Clear Sky Science · pl
Estymacja i edycja oświetlenia z pojedynczego widoku dla dynamicznego wyświetlacza pola świetlnego
Dlaczego twój wirtualny świat powinien pasować do twojego salonu
Każdy, kto nosił zestaw do rzeczywistości wirtualnej lub mieszanej, to widział: cyfrowy obiekt, który wygląda dziwnie nie na miejscu, z oświetleniem i cieniami nieadekwatnymi do pomieszczenia. Ten artykuł zajmuje się tym problemem. Autorzy przedstawiają metodę, dzięki której zestawy słuchawkowe „rozumieją” oświetlenie w rzeczywistym otoczeniu na podstawie tylko jednego obrazu z kamery, a następnie wykorzystują tę wiedzę, by wirtualne obiekty wyglądały, jakby faktycznie należały do twojego świata — bez specjalnych sond świetlnych, skomplikowanych pomiarów czy żmudnej kalibracji.
Uproszczenie pracy z oświetleniem w przestrzeni
W fizyce i grafice komputerowej wygląd sceny zależy od pełnego „pola świetlnego”: wszystkich promieni świetlnych przepływających przez przestrzeń we wszystkich kierunkach. Dokładne odtworzenie tego pola zwykle wymaga dużo danych — wielu obrazów i starannych pomiarów. Nowoczesne techniki 3D, takie jak neuronalne pola radiancji, potrafią przechowywać sceny w sieciach neuronowych, ale zwykle „zapieczętowują” w sobie oświetlenie obecne podczas przechwytywania. Oznacza to, że scena wirtualna wygląda poprawnie tylko w tych pierwotnych warunkach i psuje się, gdy zmieni się oświetlenie w rzeczywistości. Autorzy dążą do przełamania tego ograniczenia, znajdując zwartą reprezentację rzeczywistego oświetlenia z minimalnych danych, a następnie używając jej do elastycznego ponownego oświetlania sceny 3D zapisanej neuronowo.
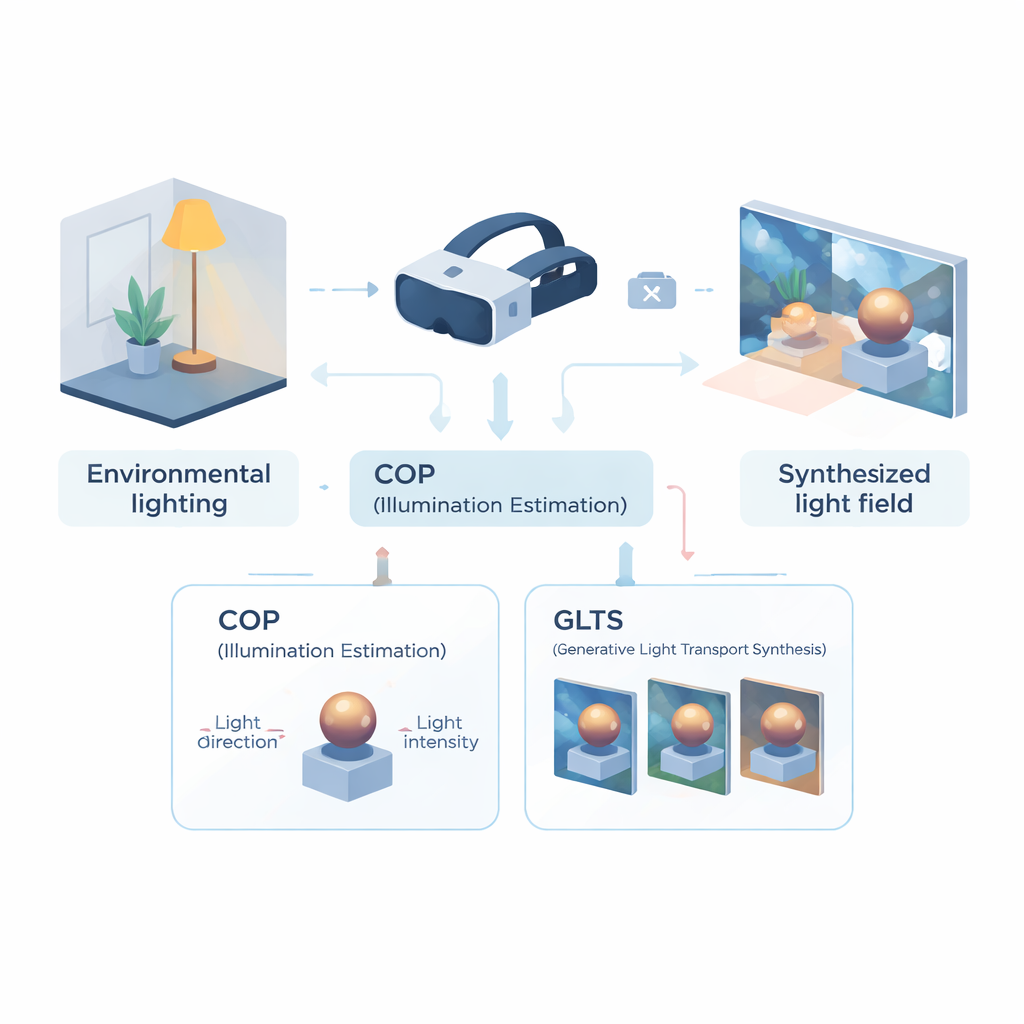
Nauka słuchawki czytania pomieszczenia
Pierwszym elementem frameworku jest moduł percepcji optyczno-obliczeniowej (COP), zaprojektowany do odczytywania oświetlenia z pojedynczego widoku kamery. Zamiast rekonstruować całe pole świetlne, COP koncentruje się na dominującym źródle światła: jego kierunku i sile. Wieloskalowa sieć neuronowa skanuje obraz wejściowy w poszukiwaniu fizycznie znamiennych wskazówek — jasnych odbić, gradientów cieniowania i cieni — podczas gdy specjalny etap interpolacji koryguje nieliniowy sposób, w jaki kamery kompresują jasność. To daje liczbowe estymaty intensywności i kierunku światła, które lepiej odzwierciedlają rzeczywistą energię w scenie. Drugi etap, nazwany interpretatorem semantycznym, dopracowuje te wartości i generuje krótkie, tekstopodobne opisy oświetlenia (na przykład: światło pada z góry i z prawej). Połączenie liczb i słów sprawia, że estymacja jest bardziej stabilna i łatwiejsza do wykorzystania w kolejnych etapach.
Przemalowywanie obiektów nowym światłem
Wyposażony w zwartą reprezentację oświetlenia, drugi moduł — generatywna synteza transportu światła (GLTS) — przejmuje kontrolę. GLTS zaczyna od istniejącej neuronowej reprezentacji 3D obiektu lub sceny, wyrenderowanej raz pod starym, „wbudowanym” oświetleniem. Kierowany oszacowanym kierunkiem, intensywnością i opisem tekstowym, sieć generatywna „przemalowuje” ten widok, tak aby refleksy i cienie pasowały do nowego otoczenia. Aby rezultat był zarówno realistyczny, jak i specyficzny dla obiektu, GLTS łączy dwa rodzaje wskazówek: globalną kontrolę z parametrów oświetlenia oraz drobne detale czerpane bezpośrednio z obserwowanego obrazu. Dzięki specjalnemu procesowi treningowemu skupionemu wyłącznie na tym, jak pojedynczy obiekt reaguje na różne oświetlenie, model uczy się przesuwać refleksy i wygładzać krawędzie cieni w sposób fizycznie wiarygodny, zamiast jedynie stosować ogólny filtr stylu.
Budowanie spójnego 3D pola świetlnego z wielu widoków
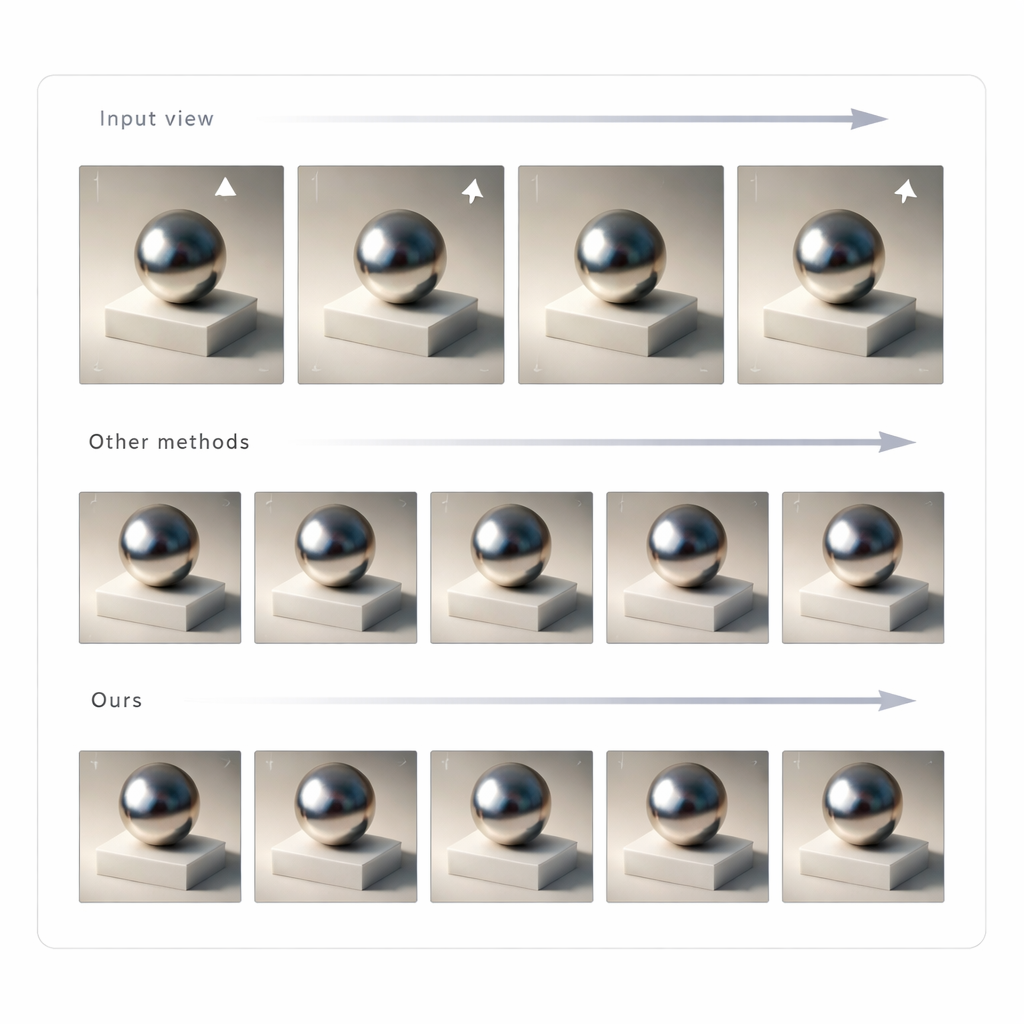
Zmiana pojedynczego obrazu nie wystarczy, by przekonująco działać w rzeczywistości mieszanej; oświetlenie musi pozostać spójne podczas poruszania głową. Aby to osiągnąć, autorzy używają GLTS do wygenerowania zestawu ponownie oświetlonych obrazów z wielu punktów widzenia, a następnie traktują je jako cele przy odbudowie sceny 3D. Proces wspólnej optymalizacji jednocześnie dostosowuje neuronową reprezentację 3D i pozycje wirtualnej kamery, tak aby renderowanie nowego modelu odtwarzało wszystkie wygenerowane widoki. Ten krok koryguje subtelne zniekształcenia wprowadzone przez sieć generatywną i tworzy spójny zasób 3D, którego wygląd pozostaje stabilny i wiarygodny z dowolnego kąta. Zespół porównał swoją metodę z kilkoma nowoczesnymi podejściami do ponownego oświetlania i stwierdził, że dostarcza ostrzejszego dopasowania do obrazów rzeczywistych oraz bardziej naturalnie wyglądających cieni i odbić, ocenianych zarówno metrykami pikselowymi, jak i miarami opartymi na percepcji.
Co to oznacza dla przyszłych zestawów słuchawkowych
Dla osób niebędących specjalistami kluczowy wniosek jest taki: praca pokazuje, jak przyszłe urządzenia VR, AR i rzeczywistości mieszanej mogą dopasowywać zawartość wirtualną do rzeczywistego oświetlenia na podstawie jednego szybkiego spojrzenia przez kamerę w zestawie. Zamiast męczących konfiguracji przechwytywania czy retreningu dedykowanych modeli dla każdej sceny, system estymuje główne warunki oświetleniowe, regeneruje wygląd sceny w tych warunkach i odbudowuje spójną reprezentację 3D. Efektem są wirtualne obiekty, których jasność, połysk i cienie reagują na środowisko podobnie jak obiekty rzeczywiste, co toruje drogę doświadczeniom rzeczywistości mieszanej, które będą mniej przypominać nałożone grafiki, a bardziej prawdziwe dodatki do świata fizycznego.
Cytowanie: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Słowa kluczowe: oświetlenie rzeczywistości mieszanej, neuronalne pola świetlne, relighting z jednego widoku, wyświetlacze rzeczywistości wirtualnej, obrazowanie obliczeniowe