Clear Sky Science · pl
Zastosowanie uczenia maszynowego i genomiki w doskonaleniu zapomnianych upraw
Ukryte uprawy o dużym potencjale
W Afryce, Azji i Ameryce Łacińskiej miliony ludzi polegają na tak zwanych „zapomnianych uprawach”, takich jak sorgo, tef, maniok czy orzech ziemny. Rośliny te rzadko pojawiają się na pierwszych stronach gazet, a mimo to często lepiej znoszą upał, suszę, szkodniki i złe gleby niż globalne podstawy żywienia, takie jak pszenica czy ryż. Artykuł przeglądowy analizuje, jak dwa potężne narzędzia — genomika i uczenie maszynowe — mogą uwolnić potencjał tych pomijanych roślin, wzmacniając lokalne bezpieczeństwo żywnościowe i dostarczając cennych genów, które mogłyby wzmocnić główne uprawy na całym świecie.
Dlaczego zapomniane uprawy mają znaczenie
Zapomniane uprawy bywają nazywane „zaniedbanymi” lub „niedostatecznie wykorzystywanymi”, ponieważ otrzymały znacznie mniej uwagi naukowej i komercyjnej niż duże uprawy eksportowe. Mimo to stanowią podstawę żywienia wielu społeczności i często uprawiane są w trudnych, marginalnych warunkach, gdzie inne rośliny zawodzą. W przeciwieństwie do pszenicy czy ryżu większość zapomnianych upraw nie skorzystała z postępów zielonej rewolucji ani nowoczesnych narzędzi, takich jak hodowla z użyciem markerów czy edycja genomu. Projekty genomowe, np. African Orphan Crops Consortium, zaczynają sekwencjonować i katalogować ich DNA, lecz przekształcenie surowych danych genetycznych w praktyczne ulepszenia wciąż pozostaje poważnym wyzwaniem.
Uczenie komputerów czytania roślin
Uczenie maszynowe — metody komputerowe uczące się wzorców z dużych zestawów danych — już zmienia hodowlę w głównych uprawach. Łącząc sekwencje genomowe, dane pogodowe i glebowe, odczyty z czujników oraz obrazy z dronów lub smartfonów, algorytmy mogą przewidywać złożone cechy, takie jak plon, odporność na choroby czy jakość ziarna. Różne typy modeli, od drzew decyzyjnych po głębokie sieci neuronowe, sprawdzają się w różnych zastosowaniach. Czasem tradycyjne narzędzia statystyczne dorównują lub przewyższają głębokie uczenie, ale ogólnie mieszanie wielu źródeł danych i modeli daje hodowcom dokładniejsze i bardziej spójne prognozy niż pojedyncze podejście.
Wykorzystanie ograniczonych danych
W przypadku zapomnianych upraw kluczową przeszkodą nie jest moc obliczeniowa, lecz niedostatek danych. Istnieje tylko kilka publicznych zbiorów genomowych i obrazów, a niewiele z nich jest na tyle obszerne, by zasilić konwencjonalne procesy uczenia maszynowego. Mimo to pierwsze demonstracje są obiecujące. W sorgo na przykład modele głębokiego uczenia wykorzystały proste fotografie ziarna do przewidywania zawartości białka i przeciwutleniaczy z wysoką dokładnością, oferując tańszą alternatywę dla badań laboratoryjnych. Innym razem pomiary w bliskiej podczerwieni i głębokie uczenie posłużyły do oszacowania cech odżywczych w ziołach rodzaju Perilla. Artykuł argumentuje, że budowa dzielonych baz danych genomów, obrazów i profili chemicznych dla zapomnianych upraw szybko pomnoży wpływ takich narzędzi.
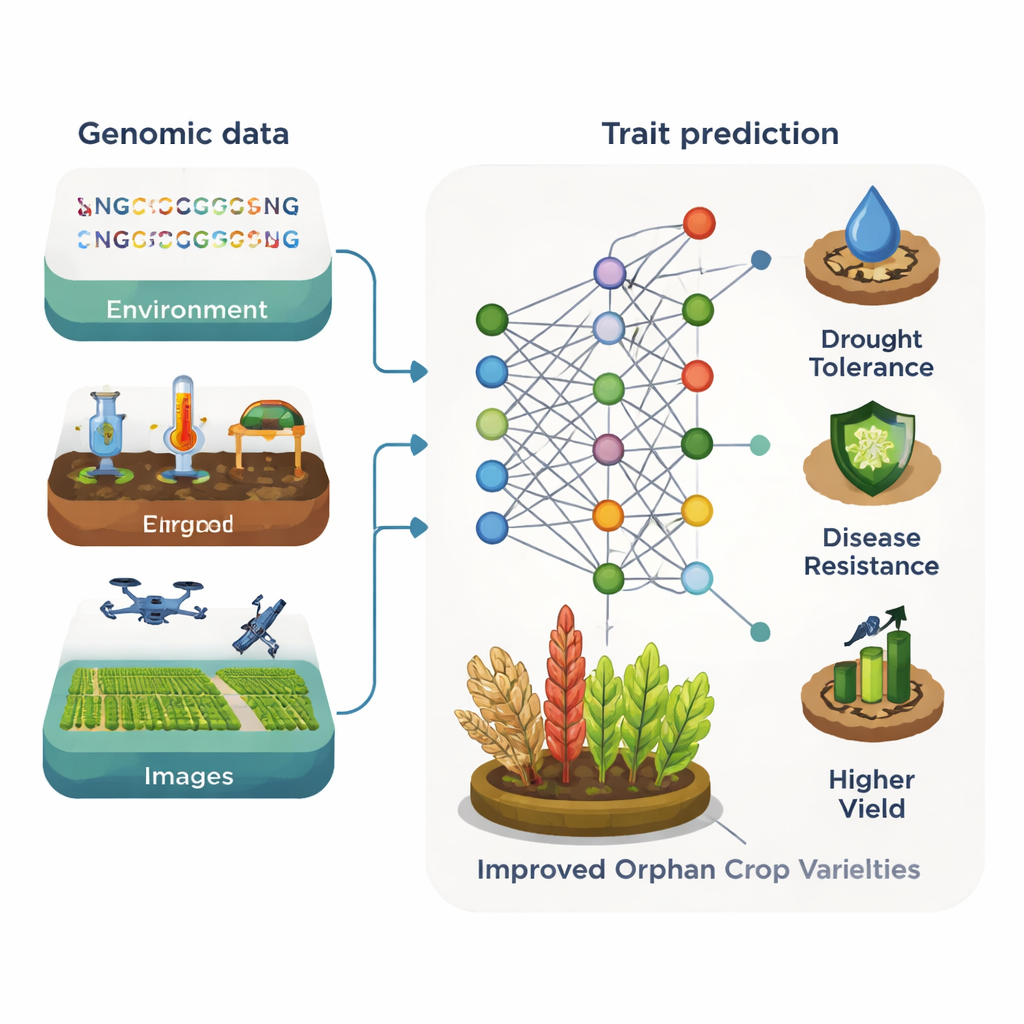
Pożyczanie wiedzy od większych upraw
Centralną ideą artykułu jest „transfer wiedzy” między gatunkami. Wiele zapomnianych upraw jest bliskimi krewnymi głównych upraw, dzieląc duże fragmenty DNA i podobne geny. Modele uczenia maszynowego mogą wykorzystać tę spokrewnioną strukturę. Narzędzia najpierw trenowane na dobrze zbadanych roślinach, takich jak Arabidopsis czy kukurydza, mogą pomóc wskazać geny odpowiedzialne za cechy takie jak wysokość rośliny, jakość nasion czy tolerancja na stres w mniej znanych krewnych. Duże modele językowe pierwotnie rozwinięte dla genomów ludzkich lub roślinnych mogą także traktować DNA jako rodzaj tekstu, ucząc się wzorców oznaczających regiony regulacyjne czy ważne geny. Po przeszkoleniu na bogatych zbiorach danych modele te można dostroić do ograniczonych danych zapomnianych upraw, by przewidywać funkcję genów, wskazywać cele dla edycji genomu i prowadzić bardziej efektywną hodowlę.
Z algorytmów na pola i do rolników
Autorzy podkreślają, że sama technologia nie odmieni zapomnianych upraw. Postęp zależy od inwestycji w lokalnych naukowców, partnerstw z drobnymi gospodarstwami oraz polityk zapewniających, że społeczności skorzystają z nowych odmian. Podejścia obywatelskiej nauki, w których rolnicy testują odmiany bezpośrednio na własnej ziemi, mogą generować cenne dane dla uczenia maszynowego, jednocześnie dostosowując badania do lokalnych potrzeb i preferencji. Ponieważ finansowanie jest ograniczone, artykuł rekomenduje zrównoważoną strategię: łączenie niskokosztowej, tradycyjnej hodowli i agronomii z celowanymi projektami genomiki i uczenia maszynowego oraz dzielenie się narzędziami i danymi między krajami oraz między uprawami zapomnianymi i głównymi.
Co to oznacza dla naszej przyszłości żywnościowej
Mówiąc wprost, artykuł konkluduje, że mądrzejsze komputery i lepsze informacje genetyczne mogą pomóc przekształcić dzisiejsze „zapomniane” uprawy w przyszłe, odporne na zmiany klimatu podstawy żywienia. Ucząc się od dużych upraw i stosując te lekcje w odniesieniu do mniejszych — a potem przekazując odkrycia w drugą stronę — uczenie maszynowe i genomika mogą przyspieszyć poszukiwanie wytrzymałych, odżywczych odmian. Jeśli rozwiązania te będą wspierane przez przemyślaną politykę i autentyczną współpracę ze społecznościami rolniczymi, podejście to może poprawić diety, wzmocnić odporność na zmiany klimatu i poszerzyć globalne narzędzia rolnicze poza wąski zestaw podstawowych upraw.
Cytowanie: MacNish, T.R., Danilevicz, M.F., Bayer, P.E. et al. Application of machine learning and genomics for orphan crop improvement. Nat Commun 16, 982 (2025). https://doi.org/10.1038/s41467-025-56330-x
Słowa kluczowe: zapomniane uprawy, uczenie maszynowe, genomika, hodowla roślin, bezpieczeństwo żywnościowe