Clear Sky Science · pl
Kompleksowe mapowanie dynamiki modyfikacji RNA i ich wzajemnych zależności za pomocą deep learningu i bezpośredniego sekwencjonowania RNA w technologii nanopore
Ukryte znaki interpunkcyjne RNA
Cząsteczki RNA w naszych komórkach to nie proste łańcuchy A, C, G i U. Są ozdobione dziesiątkami drobnych chemicznych znaków, które działają jak interpunkcja — pomagają kontrolować, które geny są aktywne, jak powstają białka oraz jak komórki reagują na stres i choroby. Do tej pory naukowcy zwykle badali te znaki pojedynczo, co utrudniało zrozumienie, jak współdziałają w skali całego genomu. W artykule przedstawiono ORCA — system oparty na deep learningu, który czyta rodzimy RNA bezpośrednio i buduje globalną, wielowarstwową mapę tych chemicznych znaków oraz ich interakcji.
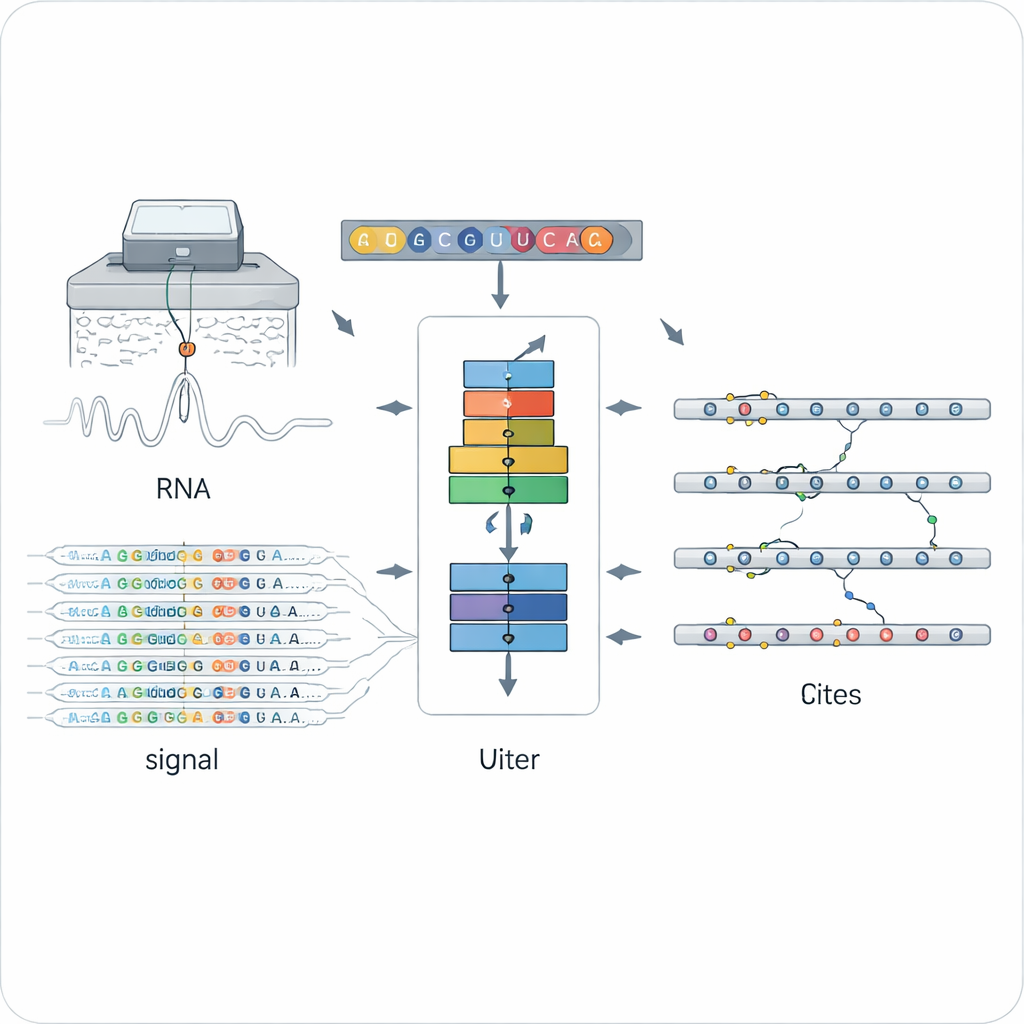
Nowy sposób odczytywania chemicznych znaków na RNA
Tradycyjne metody wykrywania modyfikacji RNA zwykle opierają się na specjalnych przeciwciałach lub chemii dostosowanej do jednego typu znaku, jak popularne N6‑metyladenozyna (m6A). To sprawia, że są one potężne, lecz wąskie: każda metoda widzi tylko jeden rodzaj modyfikacji, często w określonym układzie eksperymentalnym. Bezpośrednie sekwencjonowanie RNA w technologii nanopore otworzyło inną drogę — przeciąganie pojedynczych cząsteczek RNA przez maleńki otwór i pomiar zmian w prądzie elektrycznym, które zależą od dokładnej struktury chemicznej każdej zasady. Zmienione i niezmienione nukleotydy zniekształcają sygnał i proces basecallingu w subtelnie różny sposób, ale interpretacja tych hałaśliwych, wielowymiarowych danych obejmujących wiele typów modyfikacji stanowiła poważne wyzwanie.
Nauka sieci neuronowej rozpoznawania dowolnego znaku
ORCA (Omni‑RNA modification Characterization and Annotation) rozwiązuje to wyzwanie w dwóch etapach. Najpierw skupia się na małym oknie wokół każdej pozycji w RNA i agreguje zarówno surowy sygnał elektryczny, jak i wzór błędów sekwencjonowania w wielu odczytach. Ponieważ tylko część kopii RNA nosi daną modyfikację, prawdziwie zmodyfikowane miejsca wykazują bardziej skośne rozkłady sygnału i częstsze błędy basecallingu w tej pozycji. ORCA wykorzystuje głęboką rekurencyjną sieć neuronową trenowaną strategią „adwersarialną”, dzięki czemu uczy się ogólnych wzorców odróżniających miejsca zmodyfikowane od niezmodyfikowanych, nie przywiązując się do pojedynczego znanego typu chemicznego. Pozwala to ORCA przypisywać każdemu miejscu wynik modyfikacji oraz szacowany odsetek zmodyfikowanych cząsteczek.
Rozpoznawanie tożsamości poszczególnych znaków
W drugim etapie ORCA uczy się etykietować, jaki rodzaj chemiczny jest obecny. Autorzy dostarczają modelowi zestaw miejsc o wysokim zaufaniu z publicznych baz danych, gdzie konwencjonalne eksperymenty zidentyfikowały już m6A, 5‑metylocytozynę (m5C), pseudourydynę (Ψ), inozynę, 2′‑O‑metylację i kilka rzadszych modyfikacji. ORCA kompresuje wzorce sygnału, kontekst sekwencji i krótkie „motywy” sekwencyjne wokół każdego miejsca do przestrzeni o niższym wymiarze, a następnie dopracowuje się, aby przewidzieć typ modyfikacji i dokładną zasadę, na której ona występuje. Ważne jest, że nieoznaczone miejsca są także używane jako przykłady „tła”, co pomaga modelowi unikać przypisywania nieznanych modyfikacji do niewłaściwej kategorii. Po treningu ORCA może przenosić te wyuczone etykiety na dziesiątki tysięcy wcześniej nieanotowanych miejsc w transkryptomie.
Wykrywanie wielu modyfikacji jednocześnie
Stosując ORCA do komórek ludzkich i mysich, autorzy pokazują, że system nie tylko dorównuje lub przewyższa dokładność wiodących narzędzi dla specyficznych znaków takich jak m6A, m5C i Ψ, lecz także potrafi wykrywać modyfikacje, na których nie był jawnie trenowany. Na przykład, nawet gdy dane m6A były wyłączone podczas treningu, ORCA odnalazła większość niezależnie zmierzonych miejsc m6A i prawidłowo odróżniła je od podobnych motywów sekwencyjnych bez modyfikacji. Podobnie zadziałało to dla grup 2′‑O‑metylowych, miejsc edycji inozyny oraz różnorodnych zmian chemicznych na rRNA, w tym wielu rzadkich modyfikacji wykrytych metodami spektrometrii mas. Ogółem ORCA znacznie rozszerza znany katalog miejsc modyfikacji RNA, wielokrotnie zwiększając liczbę anotowanych m5C, Ψ, m7G i innych mało licznych znaków w porównaniu z istniejącymi bazami danych.
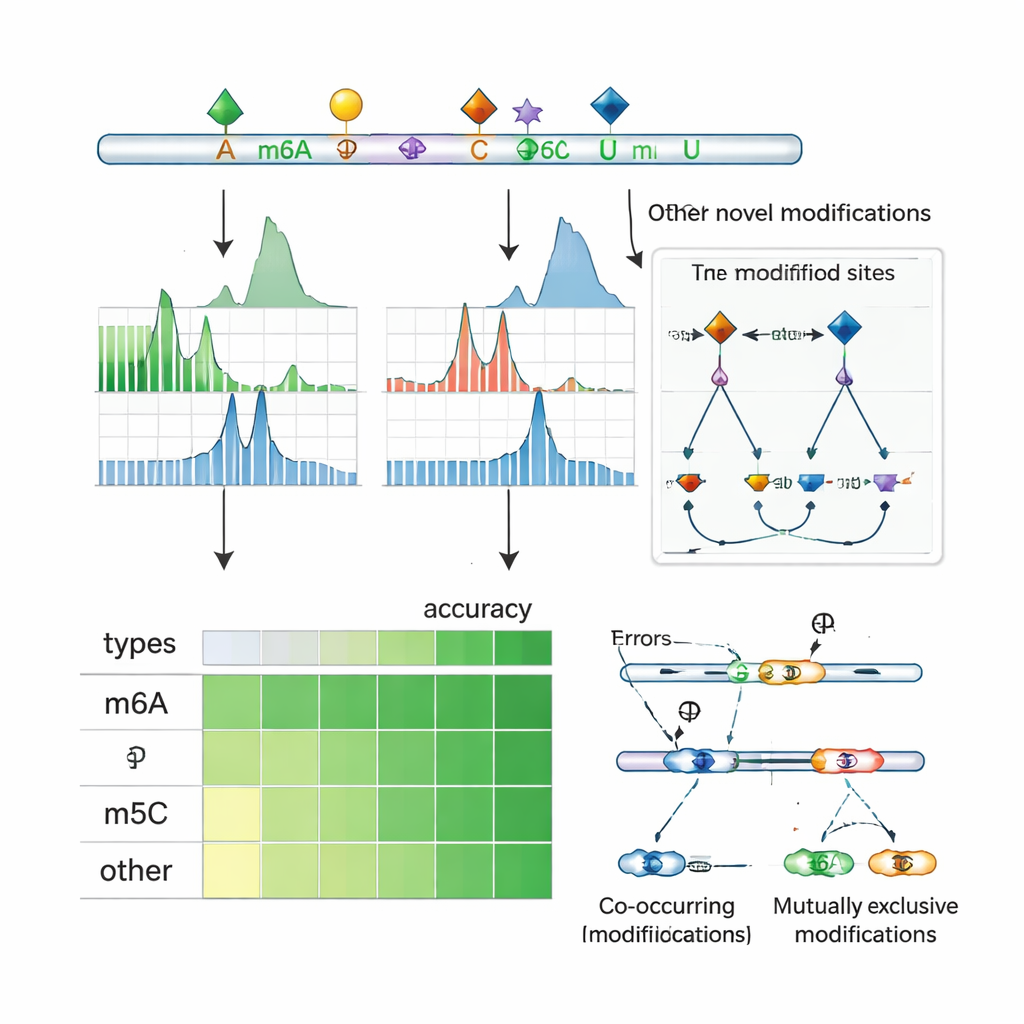
Odkrywanie współzależności i kontroli splicingu
Ponieważ sekwencjonowanie nanopore odczytuje całe cząsteczki RNA, ORCA może sprawdzać, które modyfikacje występują razem na tym samym transkrypcie, a które zwykle się wykluczają. Autorzy grupują pobliskie modyfikacje wzdłuż RNA i wykorzystują model probabilistyczny do wnioskowania, czy pary miejsc często są współzmodyfikowane, czy też nawzajem się wykluczają na pojedynczych cząsteczkach. Stwierdzają częste współwystępowanie m6A z m5C i innymi znakami, a także wiele regionów, gdzie jedno miejsce jest modyfikowane tylko wtedy, gdy sąsiednie nie jest. W liniach komórkowych ludzkich wzorce te często pojawiają się blisko eksonów, które są włączane lub pomijane w alternatywnym splicingu, i pokrywają miejsca wiązania regulatorów splicingu oraz „czytelników” rozpoznających zmodyfikowane RNA. W określonych genach ORCA ujawnia, że pewne warianty splicingowe są wzbogacone o jeden wzór modyfikacji, podczas gdy warianty alternatywne niosą inny, łącząc lokalne chemiczne ozdobienie RNA z tym, jak wiadomości są cięte i składane.
Dlaczego to ma znaczenie dla biologii i medycyny
Łącząc bezpośrednie sekwencjonowanie RNA z elastycznym deep learningiem, ORCA przekształca złożony sygnał elektryczny w bogatą, wielowarstwową mapę chemicznych znaków w całym transkryptomie. Dla nie‑specjalistów kluczowym rezultatem jest to, że naukowcy mogą teraz zobaczyć nie tylko, gdzie występują pojedyncze modyfikacje RNA, lecz także ile różnych znaków ozdabia tę samą cząsteczkę i jak te kombinacje wiążą się z regulacją genów, zwłaszcza splicingiem RNA. Ramy te umożliwiają badanie „epigenetyki” RNA w wielu typach komórek i warunkach bez konieczności projektowania nowego eksperymentu dla każdej modyfikacji, torując drogę do odkryć dotyczących tego, jak te drobne chemiczne poprawki wpływają na rozwój, funkcje mózgu oraz choroby, takie jak rak i zaburzenia neurologiczne.
Cytowanie: Dong, H., Gao, Y., Cai, Z. et al. Comprehensive mapping of RNA modification dynamics and crosstalk via deep learning and nanopore direct RNA-sequencing. Nat Commun 17, 1722 (2026). https://doi.org/10.1038/s41467-026-68419-y
Słowa kluczowe: modyfikacje RNA, sekwencjonowanie nanopore, deep learning, epitranskryptom, alternatywne składanie (splicing)