Clear Sky Science · pl
WCT-Net: wspólna rekonstrukcja malowideł grobowych oparta na splotach falkowych i współpracy transformera z mechanizmem self-attention
Dlaczego ratowanie starych malowideł ściennych wymaga nowych narzędzi
W całych Chinach w starożytnych grobowcach znajdują się malowidła ścienne, które się kruszą, pękają i odspajają na krawędziach. Te freski utrwalają sceny z życia dworskiego, wierzenia i kunszt artystyczny, których już nie możemy oglądać bezpośrednio. Jednak wiele fragmentów jest tak zniszczonych, że nawet eksperci mają trudność z wyobrażeniem sobie ich pierwotnego wyglądu. W tym badaniu przedstawiono nowy rodzaj systemu sztucznej inteligencji, WCT-Net, zaprojektowany do cyfrowego „zaszywania” tych uszkodzonych obrazów, oferując konserwatorom bezpieczniejsze wskazówki oraz bogatsze wizualizacje dla badaczy i odbiorców.
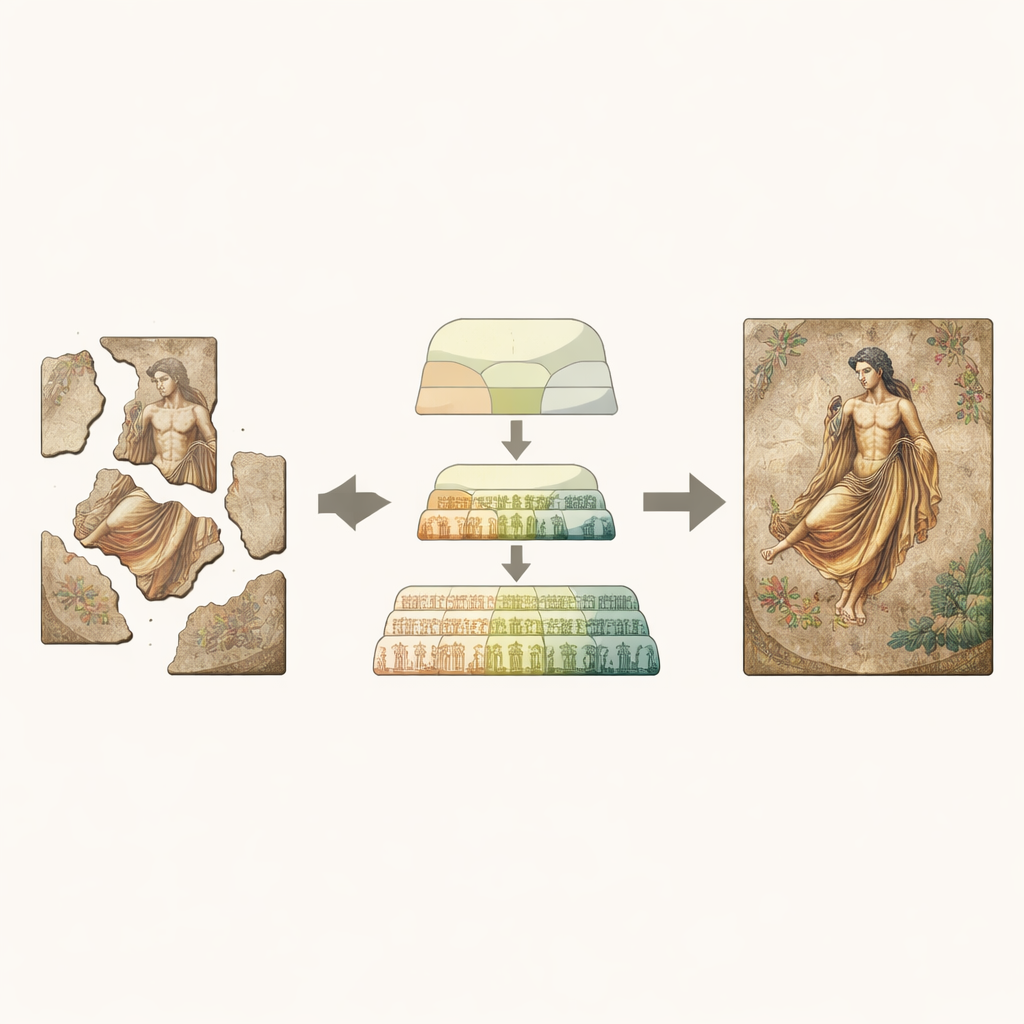
Ukryte problemy wewnątrz zniszczonych malowideł
Malowidła grobowe stoją przed podwójnym zagrożeniem. Przez wieki wilgoć przenika przez glebę i kamień, niosąc sole, które krystalizują w zaprawie. Osłabia to warstwy pod farbą, powodując odspajanie się fragmentów, pękanie i odpadanie. W efekcie często zostaje mały zachowany fragment z dwoma rodzajami uszkodzeń jednocześnie: zewnętrzne krawędzie są utracone, przez co kompozycja jest niekompletna, a wnętrze jest zniekształcone przez blaknięcie, łuszczenie się i drobne pęknięcia. Tradycyjna konserwacja ręczna opiera się na dopasowywaniu fragmentów i ostrożnym ponownym przyklejaniu, ale gdy brakuje dużych obszarów, domysły mogą prowadzić do błędów, a nawet nowych uszkodzeń. Cyfrowa rekonstrukcja obiecuje odwracalną, bezkontaktową alternatywę — pod warunkiem że komputery potrafią zarówno wymyślić wiarygodne brakujące struktury, jak i wiernie zachować zachowane detale.
Dlaczego wcześniejsze cyfrowe rozwiązania zawodzą
Wcześniejsze metody komputerowe w większości uczyły się na nieuszkodzonych częściach tego samego obrazu. Niektóre rozprowadzały kolory i krawędzie z sąsiedztwa w luki; inne kopiowały i wklejały podobne fragmenty z nienaruszonych obszarów. Narzędzia te sprawdzają się przy estetycznie zamkniętych ubytkach, ale zawodzą, gdy brakuje całych granic lub gdy trzeba wnioskować o treści malowidła na podstawie bardzo skąpego kontekstu. Nowsze podejścia oparte na głębokim uczeniu, w tym splotowe sieci neuronowe i sieci generatywne przeciwnikowe, poprawiły realizm, ale wciąż stoją przed kompromisem: albo faworyzują ostre lokalne tekstury kosztem całości, albo zachowują strukturę globalną, zamazując drobne pociągnięcia pędzla. Metody oparte na transformerach, które świetnie radzą sobie z relacjami na duże odległości, pomagają przy rozległych brakach, ale nadal mają trudności z wyrównaniem drobnych detali i dużych kształtów, gdy uszkodzenia obejmują wiele skal.
Dwutorowy „mózg” do widzenia bliskiego i dalekiego
WCT-Net rozwiązuje ten problem, dzieląc zadanie na dwie współpracujące gałęzie w ramach U-kształtnej sieci kodująco-dekodującej. Jedna gałąź używa konwolucji falkowych, sposobu rozdzielania obrazu na gładkie, niskoczęstotliwościowe składowe i ostre, wysokoczęstotliwościowe tekstury. Ucząc się na tych pasmach, gałąź ta specjalizuje się w zachowywaniu drobnych cech, takich jak cienkie linie, fałdy ubioru i subtelne cieniowanie, które nadają malowidłom ręczny charakter. Równolegle, gałąź oparta na transformerze używa mechanizmu self-attention do łączenia odległych części obrazu, wychwytując długodystansowe wzory, takie jak postura konia czy rytm procesji. Ulepszony moduł fuzji uczy się, jak ważyć i mieszać te dwa rodzaje informacji, tak by żaden nie dominował: model jednocześnie szanuje zachowane detale i ekstrapoluje wiarygodną całościową scenę.
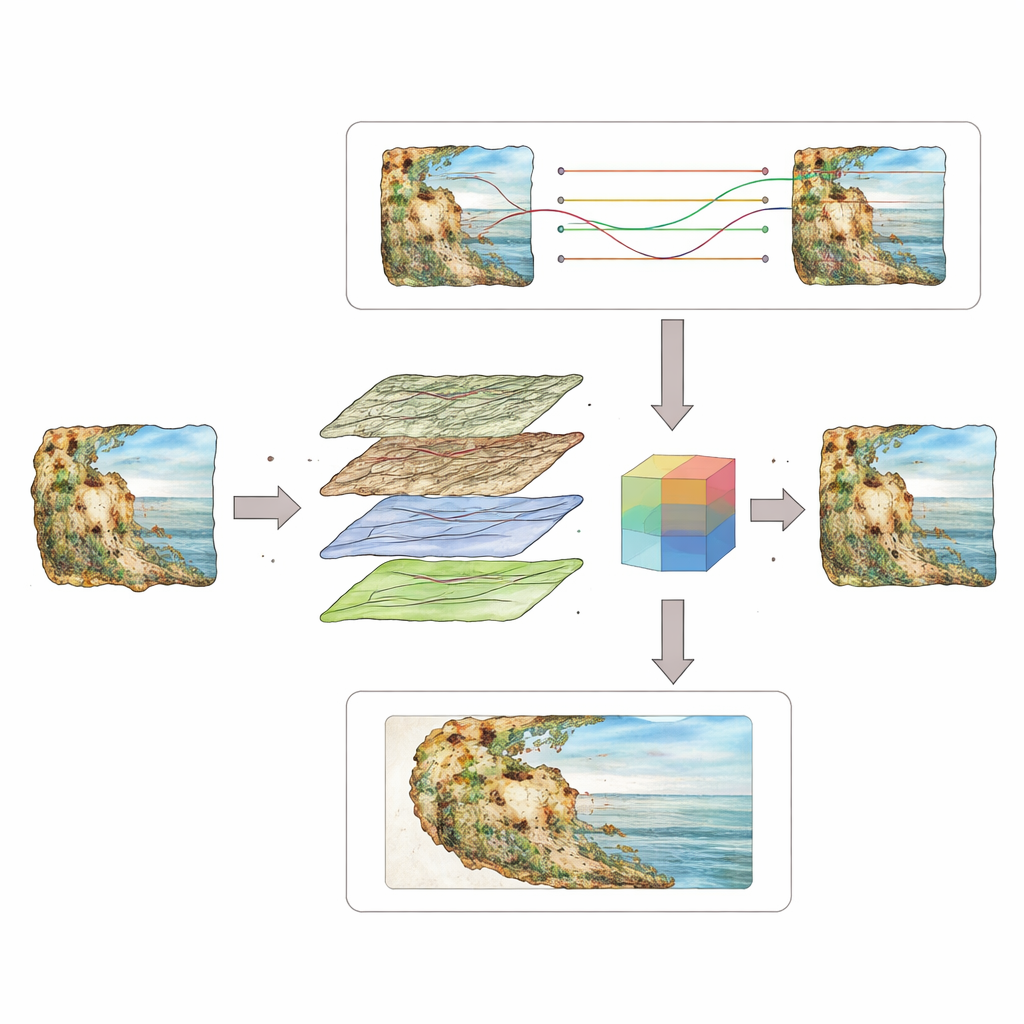
Nauczanie systemu na realistycznych uszkodzeniach
Aby wytrenować i przetestować WCT-Net, autorzy zgromadzili wysokiej jakości zbiór danych z cesarskich malowideł grobowych z Muzeum Historii Shaanxi, dzieląc duże fotografie na mniejsze łatki obrazów. Następnie stworzyli trzy rodziny sztucznych masek uszkodzeń imitujących rzeczywiste zniszczenia: losowe plamki i zarysowania dla wewnętrznego łuszczenia, nieregularne ubytki brzegów jak te spowodowane odpadaniem kawałków zaprawy oraz wzory mieszane łączące oba rodzaje. System nauczył się rekonstruować oryginalne obrazy z tych uszkodzonych wersji. Zespół porównał WCT-Net z siedmioma wiodącymi algorytmami rekonstrukcji, stosując miary uwzględniające zarówno dokładność strukturalną, jak i wizualną naturalność, a także przetestował go na osobnym zbiorze malowideł z Dunhuangu o innym stylu artystycznym.
Bardziej ostre linie, pełniejsze sceny i ich znaczenie
W całym spektrum typów uszkodzeń — wewnętrzne zużycie, utracone krawędzie i złożone kombinacje — WCT-Net wygenerował rekonstrukcje, które utrzymywały ciągłość konturów, ostrość tekstur i bardziej kompletne kompozycje niż metody konkurencyjne. Wyniki obiektywne poprawiły się o kilka procent, a wygenerowane obrazy bliżej odpowiadały ludzkiej percepcji autentyczności. Choć model jest obliczeniowo cięższy od niektórych rywali, jego przewaga jest najbardziej wyraźna tam, gdzie malowidła są najtrudniejsze do interpretacji: gdy zarówno wewnętrzny obraz, jak i jego zewnętrzne granice zostały zaburzone. Dla konserwatorów oznacza to bardziej wiarygodny podgląd cyfrowy przed dotknięciem delikatnych powierzchni; dla historyków i publiczności oferuje jaśniejsze okna do wizualnego świata przeszłości. Autorzy zauważają, że prace przyszłe muszą lepiej radzić sobie z różnorodnymi stylami i działać efektywniej, ale WCT-Net stanowi znaczący krok w kierunku użycia AI jako ostrożnego, świadomego kontekstu partnera w ochronie dziedzictwa kulturowego.
Cytowanie: Li, J., Wu, M., Lu, Z. et al. WCT-Net: joint restoration of tomb murals based on wavelet convolution and transformer self-attention collaborative network. npj Herit. Sci. 14, 151 (2026). https://doi.org/10.1038/s40494-026-02412-y
Słowa kluczowe: cyfrowa rekonstrukcja malowideł, konserwacja dziedzictwa kulturowego, uzupełnianie obrazów, uczenie głębokie dla sztuki, starożytne malowidła grobowe