Clear Sky Science · pl
Identyfikacja informacji wizualnej i pytania i odpowiedzi dotyczące spadkobierców niematerialnego dziedzictwa kulturowego z wykorzystaniem ulepszonego frameworku Graph-Retrieval
Wprowadzanie ukrytych tradycji w erę cyfrową
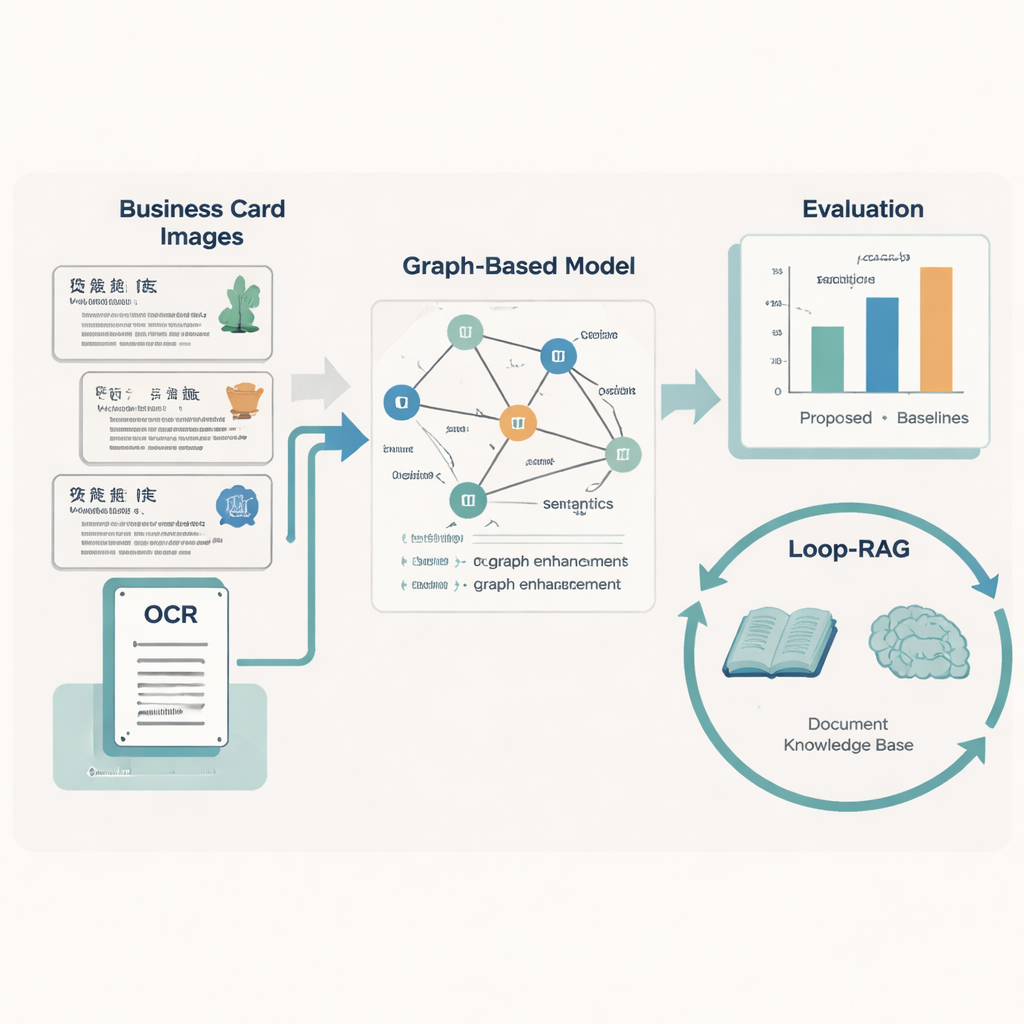
W całych Chinach mistrzowie tradycyjnej opery, wycinanki papierowej, teatrzyków cieni i innych żywych sztuk chronią umiejętności przekazywane z pokolenia na pokolenie. Jednak wiele informacji o tych spadkobiercach istnieje wyłącznie w rozproszonych plikach i obrazach w sieci, co utrudnia publiczności — a nawet badaczom — znalezienie wiarygodnych danych. W artykule przedstawiono nowy komputerowy framework, który automatycznie odczytuje „wizytówki wizualne” spadkobierców niematerialnego dziedzictwa kulturowego (ICH), a następnie wykorzystuje zaawansowane modele językowe do odpowiadania na pytania i tworzenia czytelnych raportów na ich temat.
Od kart obrazkowych do strukturalnej wiedzy
Wiele instytucji kultury publikuje dziś cyfrowe karty łączące tekst, układ i proste grafiki, by przedstawić każdego spadkobiercę: imię, rzemiosło, miejsce, biografię i inne informacje. Ludzie potrafią je przejrzeć wzrokiem, ale komputery mają z tym trudność, ponieważ karty pochodzą z różnych regionów, mają różne wzory i często zawierają brakujące lub uszkodzone fragmenty tekstu. Autorzy zbudowali duży zbiór danych składający się z 5 237 takich wizytówek chińskich spadkobierców ICH, z dokładnym oznaczeniem dziesięciu kluczowych typów informacji, takich jak numer projektu, nazwa projektu, region, płeć, jednostka pracy oraz krótki opis. Najpierw używają rozpoznawania tekstu (OCR), by odczytać tekst i zapisać, gdzie każdy fragment występuje na karcie, a następnie korzystają z dużych modeli językowych, by ustandaryzować etykiety, po czym eksperci ludzie weryfikują wyniki.
Uczenie maszyn czytania układu i znaczenia
Aby przekształcić każdą kartę w czyste, strukturalne dane, zespół zaprojektował model „Graph-Retrieval”, który naśladuje sposób, w jaki ludzie wykorzystują zarówno słowa, jak i układ. Każdy fragment tekstu na karcie staje się węzłem w grafie, a relacje przestrzenne między fragmentami — lewo, prawo, powyżej, poniżej — tworzą krawędzie. Komponent językowy oparty na RoBERTa i dwukierunkowym LSTM uczy się znaczenia tekstu, wspierany przez niestandardowy słownik prawie 5 000 terminów specyficznych dla ICH, dzięki czemu nietypowe nazwy rzemiosł czy lokalne wyrażenia są obsługiwane poprawnie. Na tej warstwie grafowa sieć neuronowa rozprowadza informacje między sąsiednimi węzłami, poprawiając przewidywania dotyczące tego, co reprezentuje dany fragment tekstu (na przykład decydując, czy nazwa miejsca to region, czy jednostka pracy).
Uodparnianie systemu na realne niedoskonałości
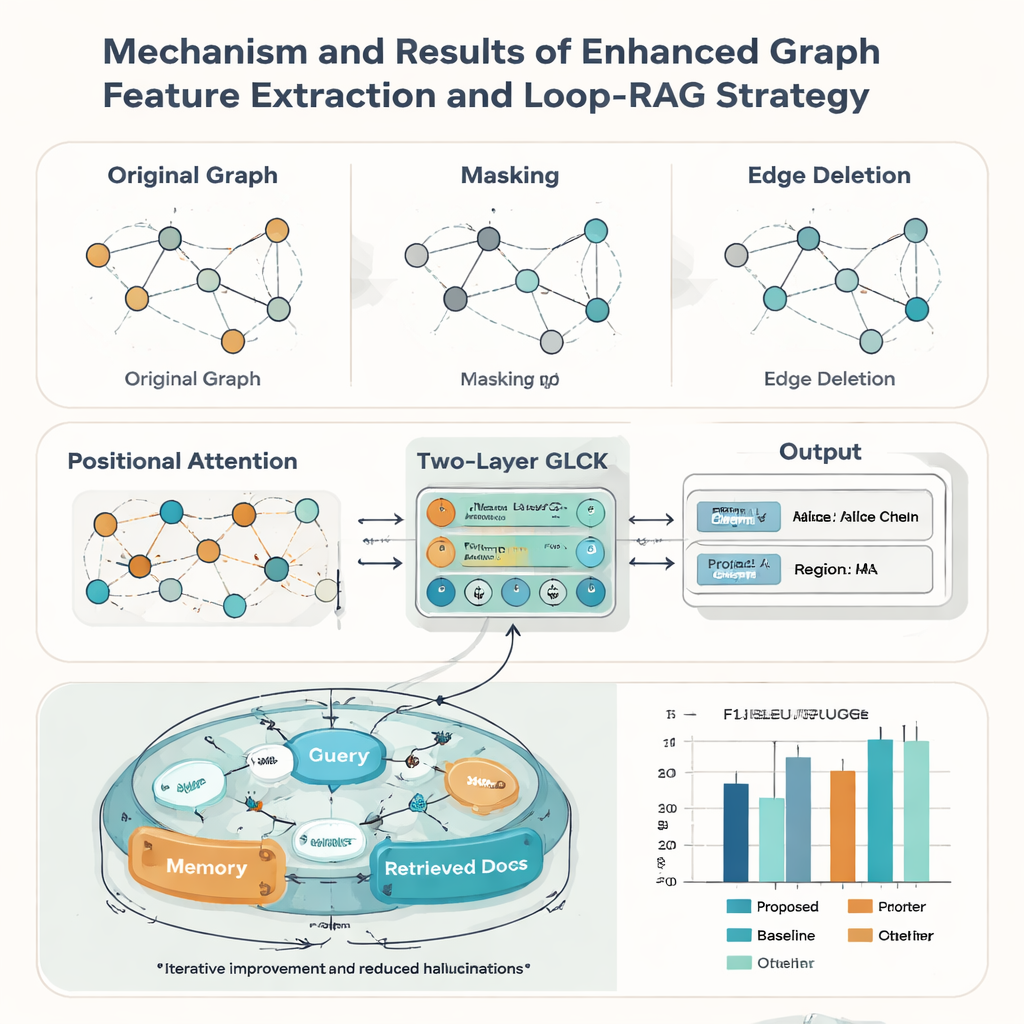
Rzeczywiste zapisy dziedzictwa rzadko są idealne: karty mogą być zużyte, przycięte lub źle zeskanowane. Aby sobie z tym poradzić, autorzy wzmocnili swój model grafowy trzema pomysłami zapożyczonymi z augmentacji danych. Losowo maskują niektóre węzły, tak by system nauczył się wywnioskowywać brakujące informacje z kontekstu; losowo usuwają niektóre krawędzie, by był odporny na zmiany układu; oraz dodają mechanizm uwagi pozycyjnej, który wychwytuje ogólny „porządek czytania” elementów na karcie. Razem te zabiegi pomagają modelowi uogólniać do wielu stylów i jakości dokumentów. W testach przeciwko dziewięciu znanym konkurencyjnym metodom nowe podejście osiąga najwyższy makrośredni wynik F1 (0,928) na zbiorze kart ICH i prowadzi także na pięciu publicznych benchmarkach dokumentów, co sugeruje, że jest szeroko użyteczne poza zastosowaniami w dziedzictwie.
Sprytniejsze odpowiadanie na pytania dzięki pętlowemu retrievalowi
Rozpoznanie tekstu to tylko połowa historii; drugim wkładem artykułu jest strategia Loop-RAG (Loop Retrieval-Augmented Generation), która współpracuje z dużymi modelami językowymi takimi jak GPT-4, Llama czy ChatGLM. Tradycyjne systemy z retrieval-augmented pobierają dokumenty kontekstowe raz, a następnie generują odpowiedź, która może być nadal niepełna lub błędna. W przeciwieństwie do tego Loop-RAG dodaje wewnętrzną pętlę, która wielokrotnie sprawdza, czy model językowy ma wystarczająco informacji do udzielenia bieżącej odpowiedzi i, jeśli nie, wywołuje kolejne ukierunkowane wyszukiwanie w wektoryzowanej bazie wiedzy ICH. Zewnętrzna pętla analizuje zaś wiele wcześniejszych interakcji, by nauczyć się, które ścieżki wyszukiwania i style promptów działają najlepiej, stopniowo zmniejszając zbędne wyszukiwania i błędy merytoryczne.
Od surowych zapisów do wiarygodnych opowieści kulturowych
Dzięki temu połączonemu frameworkowi system może automatycznie tworzyć krótkie raporty o spadkobiercy — podsumowując jego rzemiosło, region, reprezentatywne prace i status — oraz odpowiadać na tysiące faktograficznych pytań o osoby i praktyki. Mierzony standardowymi miarami jakości językowej, takimi jak BLEU, METEOR i ROUGE, Loop-RAG z GPT-4 przewyższa zarówno same modele językowe, jak i prostsze konfiguracje z retrievalem, osiągając jednocześnie najlepszą dokładność (F1 do 0,941) w zadaniu odpowiadania na pytania, nawet gdy dostępnych jest tylko kilka przykładów. Dla czytelnika niebędącego specjalistą oznacza to, że przyszłe platformy dziedzictwa kulturowego mogą oferować interaktywne, wiarygodne wyjaśnienia tradycyjnych sztuk na żądanie, przekształcając rozproszone cyfrowe zapisy w bogate, przeglądalne opowieści, które pomagają utrzymać żywe tradycje widoczne i docenione.
Cytowanie: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Słowa kluczowe: niematerialne dziedzictwo kulturowe, ekstrakcja informacji, grafowe sieci neuronowe, retrieval-augmented generation, humanistyka cyfrowa