Clear Sky Science · pl
Postępy i wyzwania w przechowywaniu danych w niekanonicznych kwasach nukleinowych
Dlaczego przechowywanie danych w cząsteczkach ma znaczenie
Każde zdjęcie, wiadomość i film musi gdzieś być przechowywane, a dziś tym „gdzieś” są przede wszystkim ogromne magazyny dysków twardych zużywających dużo energii i zużywające się w ciągu dekad. Ten artykuł bada zupełnie inne podejście: wykorzystanie specjalnie zaprojektowanych cząsteczek genetycznych jako mini taśm pamięci. Poprzez modyfikację znanych składników DNA i RNA naukowcy dążą do stworzenia nośnika informacji o większej gęstości, trwałości i bezpieczeństwie niż jakikolwiek układ krzemowy czy dysk magnetyczny.
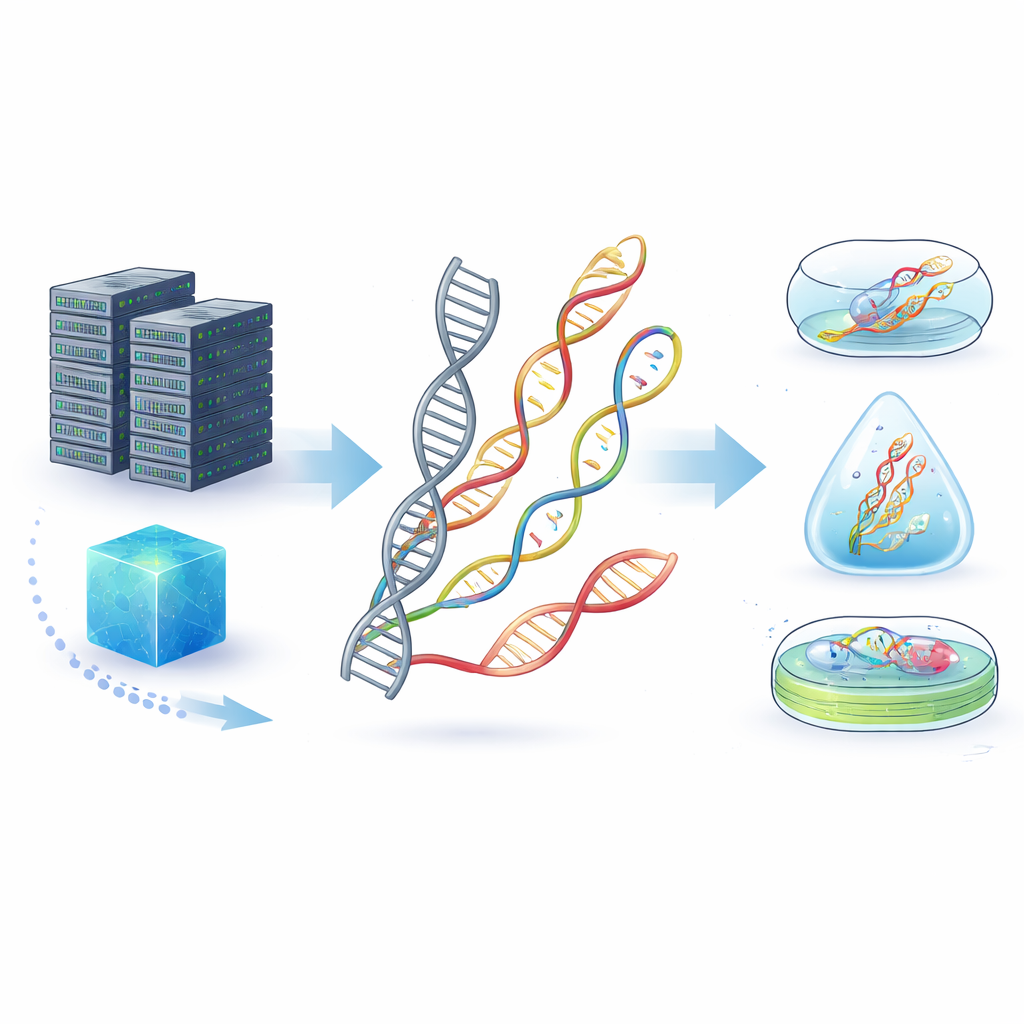
Od kruchego DNA do odporniejszych molekuł
Naturalne DNA już jest imponującym nośnikiem danych, mieszcząc ogromne ilości informacji w mikroskopijnej objętości i zachowując się przez dziesiątki tysięcy lat w skamieniałościach. Jednak w codziennych warunkach — przy wysokiej temperaturze, wilgoci, obecności obcych chemikaliów lub enzymów rozkładających DNA — może szybko ulegać degradacji. Autorzy przedstawiają „niekanoniczne kwasy nukleinowe” (ncNA): cząsteczki podobne do DNA i RNA, których zasady, cukry lub łańcuchy szkieletowe zostały chemicznie zmienione, a czasem odwrócone, by nadać im nowe właściwości. Takie zmiany mogą sprawić, że molekuły będą trudniejsze do zniszczenia przez enzymy, bardziej odporne na działanie kwasów lub zasad i lepiej przetrwają surowe warunki środowiskowe niż zwykłe DNA.
Dodawanie nowych liter do genetycznego alfabetu
Jednym z najpotężniejszych pomysłów w przeglądzie jest rozszerzenie alfabetu genetycznego poza cztery znane litery A, T, G i C. Chemicy stworzyli dodatkowe pary zasad, które nadal mieszczą się w podwójnej helisie, lecz nie występują w naturze. Przy 8, 12 lub większej liczbie liter każdy punkt na nici może kodować więcej bitów informacji, co znacznie zwiększa pojemność przechowywania w porównaniu ze standardowym DNA. Niektóre z tych nowych zasad zaprojektowano tak, by łączyły się przez oddziaływania hydrofobowe zamiast zwykłych wiązań wodorowych, co pokazuje, że zasady parowania natury można modyfikować, zachowując jednocześnie możliwość odczytu informacji.
Przebudowa molekularnego szkieletu
Oprócz zmiany „liter” badacze przeprojektowują też cukier i łańcuch szkieletowy, które podtrzymują nić genetyczną. Zastąpienie zwykłego cukru alternatywami, takimi jak treoza czy heksitol, lub zamiana naładowanych wiązań fosforanowych na obojętne bądź zawierające siarkę, może radykalnie zmienić zachowanie nici. Wiele takich ncNA wykazuje imponującą stabilność w wysokich temperaturach, w środowiskach kwaśnych lub zasadowych oraz w obecności enzymów, w których naturalne DNA szybko by się rozpadło. Niektóre lustrzane wersje, takie jak L-DNA, są niewidoczne dla normalnych enzymów i układów odpornościowych, co czyni je obiecującymi do ultra-bezpiecznego przechowywania danych i ukrytych wiadomości, choć obecnie ich produkcja i odczyt są trudne i kosztowne.
Jak dane są zapisywane, przechowywane i odczytywane
Przekształcenie plików cyfrowych w formę molekularną przebiega w czterech etapach: kodowanie, zapisywanie, konserwacja i odczyt. Bity są najpierw tłumaczone na sekwencje lub struktury, które następnie są syntezowane jako nici ncNA przy użyciu metod chemicznych lub specjalnie zmodyfikowanych enzymów. Takie nici można przechowywać poza komórkami — zamknięte w szkle, krzemionce lub polimerach — albo wewnątrz komórek i nawet w zmodyfikowanych roślinach, gdzie naturalne mechanizmy naprawcze mogą pomagać w ich utrzymaniu. Odczyt danych może wykorzystać znane maszyny do sekwencjonowania DNA, zaawansowane urządzenia nanoporowe, które „odczuwają” każdą jednostkę przechodzącą przez maleńki otwór, lub mikroskopy rozpoznające kształty w wytworzonych nanostrukturach. Ponieważ wiele ncNA nie może być jeszcze bezpośrednio sekwencjonowane, często są one konwertowane z powrotem na zwykłe DNA przed odczytem — krok, który obecne badania starają się usprawnić i udoskonalić.
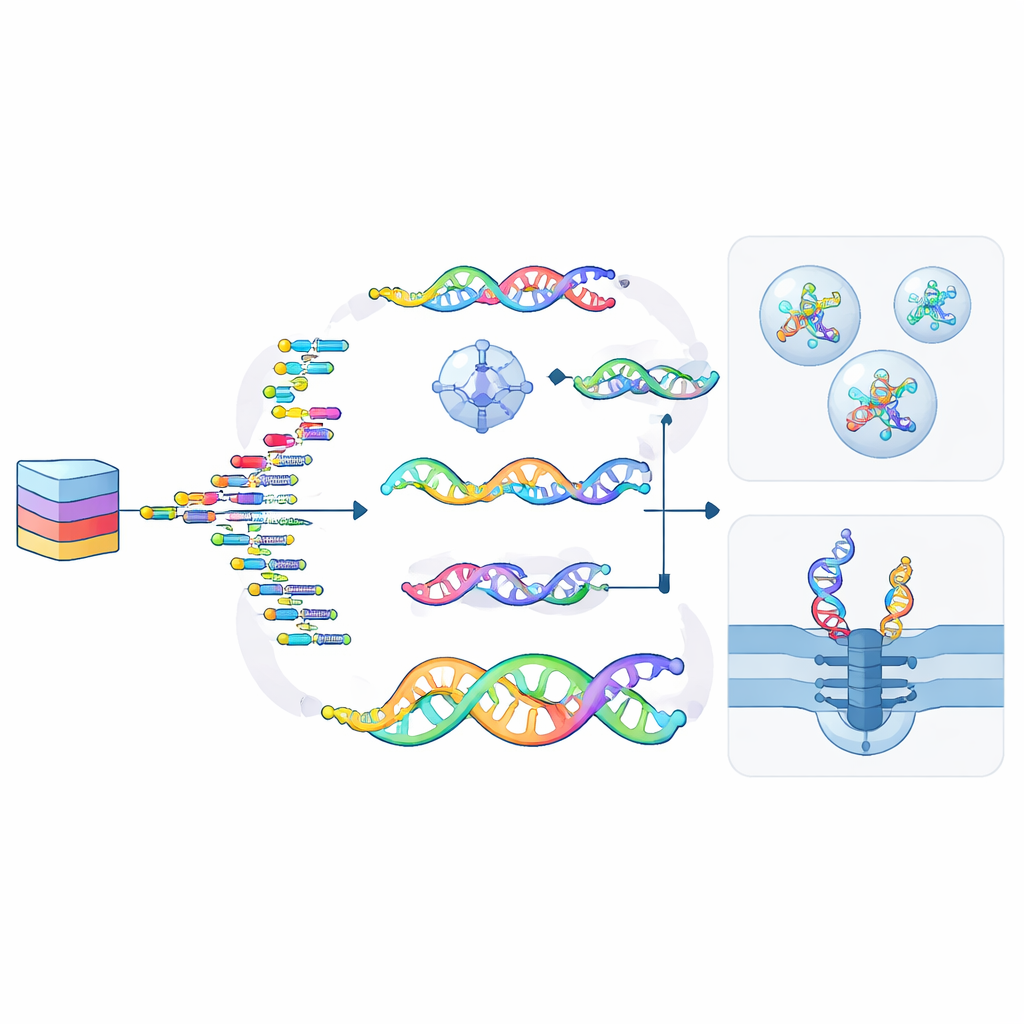
Nowe możliwości: obliczenia, bezpieczeństwo i równoległe zapisywanie
Artykuł podkreśla, że ncNA pełnią więcej funkcji niż tylko przechowywanie danych — mogą je także przetwarzać. Istnieją już układy logiczne oparte na DNA i sieci neuronopodobne, a dodanie chemicznie odrębnych alfabetów ułatwia wykonywanie wielu operacji równolegle bez niepożądanego zakłócania się sygnałów. Pewne modyfikacje działają jak niewidzialny atrament, pozwalając ukryć informacje w niciach lub strukturach, które ujawniają się tylko przy użyciu specjalnych enzymów lub określonych warunków. Inne, takie jak odwracalne adduktory chemiczne czy wzory grup metylowych, zachowują się jak ruchome czcionki na prasie drukarskiej: mogą równolegle nanosić dane na istniejące nici, usuwać je i przepisywać bez konieczności odbudowy całej molekuły od podstaw.
Przyszłe wyzwania i co oznacza sukces
Pomimo obiecujących perspektyw autorzy podkreślają, że przechowywanie danych w niekanonicznych kwasach nukleinowych jest jeszcze na wczesnym etapie. Produkcja długich, pozbawionych błędów nici jest kosztowna i technicznie wymagająca, a wiele atrakcyjnych rozwiązań chemicznych nie jest jeszcze zgodnych z szybkim i niedrogim odczytem. Pojawiają się też istotne pytania dotyczące bezpieczeństwa i etyki związane z wprowadzaniem wysoce stabilnych, częściowo nienaturalnych molekuł do systemów żywych. Mimo to przegląd przedstawia mapę drogową, w której szybsza synteza, inteligentniejsze kapsułkowanie i czytniki nanoporowe wspomagane sztuczną inteligencją mogą uczynić przechowywanie oparte na ncNA praktycznym w nadchodzących dekadach. Jeśli tak się stanie, pewnego dnia możemy wykonać kopię zapasową naszej cyfrowej cywilizacji nie na wirujących dyskach, lecz w maleńkich, odpornych nićach zaprojektowanych molekuł.
Cytowanie: Wang, Y., Pei, Y., Tang, L. et al. Advances and challenges in non-canonical nucleic acids data storage. Nat Commun 17, 2354 (2026). https://doi.org/10.1038/s41467-026-68708-6
Słowa kluczowe: przechowywanie danych w DNA, niekanoniczne kwasy nukleinowe, pamięć molekularna, nienaturalne pary zasad, sekwencjonowanie nanoporowe