Clear Sky Science · pl
Kompulacyjne mechanizmy pojedynczych neuronów kodowania obiektów wzrokowych w ludzkim płacie skroniowym
Jak mózg wie, na co patrzymy
Za każdym razem, gdy spojrzysz na zatłoczoną ulicę, twój mózg natychmiast rozpoznaje, które kształty należą do ludzi, które do samochodów, a które do znaków, nawet jeśli są częściowo zasłonięte lub nietypowo oświetlone. Artykuł stawia pozornie proste pytanie: jak ludzki mózg przekształca potok surowych danych wzrokowych padających na oczy w stabilne pojęcia takie jak „pies” czy „kubek”, które możemy rozpoznać, zapamiętać i opisać?
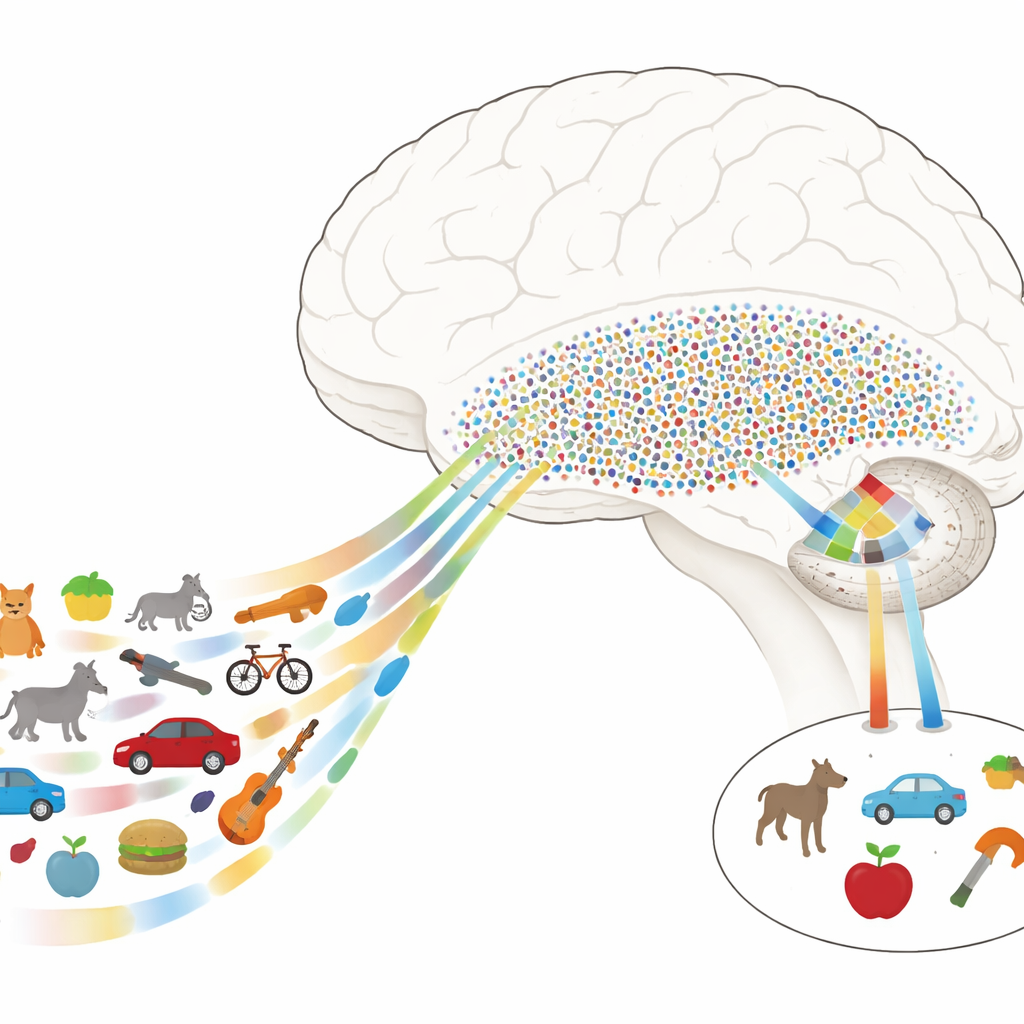
Od szczegółowego obrazu do sensownych obiektów
Naukowcy wiedzą, że rozpoznawanie obiektów opiera się w dużej mierze na łańcuchu obszarów położonych na spodniej stronie mózgu, zwanym brzuszną drogą wzrokową. Wczesne stadia przetwarzają proste cechy takie jak krawędzie i faktury, natomiast późniejsze etapy zajmują się bardziej całymi obiektami i ich znaczeniem. U ludzi kluczowym odcinkiem tej drogi jest brzuszna kora skroniowa (VTC), a niedaleko za nią leży przyśrodkowy płat skroniowy (MTL), który odgrywa istotną rolę w pamięci. Tajemnicą pozostawało, jak mózg przechodzi od szczegółowych, obrazowych opisów VTC do oszczędnych, pojęciowych kodów MTL, które pozwalają kilku neuronom reprezentować wiele różnych widoków tego samego obiektu.
Neuronowa mapa przestrzeni obiektów
Autorzy rejestrowali aktywność elektryczną bezpośrednio z mózgów pacjentów z padaczką, u których z medycznych powodów wszczepiono wcześniej elektrody. Podczas wykonywania prostego zadania pacjenci oglądali setki naturalnych obrazów z różnych kategorii — zwierzęta, narzędzia, jedzenie, pojazdy, rośliny i inne. W VTC badacze odkryli, że odpowiedzi można opisać jako kombinacje kilku kluczowych kierunków cech, czy „osi”, takich jak stopień naturalności versus sztuczności albo żywości versus bezożywności. Poprzez matematyczne łączenie tych osi zbudowali „neuronową przestrzeń cech”, w której każdy obraz zajmuje określone położenie, a podobne obiekty grupują się razem nawet jeśli różnią się drobnymi, niskopoziomowymi szczegółami.
Od gęstej siatki cech do oszczędnych centrów pojęciowych
W tej neuronowej przestrzeni VTC działa jak gęsta siatka: wiele miejsc uczestniczy w reprezentacji każdego obiektu, kodując drobne różnice wizualne. W przeciwieństwie do tego neurony rejestrowane pojedynczo w MTL zachowywały się zupełnie inaczej. Zamiast śledzić pojedyncze cechy, wiele z tych komórek odpowiadało silnie tylko na obiekty mieszczące się w określonych regionach przestrzeni cech VTC. Każdy taki neuron miał efektywnie „pole recepcyjne” nie w przestrzeni fizycznej, lecz w tej abstrakcyjnej mapie właściwości obiektów. Obiekty trafiające do preferowanego regionu neuronu często dzieliły cechy percepcyjne (np. zaokrąglone kształty czy zielonkawe barwy) oraz wyższego rzędu znaczenia (np. bycie istotami żywymi lub narzędziami), co powodowało, że dany neuron reagował rzadko, lecz selektywnie.
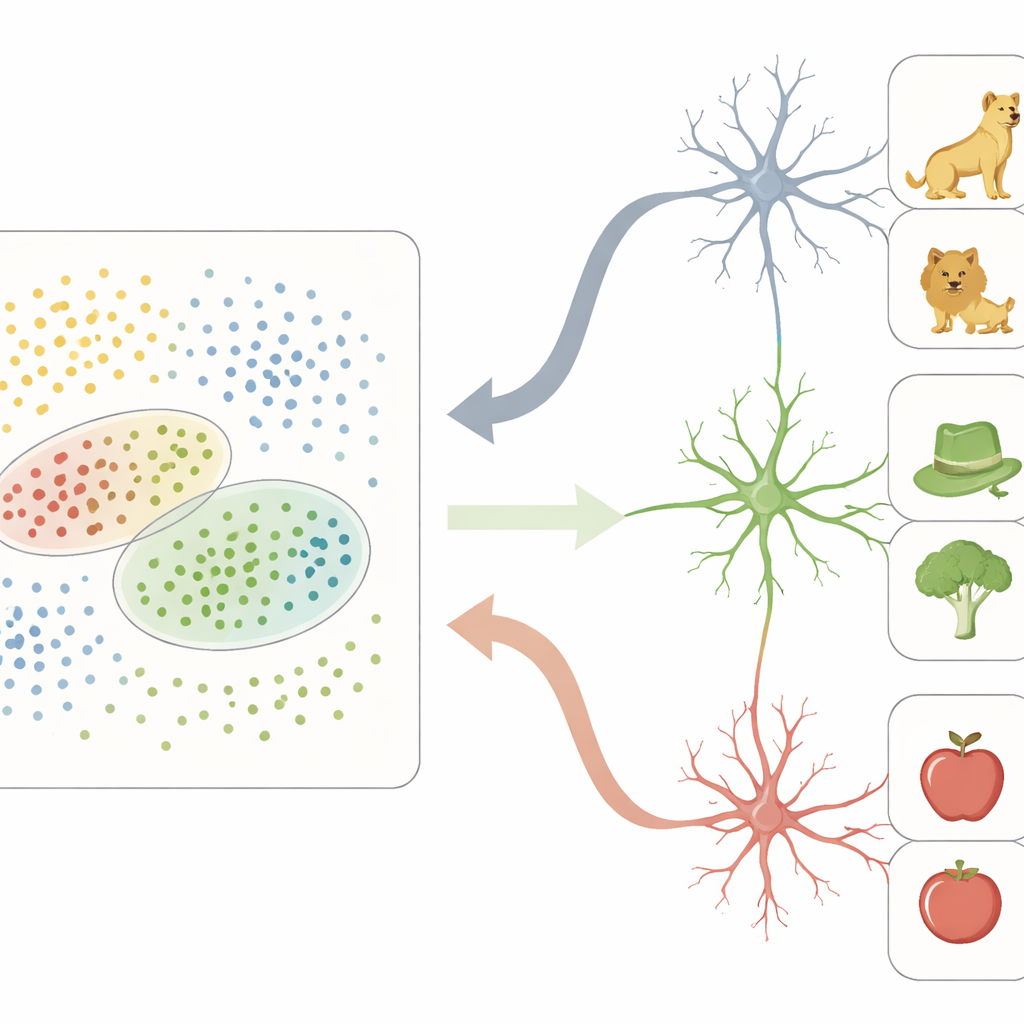
Powiązanie widzenia z pamięcią
Aby pokazać, że to nie tylko matematyczny trick, zespół sprawdził, jak te obszary mózgu wchodzą ze sobą w interakcje w czasie rzeczywistym. Stwierdzili, że miejsca VTC niosące silne sygnały osi cech były szczególnie zsynchronizowane z regionalnymi miejscami w MTL wrażliwymi na kategorie, zwłaszcza w określonych rytmicznych falach mózgowych. Informacja miała tendencję do przepływu z VTC do MTL na niższych częstotliwościach związanych z przetwarzaniem feedforward, natomiast sprzężenie zwrotne z MTL do VTC odbywało się na nieco wyższych częstotliwościach. Co ważne, gdy neuron MTL był strojony na konkretny region przestrzeni cech, jego rozładowania synchronizowały się z szybkimi rytmami w VTC, a to sprzężenie było silniejsze dla tych obrazów, które dany neuron reprezentował. Drugi zestaw eksperymentów z inną kolekcją obrazów potwierdził, że zarówno mapa cech VTC, jak i strojenie regionów w MTL były stabilne między zestawami bodźców.
Dlaczego to ma znaczenie dla codziennego widzenia i pamiętania
Wyniki razem wspierają konkretną, obliczeniową opowieść: VTC rozciąga obiekty wzrokowe wzdłuż sensownych osi cech, tworząc bogaty, ciągły krajobraz, a MTL umieszcza małe, selektywne „wskaźniki” na regionach tej mapy. Ta transformacja zamienia szczegółowy, rozproszony kod obrazowy w oszczędny kod pojęciowy, który łatwiej przechowywać, przywoływać i łączyć z innymi wspomnieniami. Dla czytelnika niebędącego specjalistą wniosek jest taki, że rozpoznanie psa w deszczową noc nie jest prostym wyszukaniem, lecz wynikiem wielowarstwowego, współdziałającego procesu, w którym jedna część mózgu buduje uporządkowaną mapę wyglądów, a inna uczy się zaznaczać i odczytywać regiony tej mapy jako odrębne, trwałe pojęcia.
Cytowanie: Cao, R., Zhang, J., Zheng, J. et al. Computational single-neuron mechanisms of visual object coding in the human temporal lobe. Nat Commun 17, 2234 (2026). https://doi.org/10.1038/s41467-026-68954-8
Słowa kluczowe: rozpoznawanie obiektów, brzuszna kora skroniowa, przyśrodkowy płat skroniowy, kodowanie neuronalne, pamięć wzrokowa