Clear Sky Science · pl
Fizyczne sieci neuronowe z treningiem uwzględniającym ostrość
Dlaczego ma to znaczenie dla przyszłości sprzętu AI
W miarę jak sztuczna inteligencja staje się potężniejsza, jej ograniczenia coraz częściej wynikają nie z pomysłowych algorytmów, lecz z układów scalonych, które je uruchamiają. Jedną obiecującą drogą wyjścia jest budowa sieci neuronowych bezpośrednio w sprzęcie fizycznym, wykorzystując światło, elektronikę analogową lub inne systemy falowe. Ten artykuł przedstawia nowy sposób trenowania takich „fizycznych sieci neuronowych”, tak aby zachowywały dokładność nawet wtedy, gdy rzeczywistość bywa nieporządna — gdy urządzenia są nieco niedokładnie wykonane, występują dryfy temperaturowe lub elementy tracą ustawienie.
Od cyfrowych mózgów do maszyn fizycznych
Nowoczesne AI zwykle działa na sprzęcie cyfrowym, takim jak procesory graficzne, gdzie trening opiera się na algorytmie wstecznej propagacji, który dopasowuje miliony numerycznych wag. Fizyczne sieci neuronowe próbują przenieść tę obliczeniową pracę do rzeczywistych materiałów i urządzeń — takich jak układy fotoniczne, sieci interferometrów czy elementy optyczne dyfrakcyjne — których zachowanie naturalnie odwzorowuje matematykę sieci neuronowych. Ponieważ te systemy przetwarzają informacje tam, gdzie są przechowywane, mogą być znacznie szybsze i bardziej energooszczędne niż konwencjonalne układy. Jednak ich trenowanie jest trudne: albo trenuje się model cyfrowy i liczy na to, że będzie odpowiadał sprzętowi, albo trenuje się bezpośrednio na urządzeniu. Obie drogi napotykają problemy, gdy rzeczywiste urządzenia odbiegają od idealnych modeli lub ulegają dryfom w czasie.
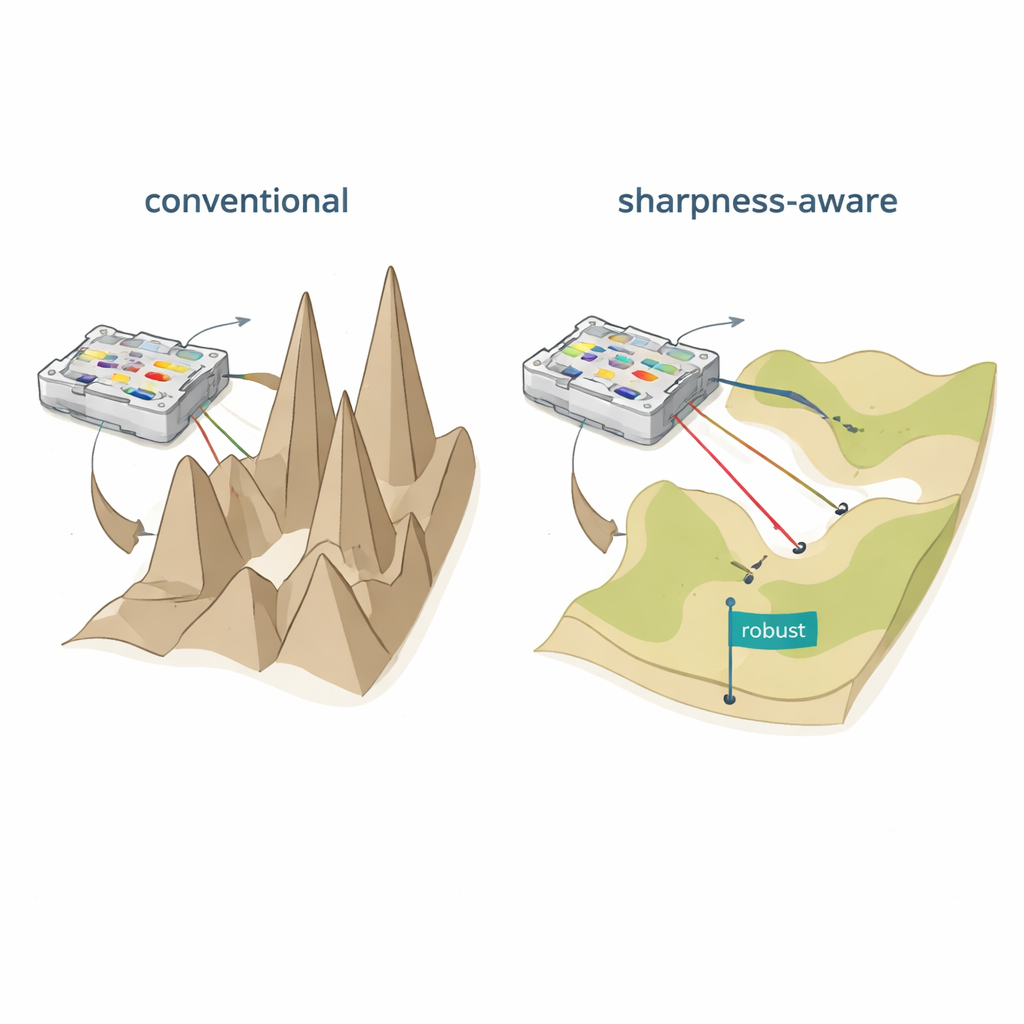
Dwa wadliwe sposoby nauczania sieci fizycznych
Pierwsze podejście, zwane treningiem in silico, uczy wszystkie parametry na modelu komputerowym, a następnie kopiuje je do sprzętu. Działa to dobrze tylko wtedy, gdy model matematyczny niemal idealnie odpowiada wytworzonemu urządzeniu, co rzadko ma miejsce po uwzględnieniu odchyleń produkcyjnych, szumów elektrycznych i efektów termicznych. Drugie podejście, trening in situ, integruje fizyczne urządzenie bezpośrednio z procesem uczenia, wielokrotnie mierząc wyjścia podczas dostosowywania parametrów. Chociaż omija to błędy modelowania, stwarza inne problemy: informacje o gradientach są trudne i kosztowne do uzyskania, trening staje się specyficzny dla danego urządzenia, a wygenerowane parametry zwykle nie dają się przenieść na inny, nominalnie identyczny układ. W obu przypadkach drobne zmiany po wdrożeniu — na przykład niewielka zmiana temperatury lub nieznaczne przesunięcie — mogą drastycznie obniżyć dokładność i wymusić kosztowne ponowne trenowanie.
Wygładzanie krajobrazu uczenia
Autorzy proponują trening uwzględniający ostrość (SAT), inspirowany pomysłem z uczenia maszynowego zwanym minimalizacją uwzględniającą ostrość. Zamiast tylko znaleźć ustawienia dające mały błąd na danych treningowych, SAT poszukuje także obszarów, w których błąd zmienia się powoli, gdy drobne modyfikacje dotykają fizycznych parametrów. Geometrycznie tradycyjny trening często znajduje głęboką, ale wąską dolinę w „krajobrazie straty”, gdzie nawet maleńkie przesunięcia prądów, faz czy pozycji powodują załamanie wydajności. SAT celowo szuka szerokich, płaskich dolin, w których wydajność pozostaje wysoka mimo takich zakłóceń. Matematycznie dodaje do celu treningowego termin karzący ostre, silnie zakrzywione obszary w przestrzeni parametrów i przybliża tę karę efektywnie, używając dwóch starannie dobranych kroków gradientowych zamiast kosztownych obliczeń pochodnych drugiego rzędu.
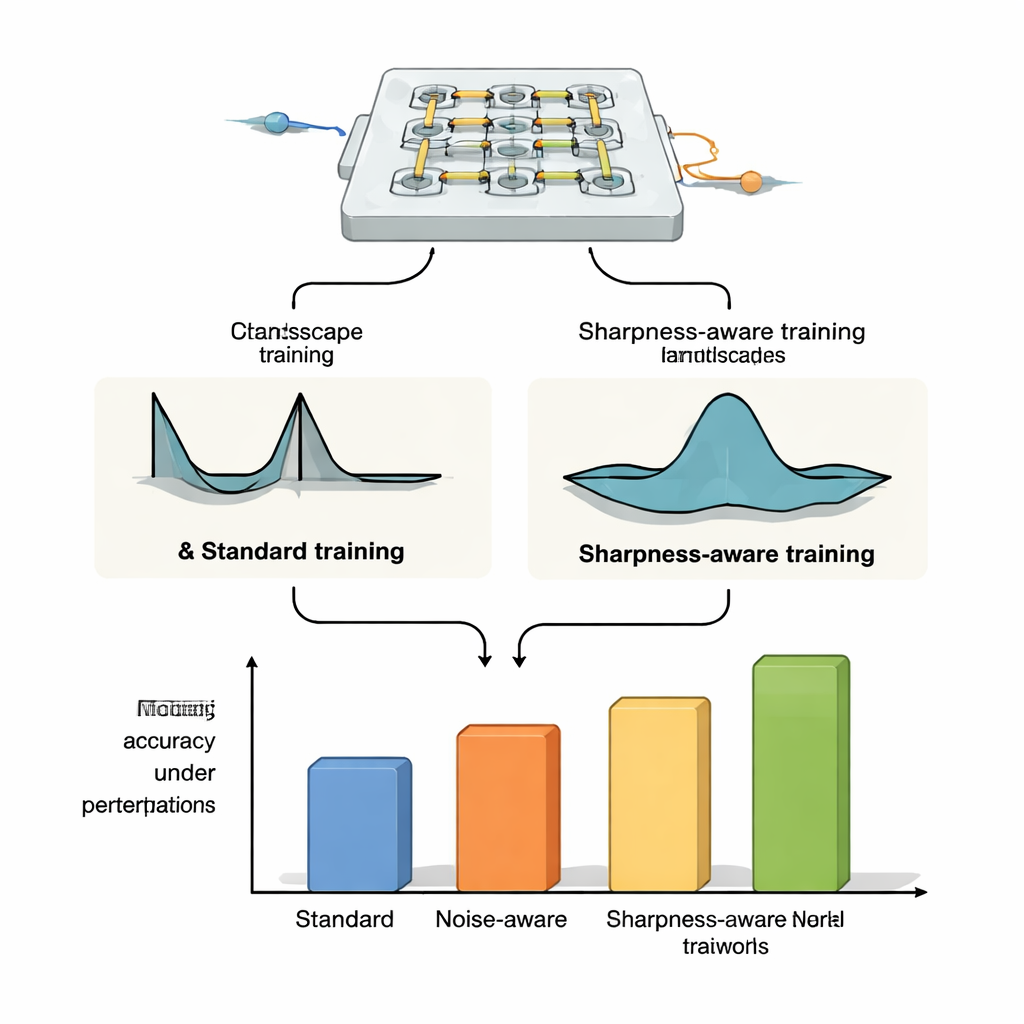
Dowód odporności na różnych platformach optycznych
Aby pokazać, że SAT nie jest związany z jednym konkretnym urządzeniem, autorzy zastosowali go do trzech odmiennych platform optycznych sieci neuronowych. W bankach wag z mikropierścieni rezonatorowych — maleńkich pętli krzemu, które kierują światło o różnych długościach fali — wykazali, że systemy trenowane metodą SAT utrzymują wysoką dokładność klasyfikacji nawet przy dryfie temperatury o kilka stopni Celsjusza, podczas gdy standardowy trening i metody wstrzykiwania szumu zawodzą drastycznie. Rozszerzyli to na bardziej wymagające zadania, takie jak klasyfikacja obrazów na zbiorze CIFAR-10, kompresja i rekonstrukcja obrazów oraz generowanie obrazów, gdzie SAT utrzymuje stabilną wydajność, podczas gdy konwencjonalne metody zawodzą przy umiarkowanych zmianach termicznych. W symulacjach siatek interferometru Mach–Zehndera modele trenowane SAT są znacznie bardziej odporne na realistyczne błędy produkcyjne i, co kluczowe, parametry wytrenowane na jednym urządzeniu można przenosić na inne układy z różnymi niedoskonałościami bez utraty dokładności. Wreszcie, w układzie optycznym z dyfrakcją w przestrzeni wolnej wykorzystującym wyświetlacz OLED, soczewki i modulatory światła przestrzennego, SAT poprawia tolerancję na fizyczne przesunięcia, takie jak rotacja, przesunięcia pikseli i skalowanie, mimo że dokładny związek między tymi przesunięciami a parametrami sieci nie jest wprost modelowany.
Praktyczna droga do niezawodnej fizycznej AI
Mówiąc prosto, ta praca pokazuje, jak nauczyć sprzętowe sieci neuronowe w sposób, który „wybacza” nieuniknione niedoskonałości rzeczywistych urządzeń. Kierując proces uczenia ku płaskim, stabilnym rejonom krajobrazu błędu, trening uwzględniający ostrość sprawia, że fizyczne sieci neuronowe są zarówno dokładniejsze, jak i bardziej odporne na wariacje w produkcji, zmiany temperatury i nieprawidłowe ustawienia mechaniczne. Ponieważ można go stosować z modelami fizycznymi lub bez nich i działa na kilku typach sprzętu optycznego, SAT oferuje praktyczny przepis na skalowanie szybkich, energooszczędnych systemów fizycznej AI od laboratoryjnych demonstracji do rzeczywistych zastosowań.
Cytowanie: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Słowa kluczowe: fizyczne sieci neuronowe, obliczenia fotoniczne, odporny trening, optymalizacja uwzględniająca ostrość, sprzęt neuromorficzny