Clear Sky Science · pl
Predykcja długości fali emisji wspomagana eksploracją tekstu i uczeniem maszynowym oraz jej eksperymentalna weryfikacja
Przekształcanie tekstów naukowych w światło
Co roku naukowcy publikują dziesiątki tysięcy artykułów o materiałach, które świecą — substancjach stosowanych w ekranach telefonów, skanerach medycznych i detektorach promieniowania. W tych publikacjach znajdują się pomiary dokładnych kolorów emitowanych przez różne materiały, jednak informacje są rozproszone, zapisywane niespójnie i trudne do przetworzenia przez komputery. W tym badaniu pokazano, jak automatycznie odczytywać tę literaturę, przekształcać ją w dużą, wiarygodną bazę danych, a następnie używać uczenia maszynowego do przewidywania barwy światła emitowanego przez nowe materiały — pomagając badaczom projektować lepsze fosfory znacznie szybciej.
Dlaczego materiały świecące mają znaczenie
Fosfory to materiały, które pochłaniają energię i ponownie emitują ją jako światło widzialne. Są kluczowe dla technologii takich jak wyświetlacze o bardzo wysokiej rozdzielczości, białe diody LED, obrazowanie medyczne i detekcja promieniowania. Inżynierowie potrzebują fosforów emitujących bardzo określone barwy, utrzymujących jasność w wysokich temperaturach i marnujących jak najmniej energii. W ciągu ostatnich dwóch dekad badania nad tymi materiałami eksplodowały, wypełniając literaturę naukową szczegółowymi raportami o recepturach chemicznych i długościach fal emisji. Jednak te dane są w większości zamknięte w nieustrukturyzowanym tekście — zdaniach w akapitach, podpisach i częściach eksperymentalnych pisanych dla ludzi, nie dla maszyn. 
Nauczanie komputerów czytania artykułów o materiałach
Autorzy zbudowali wyspecjalizowany pipeline do eksploracji tekstu dopasowany do literatury o fosforach. Zamiast korzystać z ogólnych narzędzi językowych, opracowali reguły rozumiejące, jak chemicy faktycznie zapisują wzory, zwłaszcza dla materiałów „domieszkowanych”, gdzie do matrycy dodaje się niewielką ilość innego pierwiastka. Ich system potrafi poprawnie rozpoznać złożone nazwy, takie jak sieć gospodarza z kilkoma jonami domieszkowymi i ich stężeniami, oraz powiązać te nazwy z pobliskimi liczbami reprezentującymi długości fal emisji. Radzi sobie też z trudniejszym językiem, na przykład zdaniami mówiącymi „emituje przy 630 nm” bez powtórzenia nazwy materiału, albo akapitami, gdzie wymienionych jest kilka materiałów i kilka długości fal. Poprzez klasyfikację każdego zdania według liczby zawartych materiałów i własności, a następnie wybór algorytmu dopasowującego do danej sytuacji, pipeline znacznie zmniejsza pomyłki przy przypisywaniu, która liczba należy do którego materiału.
Budowanie czystej mapy składu na kolor
Stosując ten pipeline do 16 659 artykułów, zespół wyekstrahował około 6 400 wiarygodnych par „materiał–emisja”: wzór fosforu, długość fali emisji w maksimum, jednostkę oraz cyfrowy identyfikator artykułu. Dokładne testy wykazały wysoką trafność zarówno w rozpoznawaniu pełnych wzorów fosforów, jak i w łączeniu ich z właściwymi wartościami emisji. Mając tę ustrukturyzowaną bazę danych, badacze skupili się na jednej szczególnie istotnej rodzinie: materiałach domieszkowanych jonami europu (Eu2+), które mogą emitować w szerokim zakresie widma widzialnego w zależności od otaczającej struktury krystalicznej. Obliczyli fizycznie znaczące deskryptory dla każdego gospodarza — takie jak szczegóły struktury krystalicznej, długości wiązań i przerwa energetyczna pasma przewodnictwa — a następnie użyli metod selekcji cech, by zawęzić je do kilku najważniejszych dla przewidywania koloru.
Pozwalając uczeniu maszynowemu przewidzieć blask
Następnie autorzy wytrenowali i porównali kilka modeli uczenia maszynowego do przewidywania długości fali emisji na podstawie tych deskryptorów. Algorytm zwany XGBoost wypadł najlepiej, osiągając współczynnik determinacji (R²) około 0,91 na niewidzianych wcześniej danych testowych — mocny dowód, że model wychwytuje kluczowe zależności między strukturą a kolorem. Aby sprawdzić działanie podejścia w praktyce, użyli modelu do zaproponowania obiecujących nowych fosforów siarkowych i azotkowych domieszkowanych Eu2+, zsyntezowali cztery kandydaty w laboratorium i zmierzyli ich emisję. Zaobserwowane długości fal różniły się od predykcji tylko o około 10 nanometrów, co oznacza, że „przewidywania” modelu były bardzo bliskie rzeczywistości eksperymentalnej. 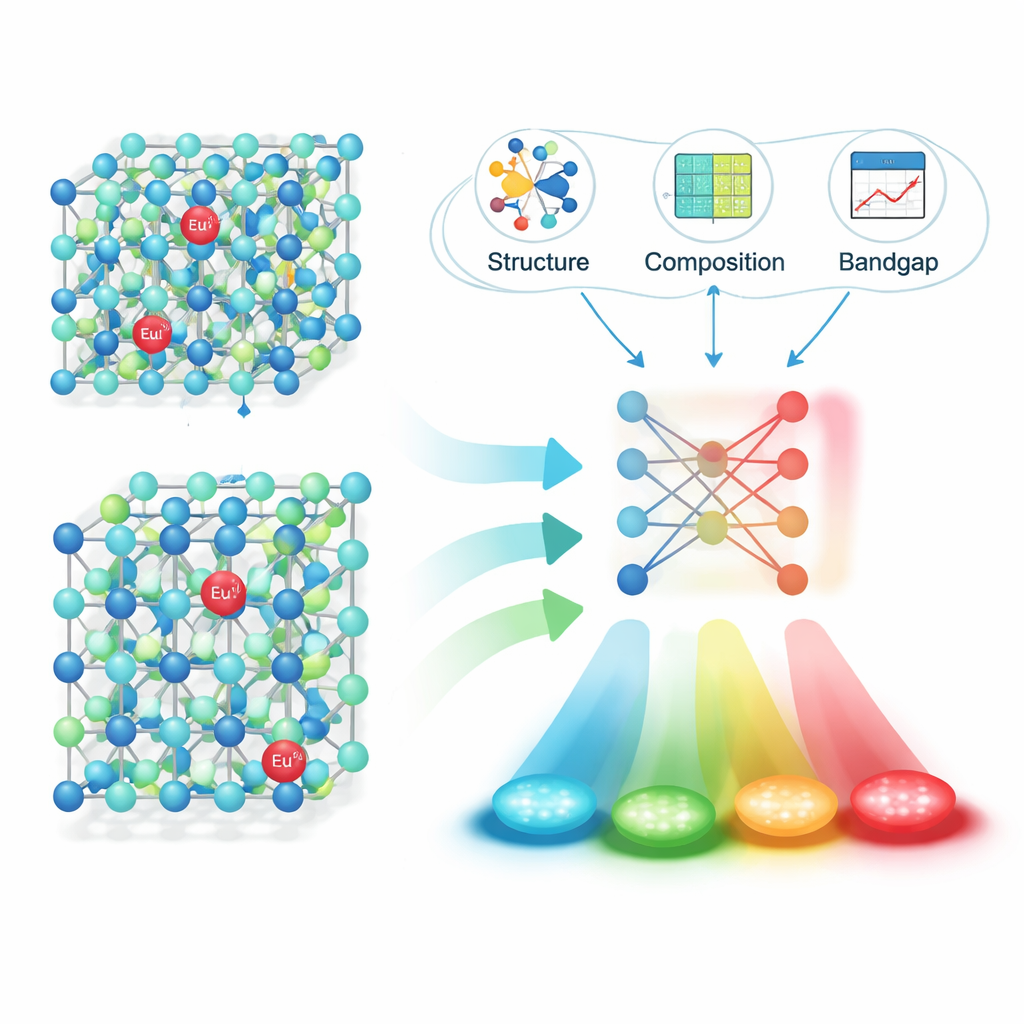
Z artykułów do praktycznych projektów
Dla osób niebędących specjalistami główne przesłanie jest takie: ta praca przekształca rozproszone, pisane przez ludzi artykuły w spójną, przeszukiwalną mapę łączącą „z czego zrobiony jest materiał” z „jakiego koloru jest jego blask”. Automatyzując kroki czytania, porządkowania i uczenia — a następnie potwierdzając predykcje za pomocą rzeczywistych eksperymentów — badanie pokazuje zamkniętą pętlę: tekst → dane → model → nowy materiał. Ramy te można rozszerzyć na inne właściwości, takie jak jasność czy stabilność, a nawet na inne klasy materiałów funkcyjnych. W ten sposób wskazują kierunek, w którym zamiast pracy metodą prób i błędów w laboratorium, naukowcy będą mogli szybko zawęzić pole do najbardziej obiecujących receptur, przyspieszając rozwój lepszych technologii oświetleniowych, wyświetlaczy i czujników.
Cytowanie: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
Słowa kluczowe: materiały luminescencyjne, eksploracja tekstu, uczenie maszynowe, fosfory, predykcja długości fali emisji