Clear Sky Science · pl
Podwójny kontekstowy basecaller do bezpośredniego sekwencjonowania RNA metodą nanopore
Dlaczego dekodowanie liter RNA ma znaczenie
Każda komórka w twoim ciele nieustannie odczytuje i przepisuje komunikaty zapisane w RNA, będącym roboczą kopią naszych genów. Nowe urządzenia „nanopore” potrafią odczytywać poszczególne cząsteczki RNA bezpośrednio, co obiecuje ujawnić, jak geny są włączane, jak RNA jest składane (splicing) i jak chemiczne markery na RNA wpływają na zdrowie i choroby. Jest jednak haczyk: urządzenia te mierzą tak naprawdę niewielkie prądy elektryczne, które trzeba następnie przetłumaczyć — „basecallować” — na dobrze znane litery A, C, G i U. Jeśli to tłumaczenie jest błędne, wnioski biologiczne mogą zostać poważnie zniekształcone. W artykule przedstawiono Coral, nowy system sztucznej inteligencji, który znacząco poprawia tę translację.
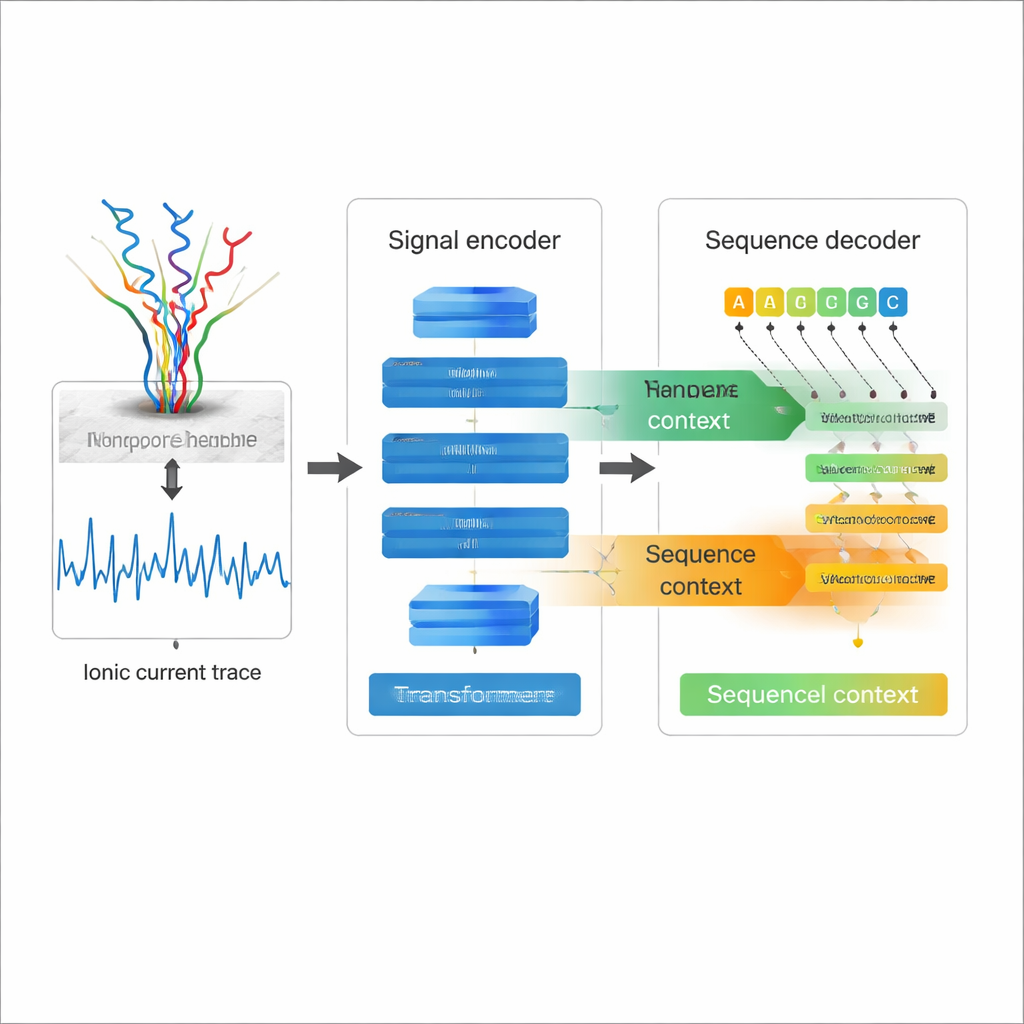
Odczytywanie elektryczności zamiast liter
Bezpośrednie sekwencjonowanie RNA metodą nanopore polega na przeciąganiu pojedynczego łańcucha RNA przez molekularną dziurkę — nanopore — przy jednoczesnym pomiarze, jak zmienia się prąd elektryczny, gdy przez nią przechodzi każda zasada. Te falujące zapisy prądu zawierają informację o sekwencji RNA i jej chemicznych modyfikacjach. Tradycyjne sekwencjonowanie RNA najpierw konwertuje RNA na DNA i amplifikuje materiał, co może wprowadzać zniekształcenia i usuwać wiele naturalnych oznaczeń chemicznych. Bezpośrednie sekwencjonowanie RNA omija te problemy, ale kosztem relatywnie wyższego wskaźnika błędów przy przekształcaniu śladów prądowych w sekwencje, szczególnie dla trudnych elementów, takich jak powtórzenia nukleotydów czy złożone struktury RNA. Lepszy basecalling jest kluczowy, jeśli naukowcy chcą ufać szczegółom tych długich odczytów RNA.
Mądrzejszy tłumacz wykorzystujący dwa rodzaje kontekstu
Większość istniejących basecallerów nanopore traktuje sygnał elektryczny jako główne źródło informacji i dekoduje każdą pozycję niemal niezależnie, co ogranicza wykorzystanie samej struktury sekwencji RNA. Coral przyjmuje inne podejście. Wykorzystuje architekturę enkoder–dekoder opartą na Transformerze, podobną w duchu do nowoczesnych modeli językowych. Najpierw sieć enkodera zbudowana z warstw splotowych i samo‑uwagi przetwarza surowy sygnał prądowy do zwartego opisu zmian sygnału w czasie. Następnie dekoder przewiduje każdą kolejną bazę RNA krok po kroku, jednocześnie patrząc wstecz na już wygenerowane bazy i równolegle na zakodowany sygnał. Dwa rodzaje uwagi — w obrębie rosnącej sekwencji RNA i pomiędzy sekwencją a sygnałem — pozwalają Coral uwzględniać zarówno kontekst elektryczny, jak i sekwencyjny przy decyzji, która litera pojawi się następna.
Bardziej precyzyjne sekwencje i mniej utraconych cząsteczek
Autorzy porównali Coral z kilkoma wiodącymi basecallerami, w tym komercyjnymi narzędziami Oxford Nanopore, na RNA pochodzącym od ludzi i innych organizmów oraz przy użyciu kilku chemii nanopore. W sześciu gatunkach i na starszych zestawach do sekwencjonowania RNA Coral osiągnął typową medianę dokładności odczytów około 97%, wyraźnie przewyższając konkurencję. Przy najnowszym zestawie RNA jego dokładność przekroczyła 99%. Coral generował mniej niedopasowań, insercji i delecji oraz dawał dłuższe, lepiej wyrównane odczyty z mniejszą liczbą sekwencji, których nie można było w ogóle zmapować. Był szczególnie skuteczny w radzeniu sobie z krótkimi ciągami powtarzających się zasad — bardzo powszechnymi w rzeczywistych danych — które często powodują błędy w innych narzędziach. Poprzez bardziej niezawodne uchwycenie dłuższych fragmentów poprawnej sekwencji, Coral również wyróżniał się w przewidywaniu krótkich wzorców sekwencyjnych (k‑merów) i pozostawał odporny nawet wtedy, gdy wcześniejsze kroki dekodowania zawierały drobne błędy.
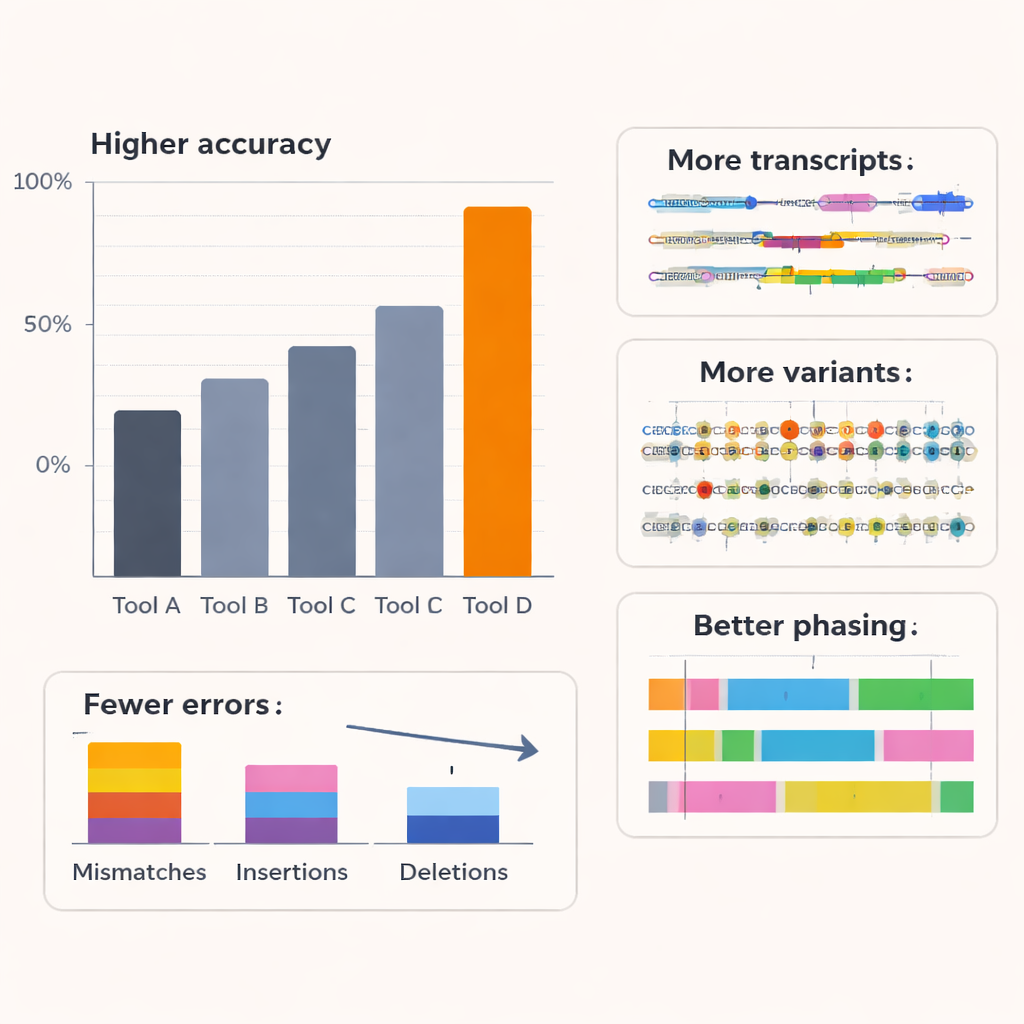
Więcej ukrytych szczegółów transkryptomu
Ulepszony basecalling ma wartość tylko wtedy, gdy przekłada się na lepszą biologię. Aby to sprawdzić, zespół przeanalizował, jak wyjście Corala wpływa na dalsze analizy w liniach komórkowych człowieka. Używając wyspecjalizowanego narzędzia do rekonstrukcji pełnych izoform RNA — różnych wersji splicingowych każdego genu — stwierdzili, że odczyty Corala ujawniały więcej znanych struktur transkryptów i wiele dodatkowych izoform o niskiej obfitości, które inne basecallery pomijały. Wiele transkryptów specyficznych dla Corala miało wsparcie w niezależnych danych z krótkich odczytów, co sugeruje, że są realne, a nie artefaktami. Coral wykrył też więcej sztucznych transkryptów referencyjnych o znanych stężeniach w eksperymencie ze spike‑in i oszacował ich obfitość dokładniej. Poza odkrywaniem transkryptów, Coral poprawił wykrywanie zdarzeń fuzji genów w linii komórkowej raka piersi oraz zwiększył liczbę i wiarygodność genów wykazujących ekspresję alleliczną, gdzie jedna kopia genu od jednego z rodziców jest bardziej aktywna niż druga.
Czystsze warianty genetyczne i linie rodzinne
Ponieważ długie odczyty RNA mogą obejmować odległe warianty genetyczne, są potężnym narzędziem do ustalania, które warianty występują razem na tej samej kopii chromosomu — procesu zwanego fazowaniem haplotypowym. Używając dobrze scharakteryzowanej próbki ludzkiej z mapą wariantów o standardzie złotym, autorzy pokazali, że wyższa jakość odczytów Corala prowadziła do dokładniejszego wykrywania zmian pojedynczych nukleotydów i znacznie mniejszej liczby błędów fazowania: błędy przełączeń i ogólne współczynniki niedopasowań w blokach fazowanych spadły nawet o około trzy czwarte w porównaniu z innymi metodami, przy jednoczesnym znacznym zwiększeniu liczby wariantów możliwych do sfasowania. Badania symulacyjne zmieniające bazową dokładność odczytów potwierdziły, że gdy basecalling osiąga około 95% dokładności, wydajność w odkrywaniu transkryptów, ekspresji allelicznej i fazowaniu gwałtownie rośnie, a potem się stabilizuje. Coral znajduje się w tej strefie dużych korzyści, co sugeruje, że wychwytuje większość biologicznie istotnej informacji zawartej w zaszumionych sygnałach nanopore.
Co to oznacza dla przyszłych badań nad RNA
Dla osób spoza specjalizacji kluczowy komunikat jest taki, że Coral działa jak znacznie bardziej niezawodny tłumacz między elektrycznym językiem sekwencerów nanopore a genetycznym językiem RNA. Lepsze wykorzystanie kontekstu zarówno w sygnale, jak i w rosnącej sekwencji sprawia, że produkowane odczyty są czystsze, ujawniają więcej wariantów transkryptów, wykrywają rzadkie geny fuzyjne i pewniej śledzą, które warianty pochodzą od którego rodzica. Oprogramowanie jest otwarte (open‑source), więc badacze mogą je dostosować do nowych organizmów, chemii lub nawet do badania chemicznych znaków na samym RNA. W miarę jak technologia nanopore będzie się dalej rozwijać, narzędzia takie jak Coral pomogą przekształcać surowe ślady prądowe w godne zaufania, szczegółowe mapy świata RNA wewnątrz komórek.
Cytowanie: Xie, S., Ding, L., Yu, Y. et al. A dual context-aware basecaller for nanopore direct RNA sequencing. Nat Commun 17, 1851 (2026). https://doi.org/10.1038/s41467-026-68566-2
Słowa kluczowe: sekwencjonowanie RNA nanopore, basecalling, model Transformer, izofomy transkryptów, faza haplotypowa