Clear Sky Science · pl
Uczenie bez sprzężenia zwrotnego w postaci wzoru zamkniętego za pomocą projekcji w przód
Nauczanie maszyn bez wiadomości zwrotnych
Współczesna sztuczna inteligencja w dużej mierze uczy się metodą zwaną wsteczną propagacją błędu, w której sygnały błędu są przesyłane wstecz przez sieć, aby dostosować jej wewnętrzne połączenia. Ten proces różni się jednak od działania prawdziwych mózgów i może być powolny oraz wymagający zasobów. W artykule wprowadzono nowy sposób uczenia sieci neuronowych, nazwany Projekcją w Przód, który pomija etap wsteczny, a mimo to osiąga wysoką wydajność, zwłaszcza w trudnych zadaniach biomedycznych z ograniczoną ilością danych.
Nowy sposób kierowania uczeniem
Tradycyjne sieci neuronowe uczą się, porównując swoje przewidywania z prawidłowymi odpowiedziami i przesyłając sygnały błędu wstecz przez wszystkie warstwy, aby dopracować połączenia. Projekcja w Przód obiera inną drogę. Zamiast polegać na tych wstecznych komunikatach o błędzie, wykorzystuje tylko informacje dostępne podczas przesyłania sygnałów naprzód: aktywność bieżącej warstwy oraz etykietę docelową. W każdej warstwie metoda łączy wejście do tej warstwy i pożądaną etykietę za pomocą ustalonych losowych projekcji przepuszczonych przez prostą nieliniowość. Powstaje w ten sposób „celowy” sygnał wewnętrzny dla danej warstwy — wzorzec przypominający potencjały, który warstwa powinna próbować odwzorować.
Gdy te cele zostaną utworzone, wagi połączeń każdej warstwy są wyznaczane jednorazowo za pomocą regresji w postaci zamkniętej, standardnego wzoru statystycznego zamiast iteracyjnego spadku gradientu. Oznacza to, że sieć można wytrenować podczas pojedynczego przejścia przez zbiór danych, bez wielokrotnego powracania do tych samych przykładów czy przechowywania dużej liczby pośrednich aktywacji. Ponieważ żadna informacja nie musi podróżować wstecz, metoda respektuje jednokierunkową komunikację obserwowaną w neuronach biologicznych i może być łatwiejsza do wdrożenia na specjalizowanym sprzęcie z połączeniami jednokierunkowymi.
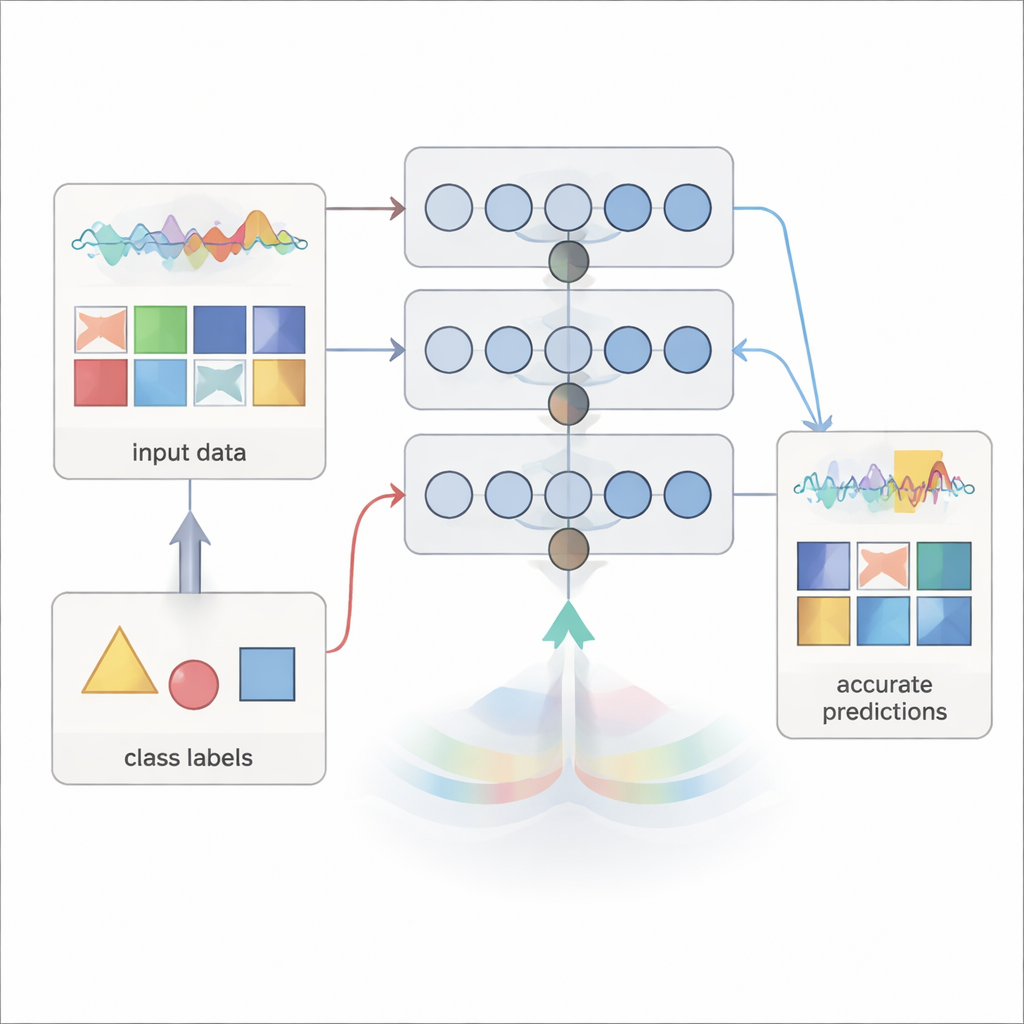
Dostrzeganie znaczenia w ukrytej aktywności
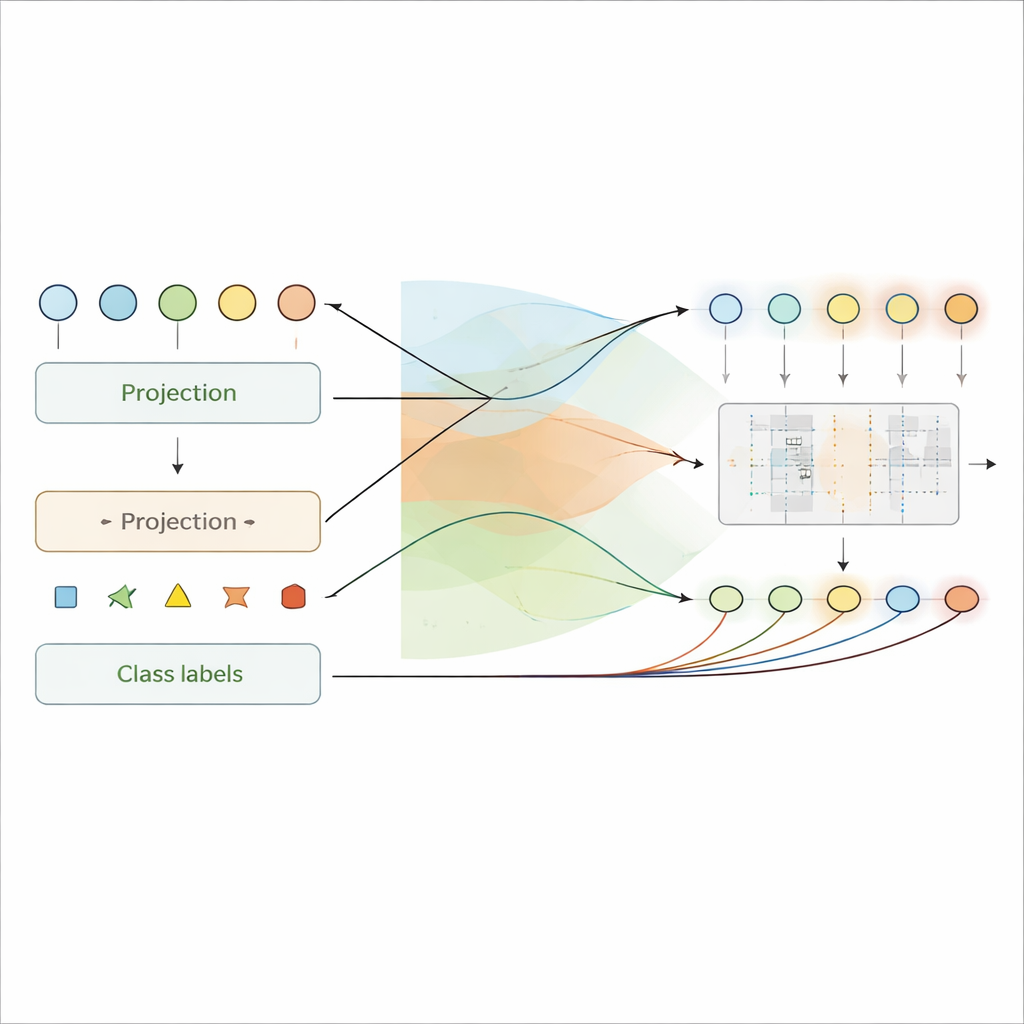
Uderzającą zaletą Projekcji w Przód jest to, że sygnały wewnętrzne w ukrytych warstwach stają się bezpośrednio interpretowalne. Ponieważ każda warstwa jest jawnie trenowana do kodowania zarówno wejścia, jak i etykiety w swoich potencjałach membranowych, wartości te można odczytywać jako lokalne przewidywania klasy. Autorzy pokazują, jak w przybliżeniu „dekodować” te sygnały z powrotem do przestrzeni etykiet, przekształcając wzorce aktywności w warstwowe wyjaśnienia tego, w co sieć wierzy na poszczególnych etapach. W eksperymentach wyjaśnienia te stają się dokładniejsze w głębszych warstwach, odzwierciedlając stopniowe uczenie się — wczesne warstwy wychwytują szerokie wzorce, podczas gdy warstwy późniejsze skupiają się na detalach krytycznych dla decyzji.
Ta interpretowalność jest szczególnie cenna w medycynie, gdzie zrozumienie, dlaczego model podjął decyzję, może być równie ważne jak sama decyzja. Na danych z elektrokardiogramów autorzy pokazują, że Projekcja w Przód uwydatnia klinicznie znane oznaki zawału serca — takie jak zmiany w określonych segmentach przebiegu fali — we właściwych momentach czasowych. Na skanach oka używanych do wykrywania nieprawidłowego wzrostu naczyń metoda naturalnie koncentruje się na kieszonkach płynu, jasnych złogach i obszarach przypominających blizny, na które zwracają uwagę specjaliści, nawet gdy trening przeprowadzono przy zaledwie 100 przykładach na klasę.
Szybki trening, mocne wyniki
Zespół porównał Projekcję w Przód z kilkoma alternatywami, które również próbują unikać pełnej wstecznej propagacji, oraz ze standardową wsteczną propagacją. W zadaniach obrazowych i sekwencyjnych, takich jak cyfry z Fashion-MNIST, rozpoznawanie promotorów DNA, wykrywanie zawału na podstawie elektrokardiogramów i rozpoznawanie obiektów, nowa metoda dorównywała lub przewyższała wydajność innych reguł lokalnego uczenia. W standardowych ustawieniach wsteczna propagacja nadal miała ogólną przewagę, lecz dokładność Projekcji w Przód była zaskakująco bliska, przy jednoczesnym wykorzystaniu jedynie pojedynczego przebiegu treningowego.
Korzyści były wyraźniejsze w scenariuszach „few-shot”, gdzie dostępna jest tylko garstka oznaczonych przykładów, co jest powszechne w praktyce klinicznej. Tutaj Projekcja w Przód często uogólniała lepiej niż zarówno wsteczna propagacja, jak i konkurencyjne metody lokalne na zdjęciach klatki piersiowej, skanach siatkówki i małych podzbiorach obrazów. Wsteczna propagacja miała tendencję do przeuczenia się na malutkich zbiorach danych lub nieuczenia się wystarczająco bogatych cech, podczas gdy Projekcja w Przód wytwarzała bardziej stabilne, nadające się do ponownego użycia reprezentacje wewnętrzne. Z punktu widzenia obliczeniowego trenowanie dużej warstwy wymagało znacznie mniej operacji mnożenia i dodawania niż uruchomienie wielu epok wstecznej propagacji, co przekładało się na istotne przyspieszenia i niższe koszty energetyczne.
Co to oznacza dla przyszłej sztucznej inteligencji i obliczeń inspirowanych mózgiem
Mówiąc prosto, praca ta pokazuje, że sieci neuronowe nie muszą polegać na ciężkich, biologicznie nieprawdopodobnych pętlach sprzężenia zwrotnego, aby nauczyć się użytecznych i zrozumiałych reprezentacji wewnętrznych. Poprzez sprytne łączenie wejść i etykiet w pojedynczym przejściu w przód i rozwiązywanie wag w postaci zamkniętej, Projekcja w Przód oferuje sposób na szybkie trenowanie modeli, interpretowanie ich działania i obsługę małych, zaszumionych zbiorów danych biomedycznych. Chociaż wsteczna propagacja pozostaje złotym standardem w wielu zadaniach na dużą skalę, podejście pozbawione sprzężenia zwrotnego wskazuje drogę ku bardziej mózgopodobnym i przyjaznym dla sprzętu strategiom uczenia, które mogą stać się podstawą następnej generacji wydajnych, wyjaśnialnych systemów AI.
Cytowanie: O’Shea, R., Rajendran, B. Closed-form feedback-free learning with forward projection. Nat Commun 17, 2414 (2026). https://doi.org/10.1038/s41467-026-69161-1
Słowa kluczowe: uczenie bez sprzężenia zwrotnego, sieci neuronowe, trening z niewielką liczbą próbek, biomedyczna sztuczna inteligencja, wyjaśnialne uczenie głębokie