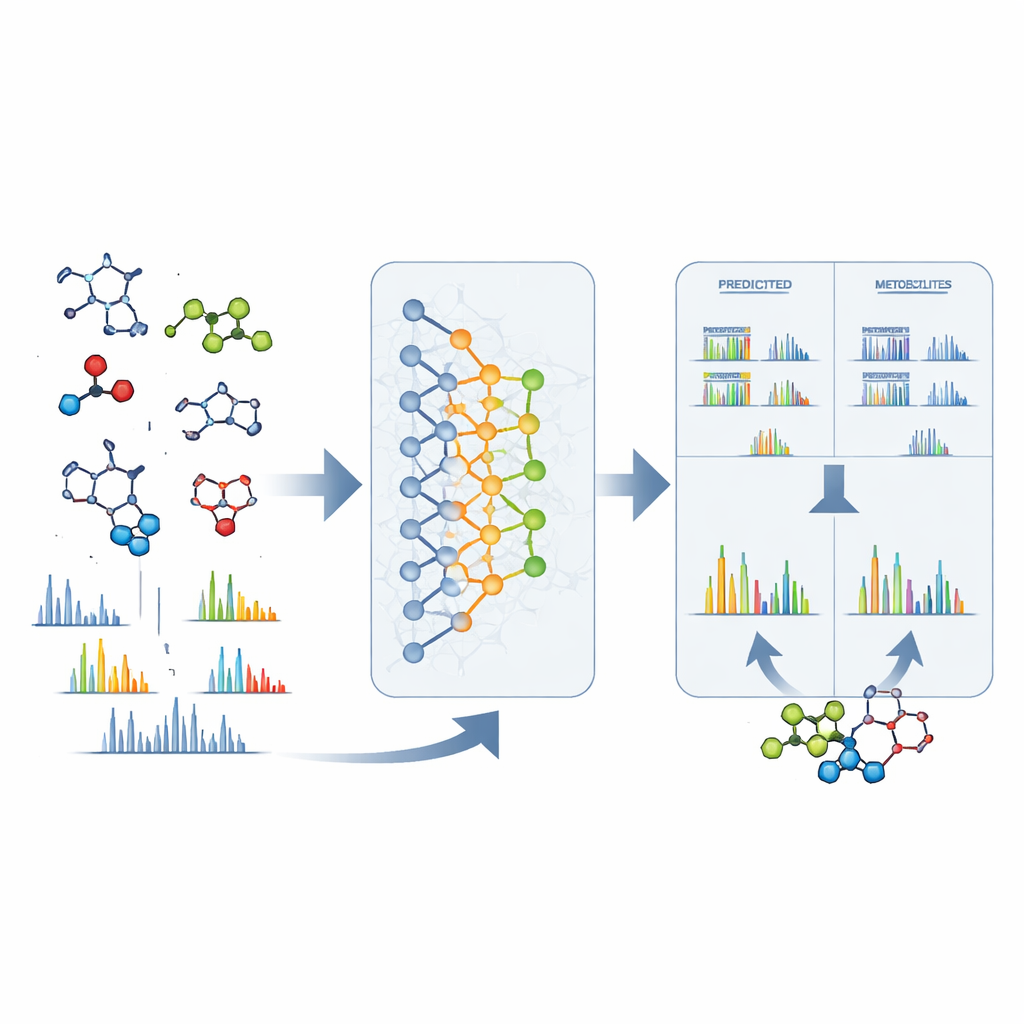
Od surowych sygnałów do konkretnych struktur
DeepMet jest również użyteczny, gdy w spektrometrze mas pojawił się nieznany pik. Mając jedynie dokładną masę tajemniczej cząsteczki, model potrafi wypisać wiele struktur o tej samej wadze i uporządkować je według tego, jak „metabolitopodobne” się wydają. W prawie jednej trzeciej przypadków testowych prawidłowa struktura znalazła się na pierwszym miejscu; w wielu pozostałych pojawiała się wśród niewielkiej liczby wysoko ocenionych kandydatów i zwykle była bardzo podobna kształtem do faworyta modelu. Aby dodatkowo zawęzić wybór, autorzy połączyli DeepMet z odrębnym oprogramowaniem przewidującym, jak każdy kandydat rozpadałby się w spektrometrze mas. Dopasowanie tych przewidywanych wzorców do rzeczywistych widm eksperymentalnych mniej więcej podwoiło dokładność identyfikacji. Przeszukiwanie dużych publicznych zestawów danych z zastosowaniem tej skojarzonej metody dało propozycje struktur dla wielu wcześniej anonimowych sygnałów i wskazało metabolity różniące się w zależności od chorób, diety i stanu mikrobiomu.
Oświetlanie metabolicznej ciemnej materii życia
Łącząc chemiczną intuicję wyuczoną z danych z potężnym dopasowywaniem wzorców do widm mas, DeepMet dostarcza mapę drogową do odkrywania nowych metabolitów w ukierunkowany, praktyczny sposób. Nie potrafi jeszcze ujawnić każdego nieznanego związku — niektóre struktury leżą zbyt daleko od tych, które widział, a niektóre izomery pozostają nierozróżnialne bez specjalistycznych metod. Jednak badanie pokazuje, że narzędzia w stylu modeli językowych mogą nie tylko wymyślać realistyczne cząsteczki, ale też przewidywać rzeczywiste związki, które biolodzy później potwierdzą u zwierząt i ludzi. Dla laika kluczowy wniosek jest taki, że AI może teraz pomagać chemikom systematycznie odsłaniać ukrytą chemię w naszych ciałach — potencjalnie ujawniając nowe markery, śledząc powiązania dieta–mikrobiom–gospodarz i stopniowo przekształcając dzisiejszą metaboliczną ciemną materię w jutro dobrze zmapowaną biologię.
Cytowanie: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Słowa kluczowe: metabolomika, chemiczne modele językowe, DeepMet, spektrometria mas, metaboliczna ciemna materia