Clear Sky Science · pl
Profilowanie wieloomiczne oparte na AI ujawnia komplementarne wkłady omik do spersonalizowanej predykcji chorób sercowo‑naczyniowych
Dlaczego wcześniejsze przewidywanie problemów sercowych ma znaczenie
Choroby serca i udary pozostają głównymi zabójcami na świecie, często atakując pozornie zdrowe osoby bez ostrzeżenia. Lekarze już korzystają z list kontrolnych obejmujących wiek, ciśnienie krwi, cholesterol i palenie, aby ocenić ryzyko, ale te narzędzia mogą przeoczyć wielu przyszłych chorych i zawyżać ryzyko u innych. To badanie stawia aktualne pytanie: czy, zaglądając głębiej w molekuły krążące we krwi i analizując je za pomocą sztucznej inteligencji, możemy wykryć choroby sercowo‑naczyniowe na wiele lat przed ich wystąpieniem — i spersonalizować profilaktykę dla każdej osoby?
Szukając ukrytych znaków ostrzegawczych we krwi
Naukowcy skorzystali z zasobów UK Biobank, ogromnego projektu zdrowotnego śledzącego setki tysięcy ochotników przez wiele lat. Dla podzbioru uczestników dokładnie zmierzono tysiące molekuł w próbkach krwi: małe metabolity związane z tłuszczami, cukrami i aminokwasami oraz białka uczestniczące w zapaleniu, krzepnięciu i innych procesach organizmu. Zespół skupił się na sześciu głównych schorzeniach sercowo‑naczyniowych — chorobie wieńcowej, udarze, niewydolności serca, migotaniu przedsionków, chorobie tętnic obwodowych i zakrzepach żylnych — by sprawdzić, czy te molekularne odciski palców mogą przewidzieć, kto rozwinie które schorzenie.
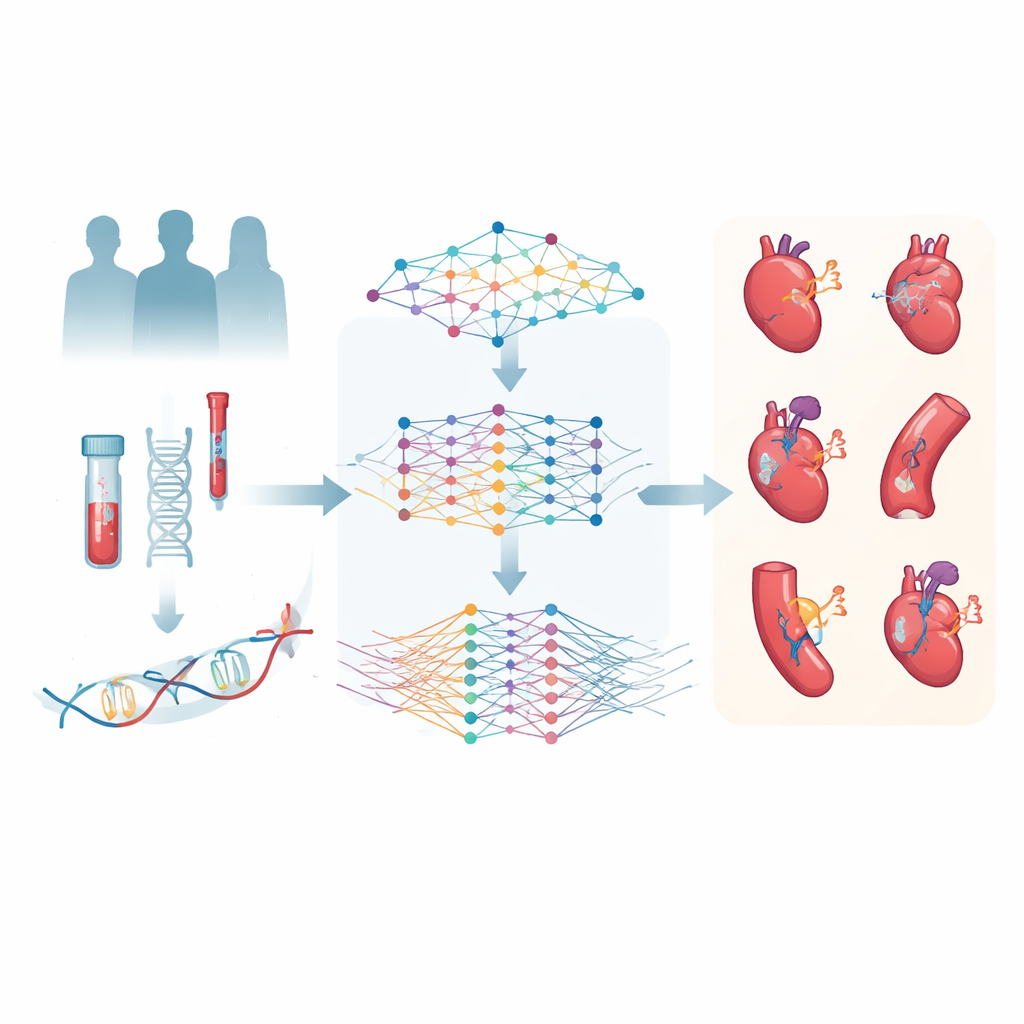
Uczenie sztucznej inteligencji rozpoznawania wzorców molekularnych
Aby zrozumieć prawie 3 000 białek i 168 metabolitów, autorzy zbudowali dwa modele głębokiego uczenia: MetNet i ProNet. Zamiast przewidywać jedną chorobę na raz, modele te uczyły się wzorców powiązanych ze wszystkimi sześcioma wynikami sercowo‑naczyniowymi jednocześnie. Z danych metabolitowych MetNet wygenerował skumulowany wynik ryzyka nazwany MetScore; z danych białkowych ProNet wygenerował ProScore. Każda osoba otrzymała zatem po sześć wyników dla każdego systemu — po jednym dla każdego typu choroby sercowo‑naczyniowej — podsumowując miliony możliwych interakcji molekularnych do garści liczb, które standardowy model statystyczny mógł wykorzystać obok wieku, ciśnienia krwi, leków i ryzyka genetycznego.
O ile lepsze są te molekularne wskaźniki ryzyka?
Gdy zespół przetestował wyniki na niezależnej grupie 24 287 osób, dla których dostępne były wszystkie typy danych, zarówno MetScore, jak i ProScore okazały się silnymi predyktorami samodzielnie, wyraźnie dzieląc uczestników na grupy niskiego, średniego i wysokiego ryzyka w okresie 15 lat obserwacji. Wskaźniki oparte na białkach wypadły najlepiej, często przewyższając tradycyjne miary ryzyka poligenowego (oparte na DNA) z dużą przewagą. Dodanie ProScore i MetScore do konwencjonalnych czynników klinicznych poprawiło dokładność prognozowania ryzyka dla każdego badanych rezultatów sercowo‑naczyniowych, nawet gdy modele bazowe były już szczegółowe. W niektórych przypadkach, szczególnie dla choroby tętnic obwodowych i migotania przedsionków, wzrost wydajności był znaczący, a analizy decision‑curve sugerowały, że lekarze mogliby podejmować korzystniejsze decyzje dotyczące tego, kto powinien otrzymać leczenie zapobiegawcze.
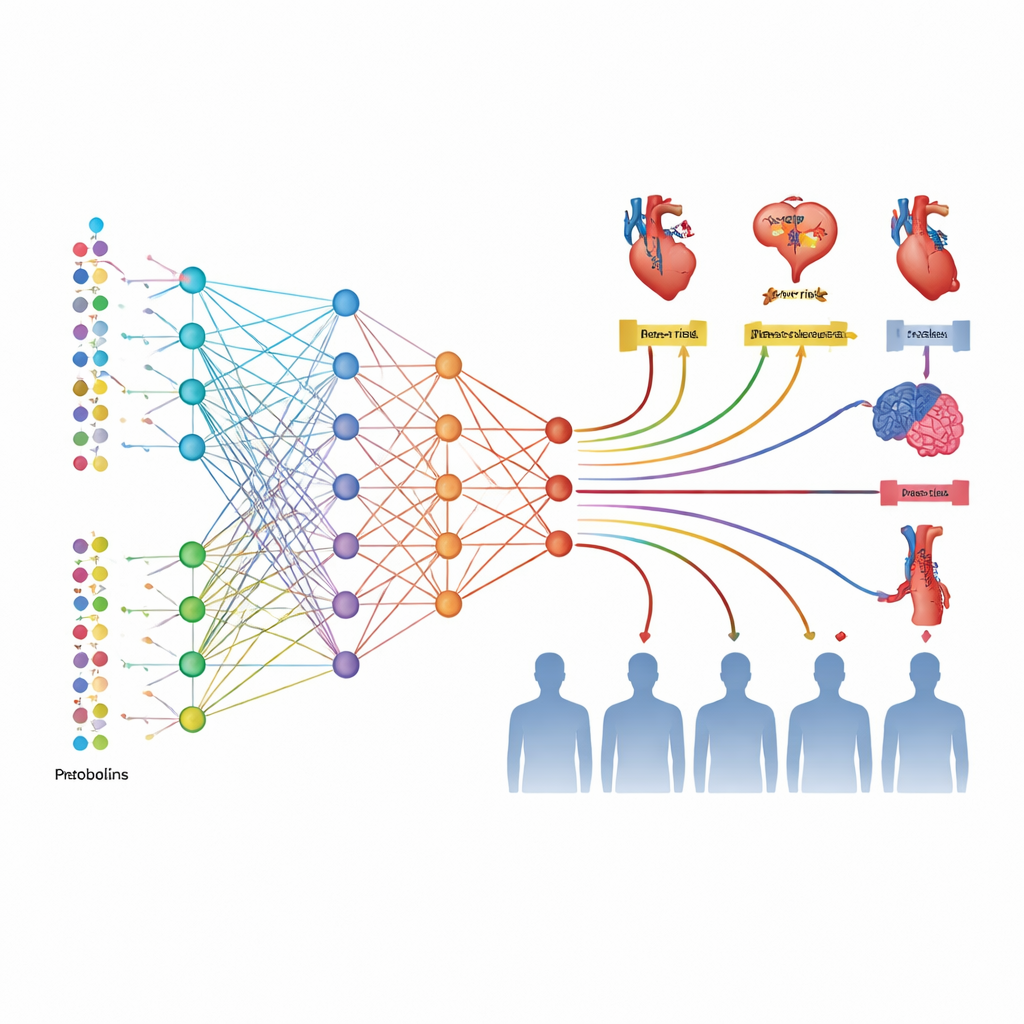
Co molekuły mówią o biologii choroby
Ponad samą predykcją, badacze sprawdzili, które konkretne molekuły miały największy wpływ na modele AI, używając metody wyjaśniającej SHAP. Potwierdzili wagę dobrze znanych markerów, takich jak kreatynina i albumina (odzwierciedlające funkcję nerek i stan ogólny), a także sygnałów zapalnych jak GlycA oraz białek związanych ze stresem serca, takich jak NT‑proBNP. Jednocześnie modele uwypukliły mniej znane białka i metabolity powiązane z zapaleniem, krzepnięciem, przebudową naczyń, a nawet uszkodzeniem nerwów, z częściowo wspólnymi, a częściowo specyficznymi dla chorób wzorcami. Co ciekawe, żaden pojedynczy związek nie dorównywał mocy predykcyjnej skumulowanego MetScore czy ProScore, co podkreśla, że ryzyko sercowo‑naczyniowe wynika z wielu subtelnych zmian działających razem, a nie z jednej przyczyny.
Z dużych danych do bardziej spersonalizowanej opieki sercowej
Autorzy wnioskują, że łączenie genetyki, szczegółowych molekularnych profili krwi i rutynowych informacji klinicznych może istotnie poprawić naszą zdolność przewidywania, kto prawdopodobnie rozwinie poważne choroby sercowo‑naczyniowe, często z wyprzedzeniem dziesięciu lub więcej lat. Szczególnie pomiary białek wydają się nieść bogate, użyteczne informacje o trwającym stresie biologicznym na długo przed pojawieniem się objawów. Chociaż wymagane testy nie są jeszcze powszechne ani tanie, koszty maleją, a autorzy udostępnili podejście CardiOmicScore jako prototypowe narzędzie. Przy dalszej walidacji w bardziej zróżnicowanych populacjach takie wieloomiczne profilowanie sterowane AI mogłoby pomóc klinicystom przejść od uniwersalnych list kontrolnych do naprawdę spersonalizowanej prewencji — identyfikując wcześniej osoby wysokiego ryzyka, dopasowując leczenie do leżącej u podstaw biologii i potencjalnie zmniejszając globalne obciążenie chorobami serca i naczyń.
Cytowanie: Luo, Y., Zhang, N., Yang, J. et al. AI-based multiomics profiling reveals complementary omics contributions to personalized prediction of cardiovascular disease. Nat Commun 17, 2269 (2026). https://doi.org/10.1038/s41467-026-68956-6
Słowa kluczowe: prognozowanie ryzyka sercowo‑naczyniowego, proteomika, metabolomika, uczenie głębokie, biomarkery