Clear Sky Science · pl
Rozpoznawanie obrazów dziedzictwa kulturowego wielomodalne oparte na sieci fuzji kwantowo-klasycznej
Dlaczego warto uczyć komputery o starożytnych skarbach
Skarby kultury w muzeach i archiwach są coraz częściej fotografowane i udostępniane online, ale większość tych zdjęć jest słabo opisana lub wcale. Utrudnia to odwiedzającym, nauczycielom i badaczom znalezienie tego, czego szukają, i ogranicza głębokość, z jaką społeczeństwo może odkrywać wspólne dziedzictwo ludzkości. Artykuł bada nową metodę automatycznego rozpoznawania i sortowania takich obrazów, łącząc dwa rzadko spotykane elementy: zbiory muzealne i obliczenia kwantowe.
Od zakurzonych magazynów do zbiorów cyfrowych
Współczesne muzea przechowują miliony obiektów — od brązów i lakierowanych przedmiotów po haftowane szaty. Wiele instytucji ściga się w cyfryzacji tych zbiorów, aby każdy z dostępem do internetu mógł je przeglądać. Jednak gdy obrazy trafiają do sieci, muszą być przypisane do właściwych kategorii — takich jak emalia, jadeit, jedwab czy brokat — aby miały praktyczne zastosowanie. Tradycyjne narzędzia sztucznej inteligencji zwykle analizują jedynie piksele zdjęcia. Pomijają bogate opisy tekstowe, które kuratorzy i historycy dołączają do obiektów, mimo że podpisy te często wspominają materiały, kolory i motywy niewidoczne na pierwszy rzut oka. W miarę wzrostu zbiorów klasyczne algorytmy mają też problemy z prędkością, zużyciem energii i złożonością.
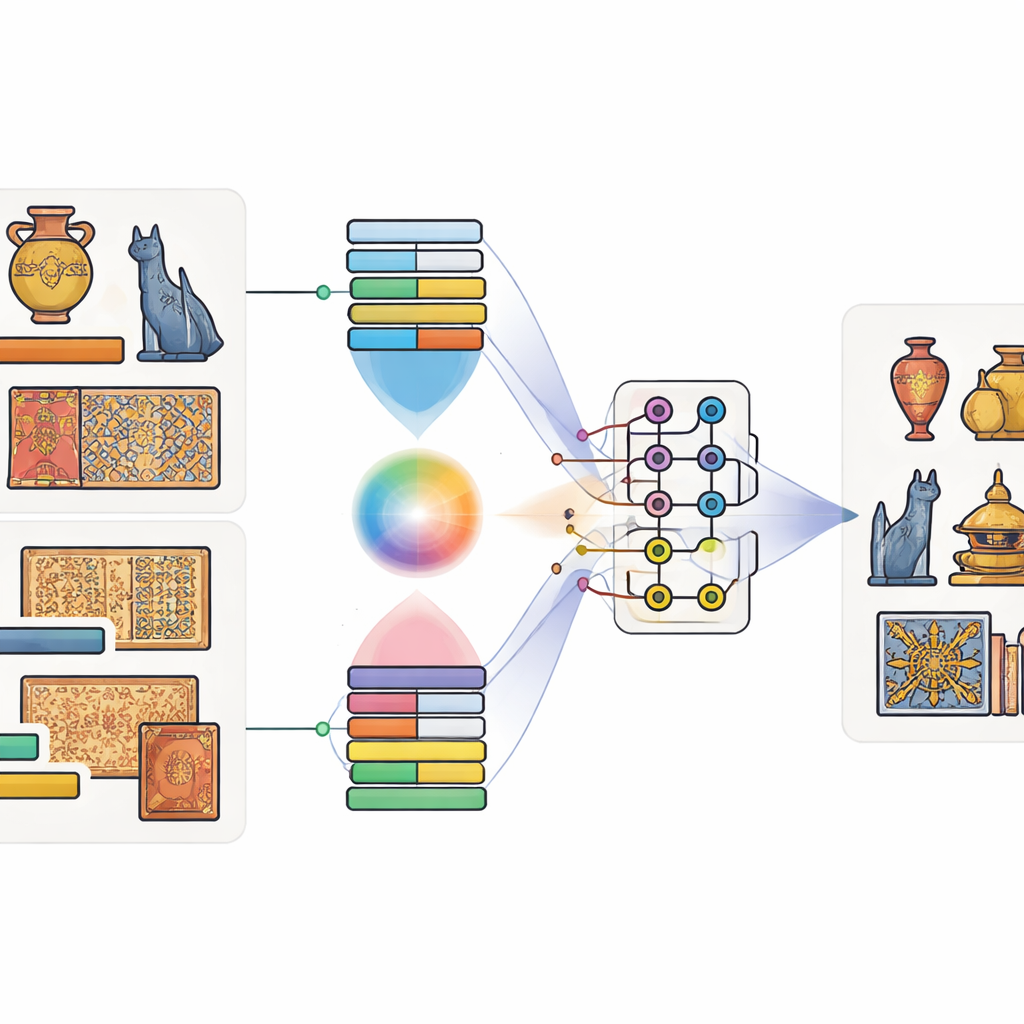
Łączenie obrazów ze słowami oraz bitów z kubitami
Autorzy proponują model nazwany Kwantowo-Klasycznym Modelem Fuzji Wielomodalnej. „Wielomodalny” oznacza po prostu, że uwzględnia więcej niż jeden rodzaj informacji jednocześnie — w tym przypadku zarówno obraz artefaktu, jak i jego podpis. Najpierw wykorzystują sprawdzone narzędzia wytrenowane na ogromnych zbiorach danych: głęboką sieć obrazów do wychwytywania kształtów i tekstur oraz model językowy do uchwycenia znaczenia podpisu. Specjalny mechanizm uwagi uczy się, które obszary obrazu zwykle odpowiadają którym słowom. Na przykład gdy podpis wspomina „złoty smok”, model uczy się koncentrować na złocistych fragmentach o kształcie smoka. Powstaje w ten sposób wspólny opis łączący wrażenia wzrokowe i językowe.
Pozwolenie obwodom kwantowym mieszać sygnały
Gdy cechy obrazu i tekstu zostaną wyodrębnione, model podaje je do niewielkiego symulowanego obwodu kwantowego. Ponieważ obecne urządzenia kwantowe mają tylko umiarkowaną liczbę kubitów, autorzy kompresują informacje za pomocą schematu, który pakuje wiele wartości klasycznych w amplitudy kilku kubitów. W części kwantowej zaprojektowali obwód dwustopniowy, który wielokrotnie stosuje rotacje do pojedynczych kubitów, a następnie splata je — sprawiając, że ich stany stają się współzależne. Taka struktura ma wydobyć subtelne związki między wzorcami wizualnymi a wskazówkami z podpisów, które mogłyby zostać pominięte w inny sposób. Po przetworzeniu kwantowym stan kubitów jest mierzony i konwertowany z powrotem na zwykłe liczby, które następnie trafiają do końcowego klasyfikatora przewidującego kategorię obiektu.
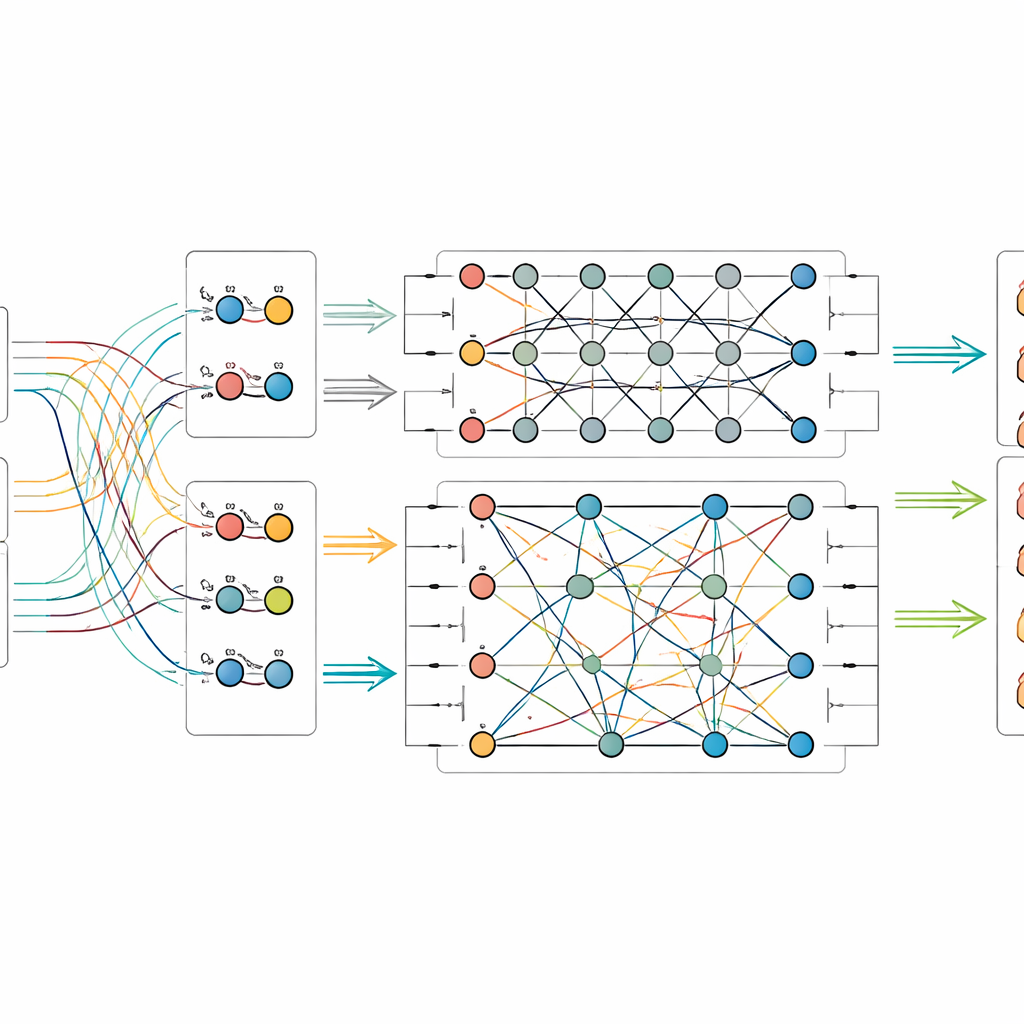
Testowanie nowego podejścia
Aby sprawdzić, czy ich metoda przynosi rzeczywiste korzyści, badacze zebrali dwa nowe zbiory danych z Pałacu Muzeum: jeden obejmujący obiekty fizyczne, takie jak wyroby emaliowane, złoto i srebro, lakier, brąz i jadeit, a drugi skupiony na tkaninach, takich jak jedwab, satyna, brokat i misterny sposób tkania zwany kesi. Każde zdjęcie ma oficjalny podpis i zaufaną etykietę z muzealnych zapisów. Porównali swój model fuzji kwantowo‑klasycznej z szeregiem silnych konkurentów, w tym z systemami opartymi wyłącznie na obrazach, tylko na tekście oraz innymi technikami łączącymi oba źródła informacji. W obu zbiorach nowy model osiągnął najwyższe wyniki pod względem dokładności i powiązanych miar, wyprzedzając nawet zaawansowane wielomodalne i zainspirowane kwantowo rozwiązania bazowe. Dalsze eksperymenty pokazały, jak wydajność zależy od liczby kubitów i głębokości obwodu oraz że model pozostaje niezawodny nawet po wprowadzeniu typowych rodzajów szumów kwantowych w symulacji.
Co to może znaczyć dla przyszłych odwiedzających muzea
Dla osób niebędących specjalistami kluczowy wniosek jest taki, że łączenie obrazów, słów i przetwarzania inspirowanego kwantowo może uczynić komputery lepszymi w rozróżnianiu różnych rodzajów obiektów kulturowych. Choć części kwantowe są obecnie uruchamiane na symulatorach, a nie pełnoskalowych maszynach kwantowych, badanie wyznacza ścieżkę do bardziej wydajnych i ekspresyjnych narzędzi w miarę rozwoju sprzętu. W praktycznym ujęciu takie systemy mogłyby pomóc muzeom i archiwom automatycznie sortować nowe przesyłane materiały, oczyszczać stare zapisy i ułatwiać ludziom wyszukiwanie „jadeitowych naczyń rytualnych” czy „haftowanych szat ze smokami” i rzeczywiste ich znalezienie. Praca sugeruje, że obliczenia kwantowe mogą stać się użyteczną nową drogą do rozumienia i zachowywania dziedzictwa kulturowego w erze cyfrowej.
Cytowanie: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
Słowa kluczowe: obrazy dziedzictwa kulturowego, kwantowe uczenie maszynowe, fuzja wielomodalna, cyfryzacja muzeów, rozpoznawanie obrazów