Clear Sky Science · pl
Trzy otwarte pytania dotyczące przenośności wyników poligenicznych
Dlaczego przewidywanie stanu zdrowia na podstawie DNA jest trudniejsze, niż się wydaje
Lekarze i naukowcy coraz częściej chcą używać opartych na DNA „skali poligenicznych”, aby przewidywać ryzyko wystąpienia u danej osoby powszechnych schorzeń, takich jak cukrzyca, choroby serca czy astma. Jednak te skale często dobrze działają tylko u osób podobnych do pierwotnych uczestników badań, którzy zwykle mają pochodzenie europejskie. Artykuł analizuje, dlaczego te przewidywania nie „przenoszą się” niezawodnie na osoby o odmiennym podłożu genetycznym lub warunkach życiowych oraz co to oznacza dla sprawiedliwego stosowania ocen genetycznego ryzyka w medycynie.
Co obiecują skale poligeniczne — i gdzie zawodzą
Skale poligeniczne łączą drobne efekty wielu wariantów genetycznych w całym genomie w pojedynczą liczbę mającą przewidywać cechę, taką jak wzrost czy ciśnienie krwi. Tworzy się je na podstawie ogromnych badań asocjacyjnych obejmujących cały genom (GWAS), które wiążą markery DNA z cechami u setek tysięcy ochotników. Gdy jednak te skale stosuje się do nowych grup ludzi, ich dokładność bardzo się różni. Zwykle trafność maleje im bardziej nowa grupa różni się genetycznie lub społecznie od oryginalnych uczestników GWAS. To nazywa się problemem przenośności: wynik, który działa w jednym kontekście, może w innym wprowadzać w błąd, potencjalnie pogłębiając nierówności zdrowotne, jeśli będzie używany bezkrytycznie.
Wyjście poza pochodzenie: odległość na mapie genetycznej
Aby zbadać ten problem, autorzy wykorzystali dane z UK Biobank, które zawierają informacje genetyczne i zdrowotne od ponad 400 000 osób. Zbudowali skale poligeniczne dla 15 wysoko dziedzicznych cech, takich jak wzrost, masa ciała, liczba komórek krwi i poziomy cholesterolu, na podstawie dużej grupy głównie białych uczestników z Wielkiej Brytanii. Następnie przetestowali, jak dobrze te skale przewidują cechy u 69 500 innych uczestników o bardzo zróżnicowanym tle genetycznym. Zamiast przypisywać osoby do szerokich kategorii pochodzenia, zespół umieścił każdą osobę na ciągłej skali „odległości genetycznej”: jak daleko profil DNA danej osoby leżał od średniego uczestnika GWAS, gdy rzutowano go na mapę genetyczną opartą na składowych głównych.
Moc predykcji słabnie — ale nie w prosty ani sprawiedliwy sposób
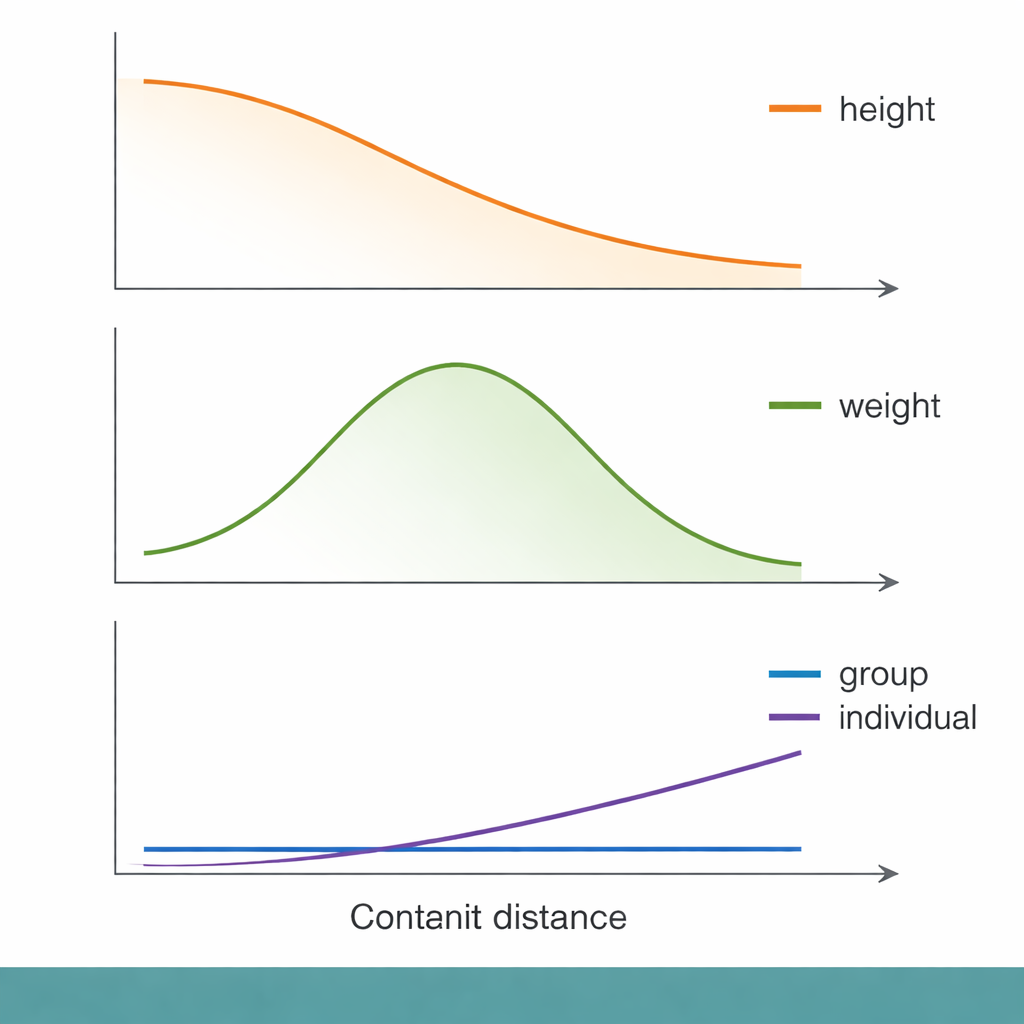
Wzdłuż tej skali odległości genetycznej pojawiły się pewne znane wzorce. Dla wzrostu, na przykład, dokładność przewidywań na poziomie grupy stopniowo malała wraz ze wzrostem genetycznej odległości od grupy GWAS. Jednak gdy badacze przyjrzeli się poziomowi indywidualnemu, odległość genetyczna tłumaczyła tylko drobny ułamek tego, jak dobrze przewidywano cechy. Miary społecznoekonomiczne, takie jak indeks deprywacji Townsenda (wskaźnik materialnego ubóstwa na poziomie sąsiedztwa), w przybliżeniu równie dobrze — a czasem nieco lepiej — tłumaczyły, u kogo przewidywania były słabe. Innymi słowy, osoby o niższym statusie społeczno-ekonomicznym miały tendencję do otrzymywania mniej dokładnych genetycznych prognoz, nawet w tej samej grupie odległości genetycznej, co podkreśla, że kontekst społeczny może mieć równie duże znaczenie co DNA dla użyteczności skali.
Różne cechy, różne historie, różne odpowiedzi
Nie wszystkie cechy zachowywały się jednakowo. Dla masy ciała i zawartości tłuszczu przewidywalność faktycznie osiągała szczyt przy pośrednich odległościach genetycznych, zanim zaczęła spadać, łamiąc prosty schemat „im dalej, tym gorzej”. Cechy związane z układem odpornościowym, takie jak liczba białych krwinek i limfocytów, wykazywały szczególnie zagadkowe zachowanie. Dla niektórych z tych cech dokładność przewidywań na poziomie grupy spadała niemal do zera nawet dla osób, które nie były genetycznie bardzo odległe od próbki GWAS. Autorzy sugerują, że cechy odpornościowe mogą być kształtowane przez szybko zmieniające się presje ewolucyjne — na przykład wcześniejsze zakażenia — które zmieniają, które warianty DNA mają znaczenie w różnych populacjach. W takich przypadkach sama architektura genetyczna mogła przesunąć się na tyle, że skala oparta na jednej grupie staje się praktycznie bezużyteczna w innej.
To, jak oceniamy wydajność, może odwrócić wnioski
Obraz staje się jeszcze bardziej złożony, gdy zmienimy sposób mierzenia „dobrej przewidywalności”. Wiele wcześniejszych prac opierało się na jednym wskaźniku zwanym R², który pokazuje, jaką część zmienności cechy tłumaczy skala w grupie. Autorzy pokazują, że inne metryki mogą opowiedzieć inną historię, zwłaszcza w przypadku chorób. Dla astmy zarówno precyzja (ile przewidywanych przypadków to faktyczne przypadki), jak i czułość (ile prawdziwych przypadków zostaje wykrytych) malały wraz z odległością genetyczną w podobny sposób. Ale dla cukrzycy typu 2 precyzja pozostawała względnie stała, podczas gdy czułość faktycznie rosła wraz z odległością — co oznacza, że skala wykrywała większy odsetek prawdziwych przypadków w bardziej odległych grupach, mimo że została zbudowana w grupie bliższej. W zależności od tego, czy klinice bardziej zależy na wykryciu wszystkich osób o wysokim ryzyku, czy na unikaniu fałszywych alarmów, można dojść do przeciwnych wniosków o przenośności skali.
Co to oznacza dla używania ocen DNA w praktyce
Podsumowując, badanie wskazuje, że nie można oceniać użyteczności skal poligenicznych, patrząc jedynie na szerokie etykiety pochodzenia czy na pojedynczą liczbę dokładności. Jakość indywidualnych przewidywań zależy od mieszanki czynników: subtelnych wzorców podobieństwa genetycznego, ewolucyjnej historii każdej cechy, środowisk i warunków społecznych, w których żyją ludzie, oraz od konkretnego sposobu skonstruowania skali i wybranego wskaźnika jej wydajności. Aby skale poligeniczne mogły być stosowane sprawiedliwie i skutecznie w medycynie, badacze będą potrzebować lepszych metod uchwycenia drobnej struktury genetycznej, modelowania wpływów społecznych i środowiskowych oraz dopasowania metryk ewaluacji do rzeczywistych decyzji klinicznych. Do tego czasu oceny genetycznego ryzyka powinny być stosowane ostrożnie, z uwzględnieniem osób — i kontekstów — dla których działają słabo, jak i tych, w których są przydatne.
Cytowanie: Wang, J.Y., Lin, N., Zietz, M. et al. Three open questions in polygenic score portability. Nat Commun 17, 942 (2026). https://doi.org/10.1038/s41467-026-68565-3
Słowa kluczowe: skale poligeniczne, predykcja genetyczna, nierówności zdrowotne, pochodzenie genetyczne, medycyna precyzyjna