Clear Sky Science · pl
Diament DNA formułuje dekomponowalny model konstelacji liter złożonych do przechowywania danych w DNA
Dlaczego przyszłe dane mogą być przechowywane w DNA
Nasze telefony, firmy i instrumenty naukowe generują dane znacznie szybciej, niż mogą rosnąć pojemności dysków twardych i taśm magnetycznych. DNA — ta sama cząsteczka, która przenosi informację genetyczną w organizmach żywych — może również służyć do zapisywania plików cyfrowych w niezwykle zwartej i trwałej formie. W artykule tym zaprezentowano nowy sposób upakowania jeszcze większej ilości informacji w syntetycznych łańcuchach DNA, zachowując jednocześnie praktyczność i niezawodność odczytu, co potencjalnie może obniżyć koszty i zwiększyć skalowalność przechowywania w DNA.
Od czterech liter DNA do bogatszych mieszanin
Tradycyjne przechowywanie w DNA wykorzystuje cztery naturalne zasady — A, T, G i C — do reprezentowania bitów cyfrowych, podobnie jak zera i jedynki na dysku. W takim schemacie każda pozycja w łańcuchu DNA może przenosić maksymalnie dwa bity informacji, ponieważ ograniczona jest do jednego z czterech wyborów. Autorzy rozbudowują pojawiającą się ideę: zamiast umieszczać pojedynczą zasadę na każdej pozycji, tworzą precyzyjnie kontrolowane mieszaniny zasad, zwane literami złożonymi. Na przykład pozycja może być wykonana z mieszaniny A i T w stosunku 50:50 lub z równomiernej mieszaniny wszystkich czterech zasad 25:25:25:25. Gdy syntetyzuje się wiele kopii każdego łańcucha, sekwencjonowanie tych mieszanin ujawnia proporcje zasad, a w konsekwencji symbol cyfrowy, który może reprezentować więcej niż dwa bity.
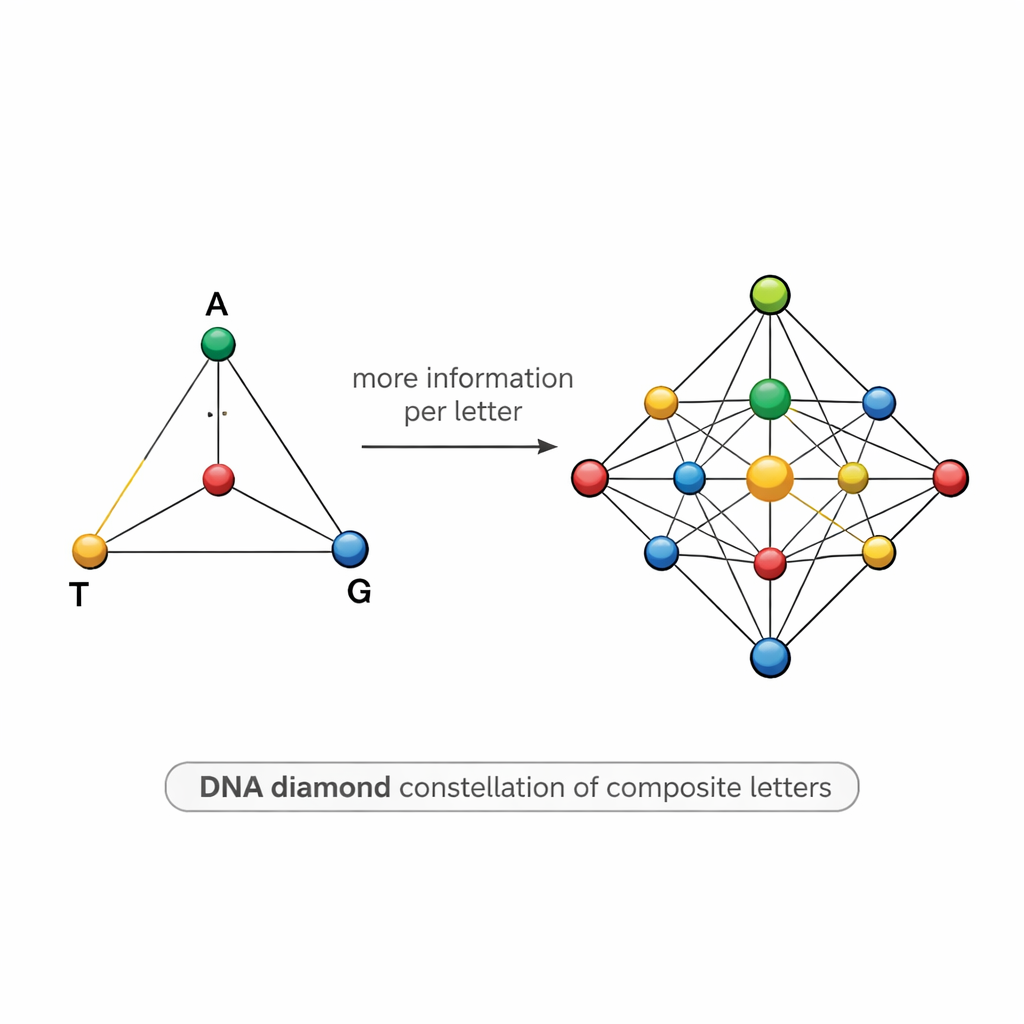
Mapa symboli DNA w kształcie diamentu
Projektowanie takich mieszanin jest trudne. Jeśli dwa symbole są zbyt podobne — na przykład jeden to 50% A i 50% T, a inny 55% A i 45% T — szum w sekwencjonowaniu może je zlać, powodując błędy i zmuszając naukowców do sekwencjonowania znacznie większej liczby kopii niż by tego chcieli. Aby temu zaradzić, zespół proponuje ustrukturyzowany model „diamentu DNA”: zestaw 15 liter złożonych rozmieszczonych jak punkty na tetraedrze, którego wierzchołki to A, T, G i C. Zestaw obejmuje czyste zasady na wierzchołkach, równe mieszaniny dwóch zasad wzdłuż krawędzi, mieszaniny trzech zasad na każdej ścianie oraz idealnie równą mieszaninę wszystkich czterech zasad w środku. Starannie dobrana konstelacja podnosi teoretyczną ilość informacji na pozycję do około 3,9 bitu, przy jednoczesnym utrzymaniu symboli wystarczająco rozróżnialnych w praktyce.
Mądrzejsze dekodowanie z entropią i indeksowaniem
Odczyt danych z DNA oznacza wnioskowanie, która litera złożona była zamierzona na danej pozycji na podstawie zaszumionych pomiarów częstotliwości zasad. Autorzy zapożyczają strategię z telekomunikacji zwaną partycjonowaniem zbioru. Najpierw sprawdzają, jak „zmieszana” wydaje się pozycja, używając miary zwanej entropią, która jest niska dla czystych zasad i wyższa dla złożonych mieszanin. To szybkie przypisuje każdą pozycję do jednej z czterech grup: czyste zasady, mieszaniny dwu‑zasadowe, mieszaniny trzy‑zasadowe lub mieszanina cztero‑zasadowa. Następnie, w obrębie wybranej grupy, bardziej precyzyjne obliczenie wiarygodności wybiera najbardziej prawdopodobną literę. To dwuetapowe podejście zmniejsza zamieszanie między symbolami i skraca czas obliczeń w porównaniu z wcześniejszymi metodami. Aby dodatkowo zapobiec pomyłkom między łańcuchami, każda cząstka DNA niesie zabezpieczone przed błędami sekwencje indeksujące na obu końcach, a odczyty o niewłaściwej długości — często spowodowane błędami wstawień lub delecji — są odfiltrowywane przed dekodowaniem.
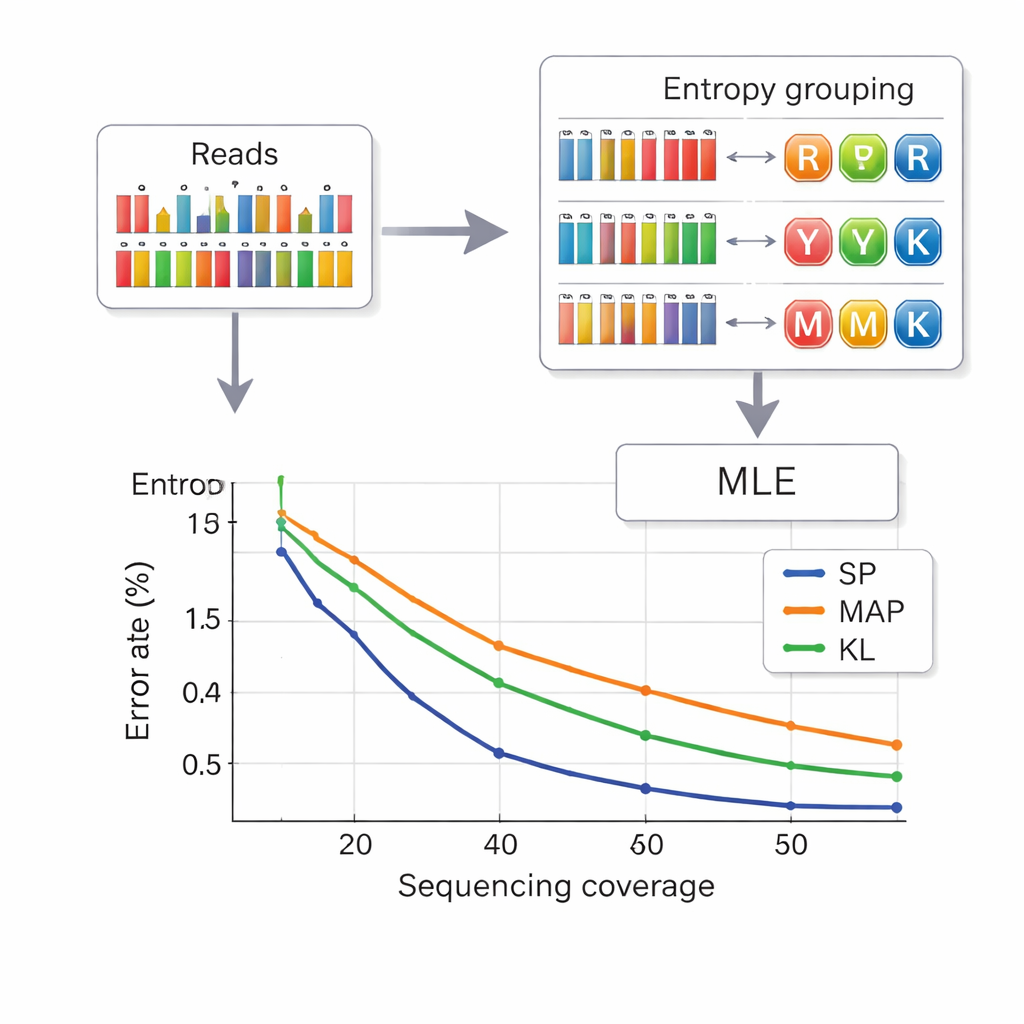
Więcej danych przy mniejszej liczbie odczytów
Naukowcy przetestowali swój system zarówno na małych, jak i dużych pulach DNA, wykorzystując komercyjne platformy syntezy. Przy ośmio‑literowym alfabecie złożonym osiągnęli gęstość ładunku 2,5 bita na pozycję DNA i mogli odtworzyć pliki idealnie przy średnio 14 odczytach sekwencyjnych na łańcuch — lepsza gęstość niż wcześniejsze schematy sześcioliterowe przy jednoczesnym zmniejszeniu liczby wymaganych odczytów. Przy pełnym, 15‑literowym alfabecie diamentu DNA uzyskali 3,125 bita na pozycję dla głównych danych i nadal odzyskali wszystko bez błędów przy pokryciu 33‑krotnym. Symulacje i eksperymenty wykazały również, że ich metoda oparta na entropii działa niemal równie dobrze jak najbardziej dokładne, choć wolniejsze, podejście dekodujące, i wyraźnie lepiej niż starsze techniki, szczególnie przy niższych głębokościach sekwencjonowania.
Co to oznacza dla przyszłej pamięci
Dla czytelnika nieznającego tematu kluczowy wniosek jest taki, że autorzy znaleźli sposób, by nauczyć DNA „nowych sztuczek” bez wynajdywania nowej chemii: poprzez sprytne mieszanie istniejących czterech zasad i inteligentniejsze dekodowanie, mogą zapisać więcej bitów informacji na molekułę przy kontrolowanych kosztach. Ich diamentowy alfabet, w połączeniu z solidnym indeksowaniem i korekcją błędów, pokazuje, że pamięć o dużej pojemności oparta na DNA jest możliwa przy stosunkowo umiarkowanym nakładzie sekwencjonowania. W miarę jak synteza i sekwencjonowanie DNA będą tanieć, takie rozwiązania mogą pomóc przekształcić DNA z laboratorystycznej ciekawostki w realistyczne medium do archiwizowania cyfrowych wspomnień świata.
Cytowanie: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Słowa kluczowe: przechowywanie danych w DNA, litery złożone, gęstość informacji, korekcja błędów, archiwizacja cyfrowa