Clear Sky Science · pl
Akceleratory sieci neuronowych nanofotoniki zaprojektowane metodą odwrotną do ultrakompaktowego przetwarzania optycznego
Dlaczego zmniejszanie komputerów wykonanych ze światła ma znaczenie
Współczesna sztuczna inteligencja działa na rozległym sprzęcie elektronicznym, który zużywa ogromne ilości energii i generuje ciepło. Niniejsze badanie bada zupełnie inną drogę: wykorzystanie maleńkich wzorców światła na chipie zamiast strumieni elektronów do wykonywania części obliczeń sieci neuronowych. Autorzy pokazują, że przez „rzeźbienie” światła na skali nanometrycznej można zbudować ultrakompaktowe akceleratory optyczne, które rozpoznają pisane ręcznie cyfry i obrazy medyczne, zajmując znacznie mniej miejsca i — w zasadzie — zużywając znacznie mniej energii niż współczesna elektronika.
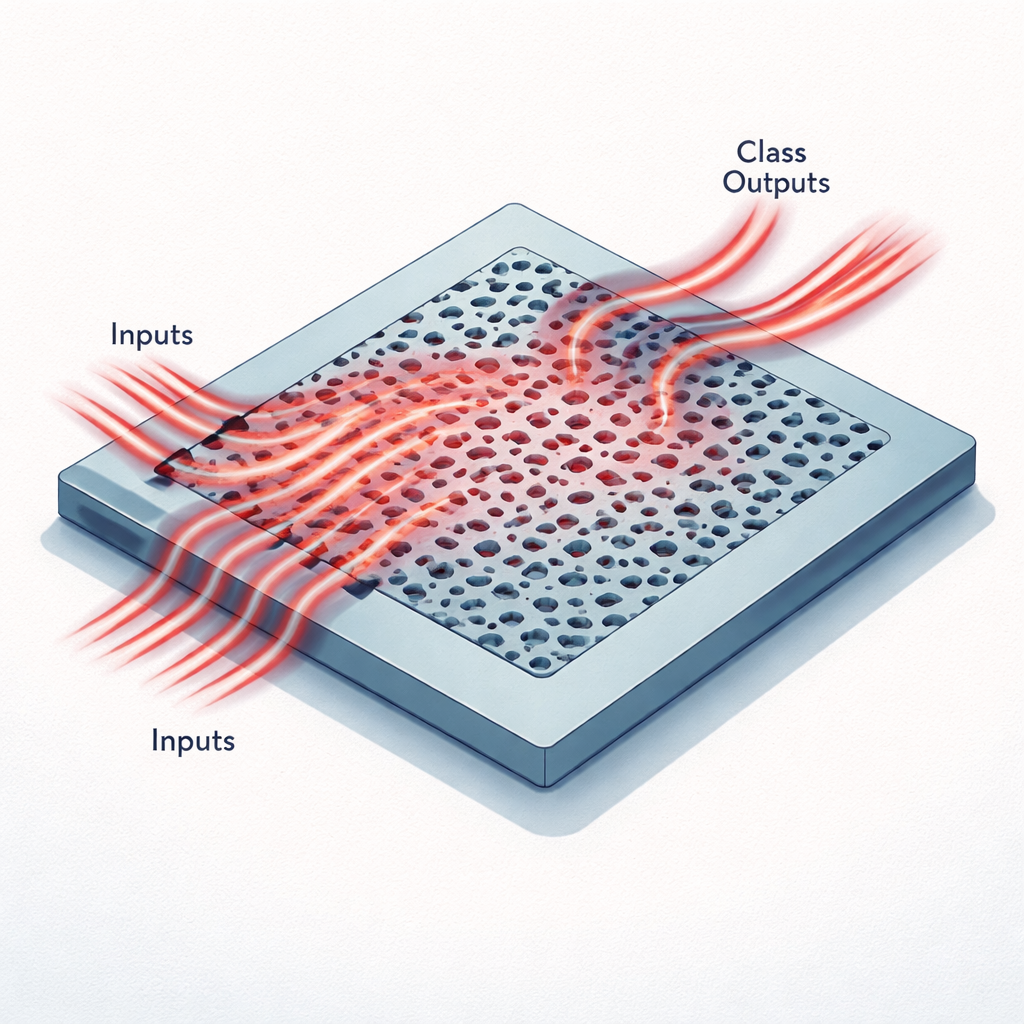
Maleńkie układy, które myślą światłem
Zamiast przewodów i tranzystorów te akceleratory wykorzystują płaski kawałek krzemu wzorzecowany otworami i kanałami mniejszymi niż długość fali podczerwieni. Dane z obrazu są najpierw skompresowane do niewielkiego zestawu liczb, które następnie są kodowane jako jasność światła wprowadzana do kilku wąskich falowodów przy jednej długości fali telekomunikacyjnej. Gdy to światło przepływa do obszaru z wzorem, jest rozpraszane, interferuje samo ze sobą i kierowane w stronę kilkunastu wyjściowych falowodów. Każde wyjście odpowiada możliwej klasie, na przykład jednej z dziesięciu cyfr w zbiorze MNIST lub jednej z sześciu kategorii w zestawie obrazów medycznych MedNIST. Rozkład mocy optycznej na wyjściach odgrywa tę samą rolę, co ostatnia warstwa cyfrowej sieci neuronowej.
Pozwolenie algorytmom rysować optyczny plan
Ręczne zaprojektowanie takiej struktury byłoby niemal niemożliwe, ponieważ każdy maleńki „woksel” materiału może zmienić sposób, w jaki porusza się światło. Badacze wykorzystują zamiast tego podejście projektowania odwrotnego: zaczynają od losowego wzoru krzemu i szkła, symulują, jak światło rozchodzi się przez strukturę w trzech wymiarach, a następnie modyfikują wzór, aby zredukować funkcję straty mierzącą błędy klasyfikacji. Wykorzystują przy tym liniowość równań Maxwella — praw opisujących zachowanie światła — aby uczynić to szkolenie wydajnym. Zamiast symulować każde obrazowe wejście oddzielnie, symulują każdy kanał wejściowy raz, a potem rekonstruują pola dla wszystkich obrazów jako kombinacje liniowe tych wstępnie obliczonych pól. Matematyczna technika zwana metodą sprzężoną (adjoint method) dostarcza dokładnych gradientów, które wskazują algorytmowi, jak przesunąć każdy woksel, by poprawić działanie.

Kompaktowe klasyfikatory obrazów wielkości ziarnka piasku
Wykorzystując tę strategię, zespół zaprojektował dwa akceleratory nanofotoniczne na standardowej platformie krzem‑na‑izolatorze (silicon‑on‑insulator). Jeden, o wymiarach zaledwie 20 na 20 mikrometrów, klasyfikuje ręcznie pisane cyfry z zestawu MNIST; drugi, 30 na 20 mikrometrów, klasyfikuje obrazy medyczne z MedNIST. W symulacjach te maleńkie urządzenia osiągnęły dokładności odpowiednio 97,8% i 99,1%. Wersje odtworzone fizycznie i testowane z prawdziwymi laserami i detektorami osiągnęły 89% dokładności dla MNIST i 90% dla MedNIST — imponujące wyniki, biorąc pod uwagę maleńki rozmiar chipów. Struktury optyczne upakowują w przybliżeniu od 160 000 do 240 000 parametryzowalnych parametrów w obszarach mniejszych niż ziarnko kurzu, co odpowiada około 400 milionom parametrów na milimetr kwadratowy.
Zaprojektowane pod kątem prędkości, efektywności i skalowalności
Ponieważ urządzenia są pasywne — nie mają ruchomych części ani przeprogramowywalnych elementów podczas inferencji — nie wymagają ciągłego strojenia po wytworzeniu. „Wagi” sieci neuronowej są zatopione w geometrii nanostruktury, więc obliczenia dzieją się z prędkością światła z zasadą przetwarzania w pamięci: światło wchodzi z zakodowanymi danymi i wychodzi już wymieszane w wyniki klas. Metoda treningowa została również zaprojektowana z myślą o skalowaniu. Każdy krok optymalizacji wymaga jedynie stałej liczby symulacji pełnej fizyki określonej przez liczbę wejść i wyjść, a nie przez rozmiar zbioru danych, i te symulacje można rozdzielić na wiele jednostek przetwarzania graficznego. Autorzy dodatkowo opisują, jak wiele takich optycznych rdzeni można by układać warstwami z fotodetektorami pomiędzy nimi, podobnie jak warstwy w głębokiej sieci neuronowej, oraz jak multipleksacja w długości fali lub w czasie może zwiększyć przepustowość.
Co to oznacza dla przyszłego sprzętu AI
Mówiąc prosto, praca ta pokazuje, że można „wyhodować” niestandardowe kawałki szkła i krzemu, które zachowują się jak wyspecjalizowane warstwy sieci neuronowych, wszystkie w obszarze wystarczająco małym, by umieścić ich setki lub tysiące na jednym chipie. Chociaż pełne komputery optyczne wciąż są na horyzoncie, te zaprojektowane metodą odwrotną akceleratory nanofotoniczne mogłyby odciążyć niektóre z najbardziej energochłonnych części obciążeń AI od procesorów elektronicznych. W połączeniu z szybkimi modulatorami, detektorami i przemyślanym projektem systemowym wskazują one drogę do kompaktowego, niskomocowego sprzętu, w którym to światło, a nie wyłącznie elektryczność, wykonuje dużą część ciężkiej pracy w uczeniu maszynowym.
Cytowanie: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
Słowa kluczowe: fotoniczne sieci neuronowe, nanofotonika, obliczenia optyczne, akceleratory sprzętowe, projektowanie odwrotne