Clear Sky Science · pl
Parametryzowany obwód kwantowy informowany statystyką: w kierunku praktycznego przygotowywania stanów kwantowych i uczenia za pomocą zasady maksymalnej entropii
Przekształcanie danych rzeczywistych w stany kwantowe
Nowoczesne komputery kwantowe obiecują duże korzyści w finansach, nauce i uczeniu maszynowym — pod warunkiem że najpierw uda się przetłumaczyć złożone, rzeczywiste dane na delikatny język stanów kwantowych. W artykule przedstawiono nową metodę takiego tłumaczenia, nazwaną statystycznie informowanym parametryzowanym obwodem kwantowym (SI-PQC). Poprzez osadzenie podstawowych wzorców danych bezpośrednio w strukturze obwodu kwantowego, SI-PQC ma na celu znacznie wydajniejsze załadowanie rozkładów prawdopodobieństwa na kubity, co czyni wiele proponowanych przyspieszeń kwantowych bardziej realistycznymi w praktyce.
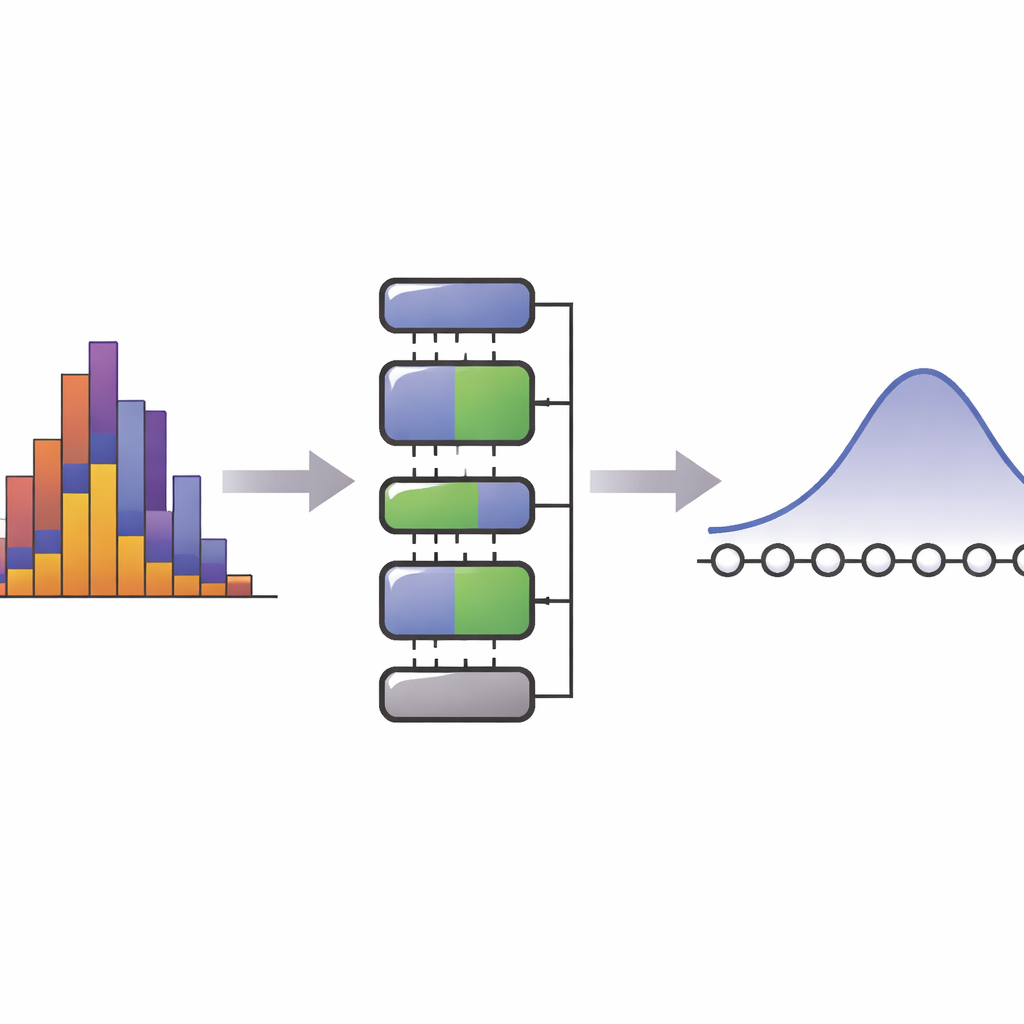
Dlaczego przekształcenie danych w formę kwantową jest trudne
Zanim algorytm kwantowy może działać, jego wejście musi być zakodowane jako stan kwantowy, którego amplitudy odpowiadają docelowemu rozkładowi prawdopodobieństwa, np. krzywej dzwonowej lub mieszance kilku pików. Zbudowanie takiego stanu w ogólności jest notoriously kosztowne: w najgorszym przypadku liczba bramek lub dodatkowych kubitów rośnie wykładniczo wraz z rozmiarem zbioru danych. Istniejące metody próbują wykorzystać modele danych — na przykład używając znanych formuł dla standardowych rozkładów lub trenując elastyczne obwody kwantowe, aby naśladowały obserwowane próbki. Jednak te podejścia często ukrywają znaczną cenę. Wymagają one znacznego wstępnego przetwarzania lub długich sesji treningowych, by przekształcić parametry modelu w ustawienia bramek, a ten narzut może skasować teoretyczne zalety samego algorytmu kwantowego, szczególnie gdy dane lub parametry modelu zmieniają się w czasie.
Wykorzystanie symetrii i niepewności jako wskazówek projektowych
Główną ideą SI-PQC jest traktowanie danych nie jako przypadkowego zbioru liczb, lecz jako coś ustrukturyzowanego przez proste „symetrie”, na przykład stałą wartość średnią czy rozrzut. Autorzy korzystają z zasady maksymalnej entropii, pojęcia ze statystyki i fizyki, które mówi: spośród wszystkich rozkładów zgodnych z niewielkim zbiorem znanych średnich, najbardziej uczciwym, najmniej stronniczym przypuszczeniem jest ten o największej entropii. Wiele znanych rozkładów — jak rozkład Gaussa — można tak rozumieć. SI-PQC dzieli informacje na dwie części. Jedna część to wiedza stała o formie modelu i zachowywanych cechach, które powinien respektować. Druga część to garść regulowanych parametrów, które uchwycają to, co nadal jest nieznane lub zmienne w danych. W obwodzie przekłada się to na warstwy stałe, które nie zmieniają się między zadaniami, oraz kompaktowy zestaw regulowanych bramek obrotu, które bezpośrednio kodują parametry modelu.
Budowa i mieszanie rozkładów kwantowych
Wykorzystując to podejście, autorzy konstruują „ładowarkę rozkładów maksymalnej entropii”, która potrafi przygotować szeroki zakres standardowych kształtów rozkładów prawdopodobieństwa na niewielkiej liczbie kubitów. Testują swoje obwody na rozkładach wykładniczym, chi-kwadrat, gaussowskim i Rayleigha, i pokazują, że poprzez dostosowanie stopnia przybliżenia wielomianowego mogą sprawić, że stan kwantowy będzie ściśle odpowiadać krzywej docelowej przy jednoczesnym utrzymaniu głębokości obwodu pod kontrolą. Wyjątkową cechą jest to, że struktura obwodu pozostaje taka sama nawet gdy parametry się zmieniają, co umożliwia ponowne użycie i agresywną optymalizację. Autorzy rozszerzają następnie pomysł na mieszanki rozkładów — sytuacje, w których niepewność parametrów opisywana jest przez inny rozkład, jak w mieszankach gaussowskich używanych w uczeniu maszynowym i finansach. Ich „ważony mikser rozkładów” potrafi zakodować zarówno obserwowane dane, jak i ukrytą przestrzeń możliwych ustawień parametrów w jednym stanie kwantowym, unikając wykładniczego wzrostu zasobów, który dotyka bardziej naiwnych konstrukcji kwantowych.
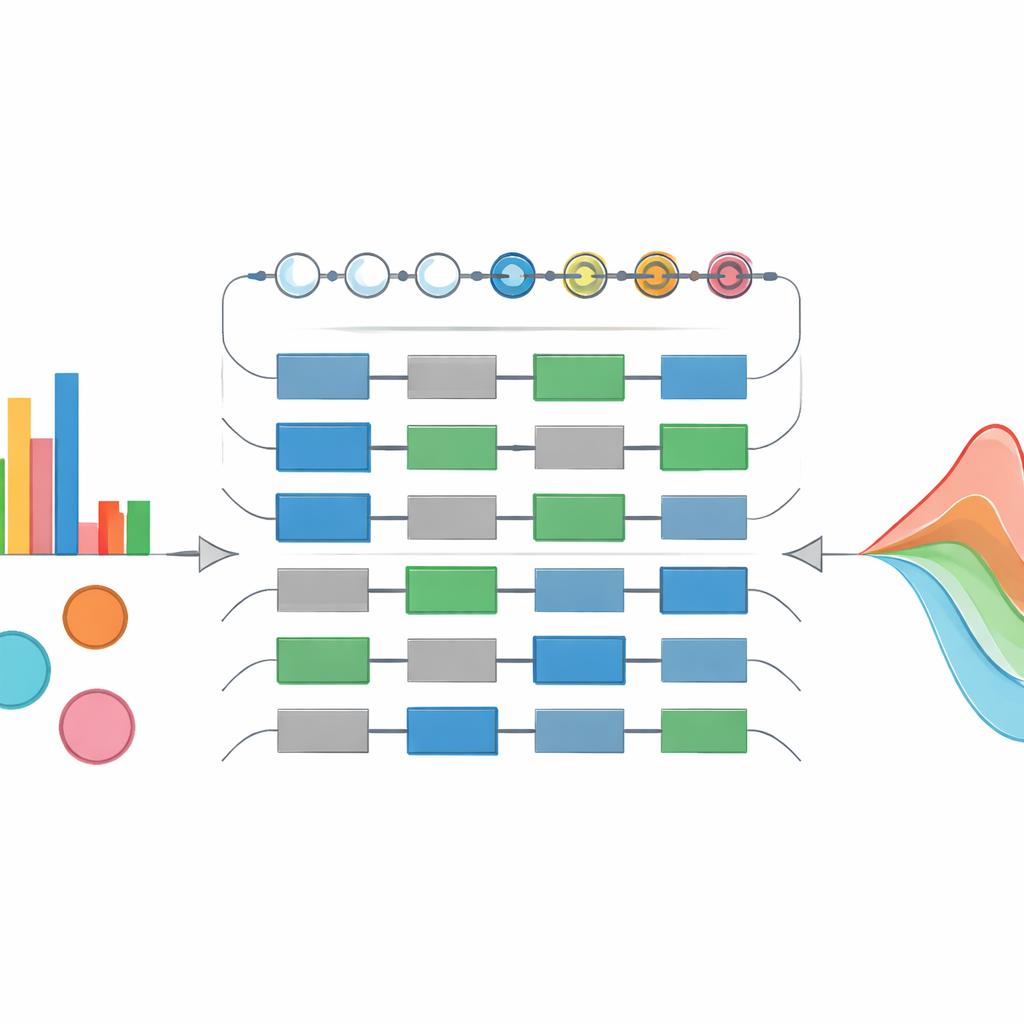
Uczenie się z danych z pomocą kwantów
Ponad przygotowywaniem stanów, SI-PQC służy również jako model uczący się z danych. Ponieważ liczba wolnych parametrów w obwodzie jest ściśle dopasowana do stopni swobody leżącego u podstaw modelu statystycznego, krajobraz treningowy jest mniejszy i bardziej interpretowalny niż w ogólnych wariacyjnych obwodach kwantowych. Autorzy demonstrują to, dopasowując mieszankę gaussowską za pomocą hybrydowej pętli kwantowo-klasycznej, która dostraja kąty obwodu, by zminimalizować odległość między przygotowanym stanem kwantowym a danymi próbkowymi. W miarę postępu treningu zarówno stan kwantowy, jak i reprezentowane przez niego parametry klasyczne (takie jak średnie i wariancje) zbliżają się do swoich prawdziwych wartości. Teoria sugeruje, że tak kompaktowe, prowadzone przez symetrię obwody powinny lepiej uogólniać, wymagać mniej próbek treningowych i być mniej podatne na płaskie, „bezpłodne” obszary, gdzie gradienty zanikają.
Praktyczne korzyści w finansach i ocenie ryzyka
Aby pokazać wpływ w świecie rzeczywistym, artykuł analizuje dwa zadania finansowe: wycenę instrumentów pochodnych i ocenę ryzyka. Wiele propozycji kwantowych w tej dziedzinie opiera się na procedurach przypominających Monte Carlo, które mogą przyspieszyć estymację oczekiwanych wypłat lub prawdopodobieństw strat — pod warunkiem że podstawowy rozkład cen można szybko przygotować na urządzeniu kwantowym. SI-PQC ostro redukuje czas przetwarzania klasycznego i głębokość części przygotowującej stan w tych algorytmach, i potrafi zaktualizować swoje parametry w stałym czasie, gdy warunki rynkowe się zmieniają, co jest kluczowe dla wyceny online i obliczania greków. Autorzy projektują także procedurę wspomaganą kwantowo do estymacji Value at Risk bezpośrednio z przesyłanych strumieniowo danych empirycznych. Tutaj proste średnie bieżące z klasycznych monitorów są używane jako ograniczenia w modelu maksymalnej entropii, który SI-PQC przekształca w przybliżoną kwantową wersję rozkładu strat w czasie rzeczywistym. Następnie kwantowa estymacja amplitudy daje miary ryzyka bliskie tym obliczanym z surowych danych.
Co to oznacza na przyszłość
Dla osób niebędących specjalistami główne przesłanie jest takie, że efektywne „ładowanie danych” jest równie istotne dla przewagi kwantowej, co szybkość samego algorytmu kwantowego. SI-PQC oferuje zasadniczy sposób na zniwelowanie tej luki, kodując proste, interpretowalne struktury statystyczne bezpośrednio w układzie obwodów kwantowych, przy zachowaniu niewielkiej i elastycznej części regulowanej. Autorzy pokazują, że ta strategia potrafi przygotowywać i uczyć złożone rozkłady, naturalnie obsługiwać mieszanki oraz znacząco zmniejszać koszty zasobów w aplikacjach finansowych. Jeśli te pomysły skalują się na przyszłym sprzęcie, mogą pomóc przesunąć obliczenia kwantowe z abstrakcyjnych obietnic w stronę praktycznych narzędzi w obszarach takich jak handel w czasie rzeczywistym, adaptacyjne uczenie maszynowe, a nawet diagnostyka medyczna — wszędzie tam, gdzie szybko zmieniające się wzorce statystyczne trzeba przechwytywać i przetwarzać z prędkością kwantową.
Cytowanie: Zhuang, XN., Chen, ZY., Xue, C. et al. Statistics-informed parameterized quantum circuit: towards practical quantum state preparation and learning via maximum entropy principle. npj Quantum Inf 12, 45 (2026). https://doi.org/10.1038/s41534-026-01191-5
Słowa kluczowe: przygotowywanie stanów kwantowych, maksymalna entropia, kwantowe uczenie maszynowe, mieszanki gaussowskie, kwantowe finanse