Clear Sky Science · pl
Odkrywanie kluczowych cech pików do uwierzytelniania oliwy z oliwek przy użyciu spektroskopii Ramana i chemometrii
Dlaczego historia oszustw z oliwą ma znaczenie
Kiedy płacisz więcej za butelkę oliwy z oliwek, oczekujesz autentycznego produktu, a nie cichego rozcieńczenia tańszymi olejami roślinnymi. Ponieważ oliwa jest cenna, a handel międzynarodowy złożony, oszustwa i błędne oznakowanie są powszechnymi problemami. W tym badaniu przedstawiono szybką, niedestrukcyjną metodę wykrywania takich praktyk polegającą na naświetlaniu olejów laserem i analizie ich ukrytych chemicznych odcisków palców przy pomocy inteligentnych programów komputerowych. Podejście ma na celu ochronę konsumentów, uczciwych producentów i organów kontroli poprzez ułatwienie sprawdzania, czy zawartość butelki odpowiada temu, co podano na etykiecie.
Naświetlanie, by odczytać chemiczne odciski oleju
Naukowcy wykorzystali technikę zwaną spektroskopią Ramana, która polega na skierowaniu skupionej wiązki światła na próbkę i pomiarze, jak światło się rozprasza. Różne cząsteczki drgają na swój sposób, tworząc wzór pików w otrzymanym widmie, niczym kod kreskowy. Oliwa z oliwek i typowe substytuty, takie jak olej słonecznikowy, rzepakowy czy kukurydziany, mają różne mieszanki kwasów tłuszczowych i naturalnych barwników, więc ich widma nie są identyczne. Analizując te wzory w czystych olejach i starannie przygotowanych mieszankach, zespół mógł wyodrębnić niewielki zestaw „kluczowych pików”, których kształt i intensywność zmieniały się w sposób wiarygodny wraz ze wzrostem lub spadkiem udziału oliwy w mieszance.
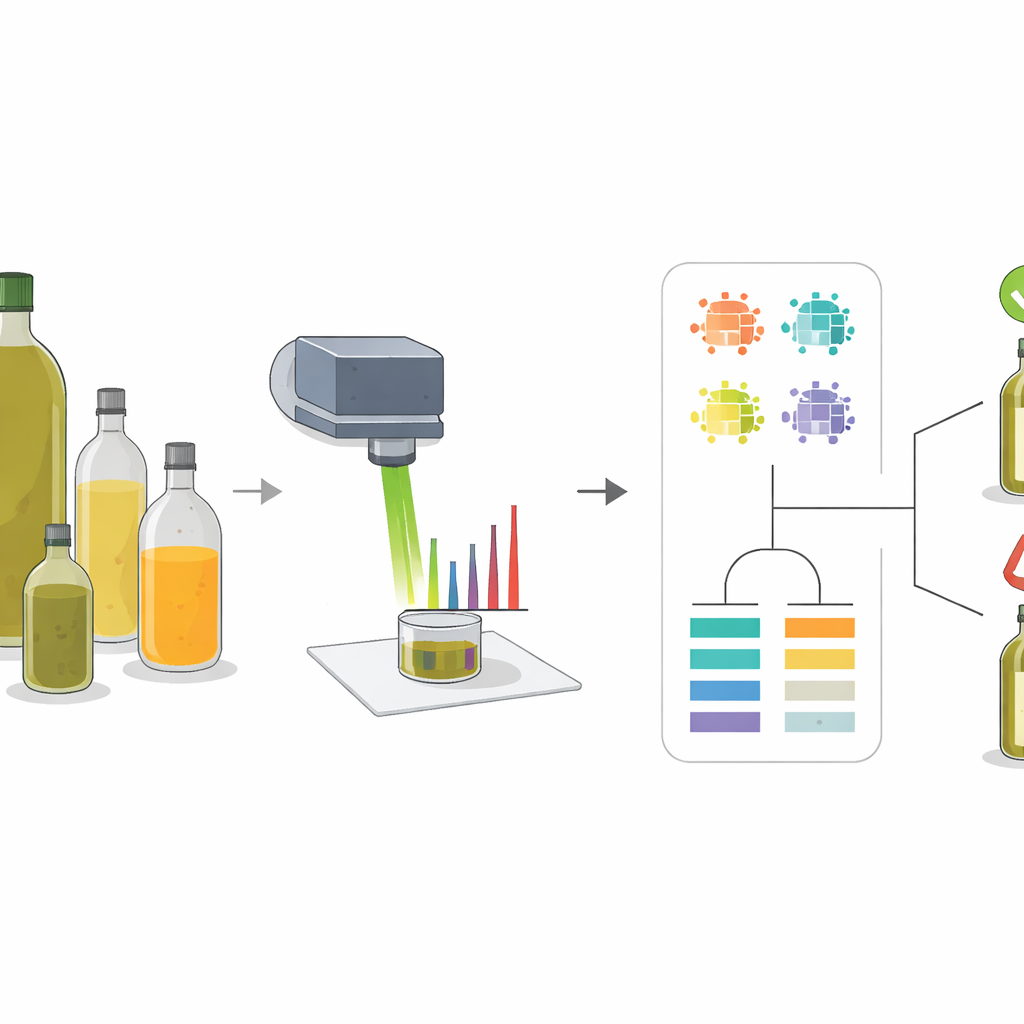
Wyszukiwanie najbardziej wymownych sygnałów
Zamiast polegać na pojedynczym pomiarze, zespół wydobył z każdego istotnego piku kilka opisników: jego wysokość (intensywność), zajmowaną powierzchnię (pole pod krzywą), szerokość na połowie wysokości oraz relację jego pola do pól innych pików. Następnie użyto metod klasteryzacji i map korelacji, by zobaczyć, jak te opisniki grupują różne oleje i jak przesuwają się w miarę zwiększania udziału oliwy. Piki związane z barwnikami, takimi jak beta-karoten, oraz z określonymi typami nienasyconych tłuszczów okazały się szczególnie informatywne. Na przykład niektóre piki wzmacniały się wraz ze wzrostem zawartości oliwy, podczas gdy inne słabły, ponieważ były powiązane z kwasem linolowym, który występuje częściej w oleju słonecznikowym. Taka wieloaspektowa analiza wychwyciła subtelne różnice, które zostałyby przeoczone, gdyby użyto tylko pojedynczej wartości intensywności.
Pozwolenie algorytmom rozróżniać uczciwe od zafałszowanego
Aby przekształcić te spektralne odciski palców w praktyczne decyzje, autorzy wytrenowali kilka modeli uczenia maszynowego. Najpierw poprosili modele o sklasyfikowanie dziesięciu typów olejów, w tym czterech olejów czystych oraz sześciu rodzajów mieszankowych binarnych i ternarnych. Metody oparte na drzewach — lasy losowe i gradientowo wzmacniane drzewa — sprawdziły się najlepiej, przypisując prawidłowo niemal wszystkie próbki do właściwej kategorii przy wykorzystaniu pełnego zestawu cech pików. Następnie ten sam typ modeli zastosowano do predykcji numerycznej: oszacowania rzeczywistego procentowego udziału oliwy w mieszankach dwu- i trzyskładnikowych. Ponownie podejścia oparte na drzewach przewyższały bardziej tradycyjne metody, dokładnie śledząc zawartość oliwy nawet wtedy, gdy sygnały różnych olejów silnie się nakładały w widmach.
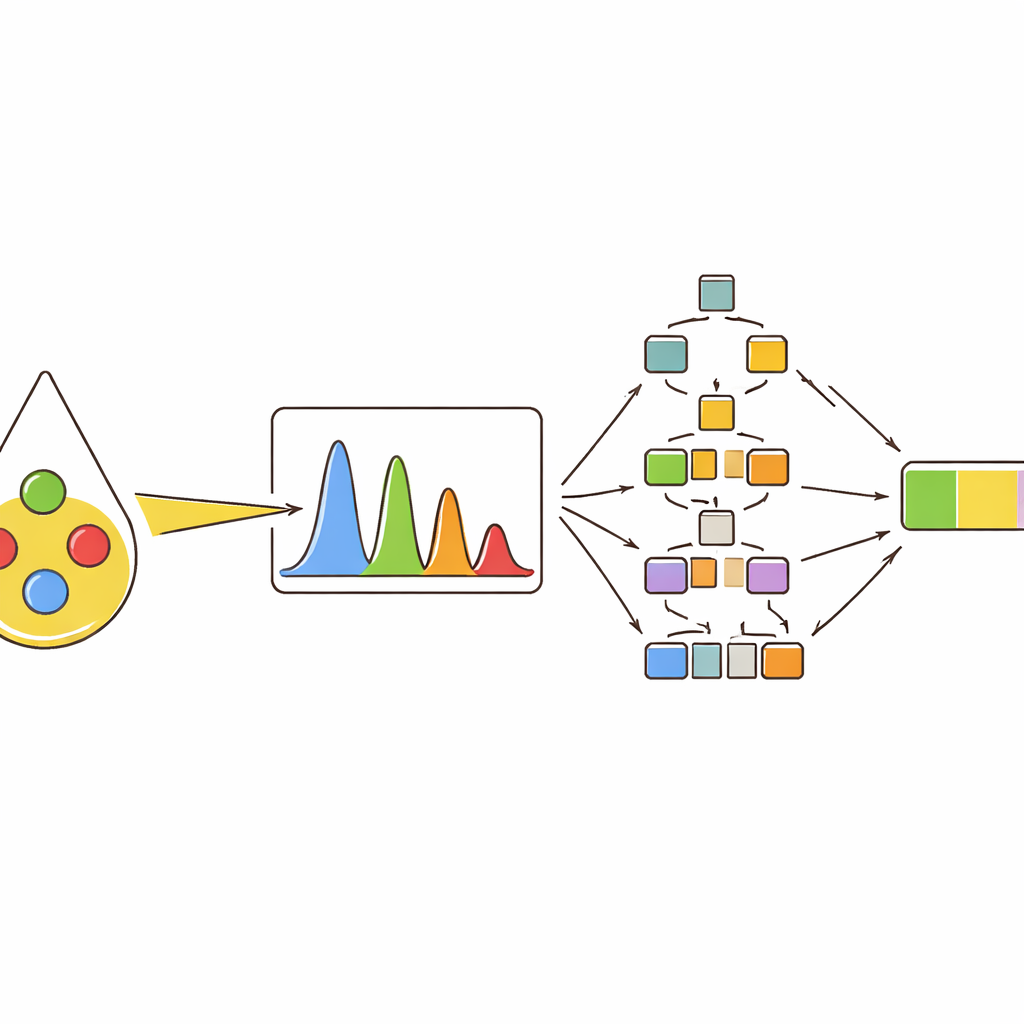
Otwieranie czarnej skrzynki inteligentnych modeli
Wiele potężnych narzędzi uczenia maszynowego jest trudnych do interpretacji; mogą działać dobrze, ale nie dają wglądu, dlaczego podjęto daną decyzję. Aby temu zaradzić, badanie zastosowało metodę wyjaśniającą, która przypisuje każdej cechy wejściowej wkład w ostateczną prognozę. Ujawniło to, że kilka specyficznych pików dominowało w ocenie modeli, konsekwentnie wpływając na przewidywaną zawartość oliwy w górę lub w dół w zależności od ich wartości. Te same piki pojawiały się jako najważniejsze w różnych typach mieszanek i w testach przeprowadzonych na komercyjnych olejach ze sklepów, które zawierały jedynie niewielką ilość oliwy. Dla tych rzeczywistych próbek najlepsze modele oszacowały zawartość oliwy bardzo blisko wartości prawdziwej, co potwierdza zarówno dokładność, jak i przejrzystość podejścia.
Co to oznacza dla butelki w twoim domu
Mówiąc prościej, praca pokazuje, że szybkie skanowanie światłem, interpretowane przez dobrze zaprojektowane i wyjaśnialne modele komputerowe, może określić, czy „oliwa z oliwek” jest czysta, mocno rozcieńczona, czy gdzieś pośrodku. Koncentrując się na kilku odpornych cechach spektralnych i łącząc je w zaawansowane, a jednocześnie interpretowalne algorytmy, badacze stworzyli narzędzie, które mogłoby zostać wdrożone w rutynowych kontrolach jakości, potencjalnie także w urządzeniach przenośnych. Choć wciąż potrzebne są szersze testy obejmujące więcej regionów, odmian i rodzajów oszustw, ta struktura wskazuje na przyszłość, w której weryfikacja uczciwości produktów wysokiej wartości, takich jak oliwa z oliwek, stanie się szybsza, prostsza i bardziej niezawodna dla wszystkich.
Cytowanie: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Słowa kluczowe: uwierzytelnianie oliwy z oliwek, wykrywanie oszustw żywnościowych, spektroskopia Ramana, uczenie maszynowe, jakość olejów spożywczych