Clear Sky Science · pl
Zestaw danych fMRI przy 7T z obrazami syntetycznymi do modelowania poza dystrybucją w widzeniu
Dlaczego to ma znaczenie dla rozumienia widzenia i AI
Nasze oczy rejestrują codziennie ogromną różnorodność obrazów — od lasów i twarzy po znaki drogowe i szumy ekranowe. Tymczasem wiele badań nad mózgiem i sztuczną inteligencją opiera się na wąskim wycinku tego świata wzrokowego: fotografiach scen naturalnych. Ten artykuł wprowadza nowy typ zbioru danych mózgowych, który celowo wychodzi poza tę strefę komfortu, używając starannie zaprojektowanych obrazów syntetycznych, aby postawić na próbę zarówno nasze teorie ludzkiego widzenia, jak i inspirowane nim modele AI.
Budowanie nowej płyty testowej dla widzenia
Autorzy rozszerzają wpływowy Natural Scenes Dataset (NSD), który rejestrował aktywność mózgu w ultra‑wysokiej rozdzielczości przy użyciu rezonansu magnetycznego 7 tesli, podczas oglądania przez badanych dziesiątek tysięcy fotografii. Ten oryginalny zbiór danych już zasilił niektóre z najdokładniejszych modeli opisujących, jak kora wzrokowa reaguje na obrazy. Ponieważ jednak wszystkie te obrazy to stosunkowo zwyczajne zdjęcia, trudno stwierdzić, czy model dobrze działający na NSD rzeczywiście uchwycił ogólne zasady widzenia, czy raczej wyspecjalizował się pod kątem tego konkretnego „menu” obrazów. Aby to zbadać, zespół ponownie zeskanował tych samych ośmiu ochotników, tym razem pokazując im 284 „syntetyczne” obrazy, które świadomie wychodzą poza zwykły świat fotografii.
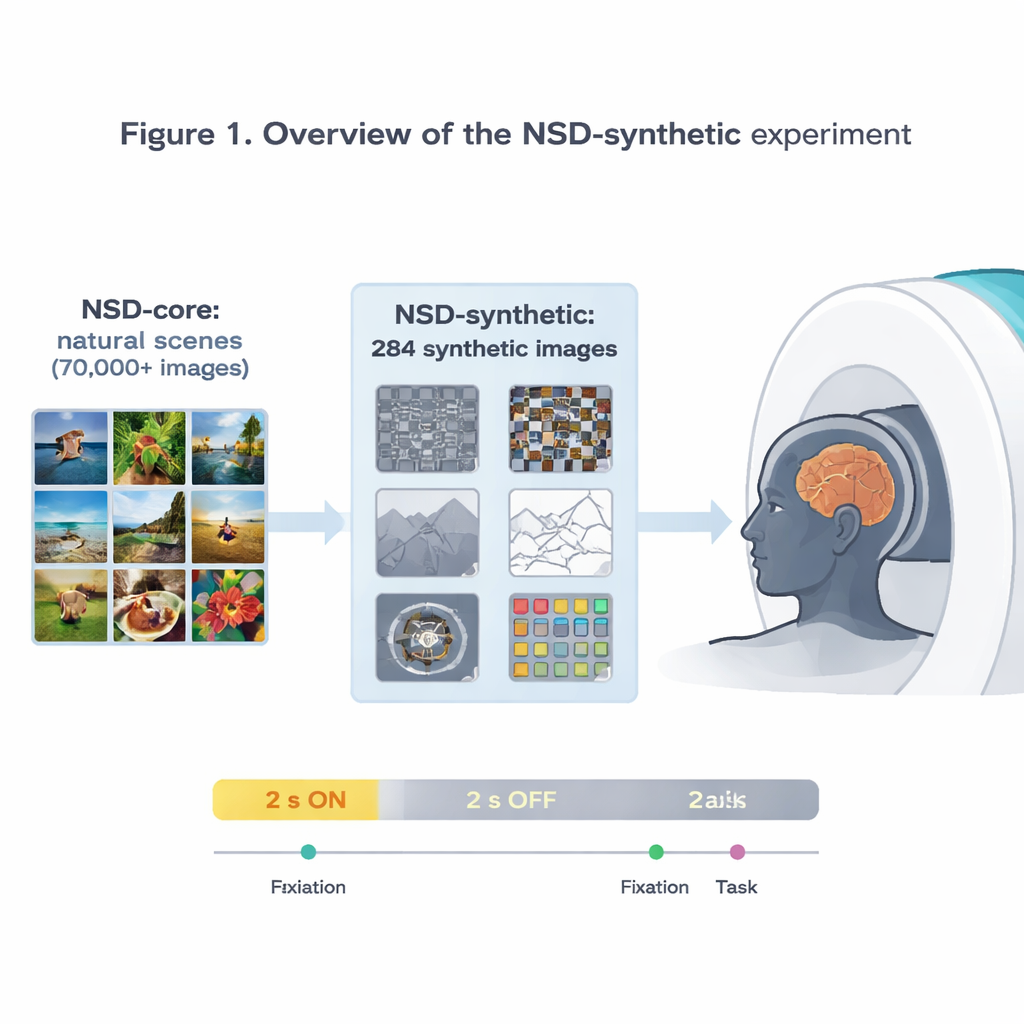
Dziwne obrazy, wiarygodne odpowiedzi mózgu
Obrazy syntetyczne obejmują osiem rodzin: różne rodzaje szumu wizualnego, proste sceny naturalne i ich zmodyfikowane wersje (np. do góry nogami lub rysunki liniowe), sceny o obniżonym kontraście lub ze zniekształconą fazą, pojedyncze słowa umieszczone w różnych lokalizacjach, spiralne graty, które badają czułość na drobne wzory, oraz jasno zabarwione łatki szumowe. Gdy osoby obserwowały małą migającą kropkę lub wykonywały proste zadanie porównania obrazów, badacze mierzyli aktywność mózgu co 1,6 sekundy. Pokazują, że te nietypowe bodźce wciąż wywołują silne, wiarygodne sygnały, szczególnie w wczesnych obszarach wzrokowych reagujących na podstawowe cechy, takie jak krawędzie, kontrast i kolor. Wzory aktywności w korze odpowiadają dobrze znanym preferencjom wyspecjalizowanych obszarów — na przykład obszar wybiórczy względem słów reaguje najmocniej na słowa umieszczone centralnie, a obszar wybiórczy względem scen na obrazy środowisk.
Udowadnianie, że dane są naprawdę „poza dystrybucją”
Aby ten nowy zestaw danych rzeczywiście rzucał wyzwanie modelom, jego odpowiedzi mózgowe muszą być zasadniczo inne niż te wywoływane przez fotografie naturalne. Autorzy kompresują wzory aktywności zarówno z oryginalnego NSD, jak i sesji z obrazami syntetycznymi do mapy dwuwymiarowej, która odzwierciedla, jak podobne są odpowiedzi między obrazami. W tej przestrzeni odpowiedzi na obrazy syntetyczne grupują się oddzielnie od odpowiedzi na zdjęcia naturalne, nawet po uwzględnieniu różnic między sesjami skanowania. Co więcej, obrazy syntetyczne naturalnie grupują się według typu wizualnego — szum z szumem, graty z gratami itd. — co pokazuje, że mózg organizuje te bodźce zgodnie z ich strukturą leżącą u podstaw, a nie tylko powierzchownym wyglądem.
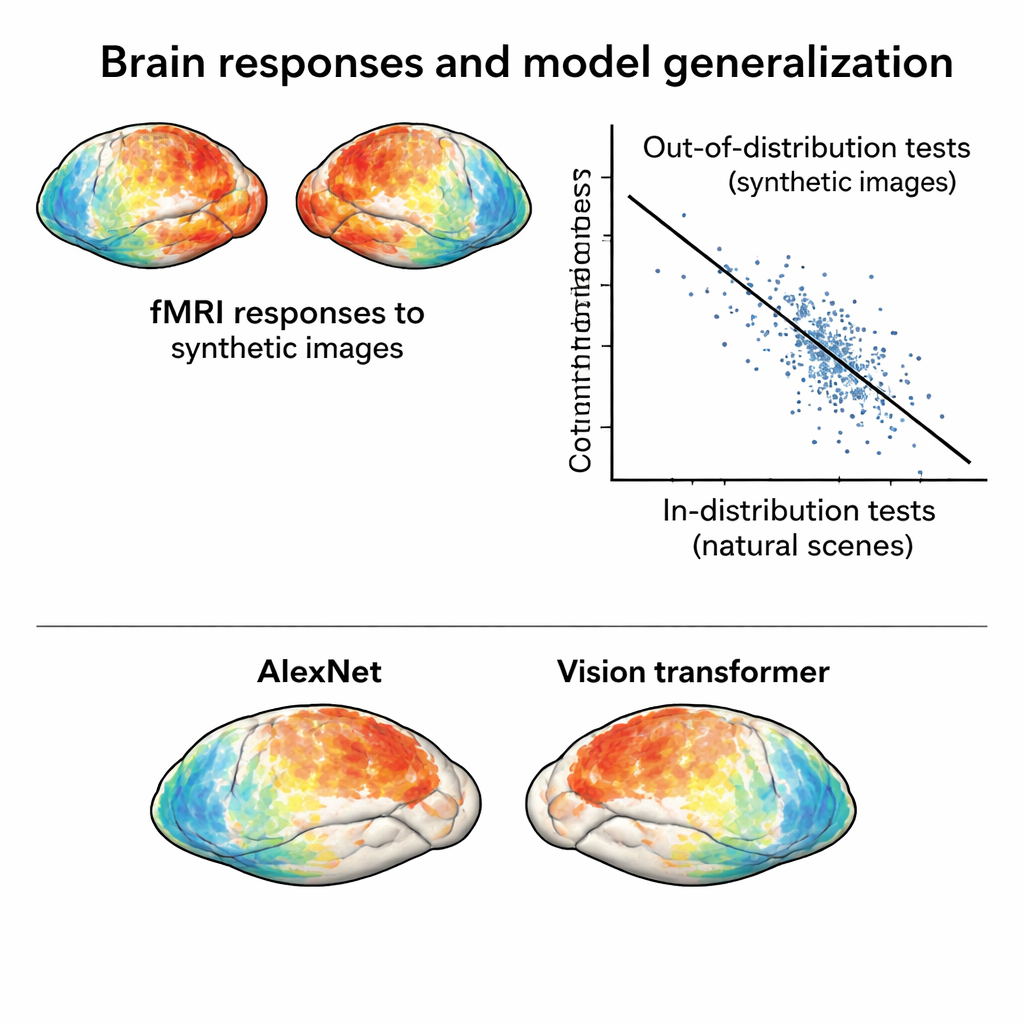
Wystawianie modeli mózgu i AI na trudniejszą próbę
Majac w ręku ten nowy zestaw danych „poza dystrybucją”, zespół trenuje standardowe modele kodujące: narzędzia matematyczne przewidujące odpowiedzi mózgowe na podstawie cech obrazu wyekstrahowanych przez głębokie sieci neuronowe. Modele trenowane tylko na naturalnych fotografiach radzą sobie dobrze przy testach na podobnych zdjęciach, ale ich dokładność wyraźnie spada przy przewidywaniu odpowiedzi na obrazy syntetyczne. Ta utrata wydajności nie wynika z zaszumionych danych — odpowiedzi na obrazy syntetyczne są wręcz bardzo czyste — lecz z rzeczywistych błędów modeli. Co istotne, porównanie różnych architektur sieci neuronowych w tych surowszych warunkach ujawnia różnice, które ledwie występują w testach zgodnych z dystrybucją. Na przykład nowoczesny transformer wzrokowy i sieć uczona w sposób samonadzorowany przewyższają klasyczne sieci splotowe wobec obrazów syntetycznych, co sugeruje, że sposób treningu modelu silnie determinuje jego odporność.
Jak daleko od znanych obrazów mogą się posunąć modele?
Autorzy idą dalej i traktują „odległość” od danych treningowych jako kontinuum, a nie etykietę tak/nie. Mierzą, jak daleko odpowiedź mózgowa dla każdego obrazu leży od chmury odpowiedzi na sceny naturalne. Im dalej obraz syntetyczny znajduje się w tej przestrzeni, tym słabiej modele zazwyczaj działają i tym mniej precyzyjnie można zidentyfikować, który obraz widziała osoba na podstawie samej aktywności mózgu. Pokazują też, że nawet w świecie zwykłych fotografii sprytnie dobrane zbiory testowe mogą zachowywać się jako „umiarkowanie poza dystrybucją”: modele osiągają najlepsze wyniki na obrazach pochodzących z tego samego skupiska co ich zestaw treningowy, gorzej na odległych scenach naturalnych, a najgorzej na bodźcach syntetycznych. Ten stopniowany obraz czyni nowy zbiór danych narzędziem do badania, jakich typów struktur wizualnych obecne modele nie uchwytują.
Co to znaczy dla przyszłych badań nad mózgiem i AI
Dla osób niebędących specjalistami kluczowy przekaz jest taki: dobre wyniki na znanych obrazach nie gwarantują, że inspirowany mózgiem model AI naprawdę uchwycił to, jak postrzegamy świat. Udostępniając NSD‑synthetic obok oryginalnego NSD, autorzy dostarczają publiczny „tor testowy” dla modeli widzenia — sposób, by zobaczyć, gdzie się załamują, gdy obrazy stają się bardziej abstrakcyjne, bardziej kolorowe lub mniej naturalne. Ponieważ zbiór danych jest otwarcie dostępny i ściśle zintegrowany z istniejącym, szeroko używanym zasobem, prawdopodobnie stanie się standardowym benchmarkiem do testowania i poprawiania teorii widzenia ludzkiego oraz sieci sztucznych dążących do jego naśladowania.
Cytowanie: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Słowa kluczowe: kora wzrokowa, zestaw danych fMRI, obrazy syntetyczne, poza dystrybucją, głębokie sieci neuronowe