Clear Sky Science · pl
Wysokiej wierności rekonstrukcja 3D dziedzictwa kulturowego za pomocą super-rozdzielczości i progresywnego Gaussian splatting
Dlaczego wyraźniejsze cyfrowe relikty mają znaczenie
Muzea i archeolodzy na całym świecie ścigają się, by tworzyć wierne kopie 3D delikatnych artefaktów — od porcelanowych wazonów po bramy świątynne. Te cyfrowe odpowiedniki pozwalają badać, udostępniać i zachowywać skarby kultury bez dotykania oryginałów. W rzeczywistości jednak zdjęcia obiektów dziedzictwa często są ciemne, rozmyte lub wykonane pod niefortunnymi kątami, co może sprawić, że współczesne metody rekonstrukcji 3D wygenerują zniekształcone lub niekompletne modele. Artykuł przedstawia nowe podejście, które radzi sobie z tym problemem kompleksowo — zarówno oczyszczając zdjęcia wejściowe, jak i stabilizując proces modelowania 3D.
Kiedy złe zdjęcia psują modele 3D
Obecne potoki przechwytywania 3D zwykle opierają się na prostej idei: zrobić wiele zdjęć, oszacować położenie każdej kamery, wywnioskować kształt obiektu i w końcu renderować model 3D. W praktyce miejsca dziedzictwa rzadko oferują warunki studyjne. Niskie oświetlenie, zużyte lub nierówne powierzchnie, odbicia od gablot i ograniczenia w ustawieniu kamer pogarszają jakość obrazów. Autorzy pokazują, jak te wady rozchodzą się w całym potoku. Rozmyte lub niskoresolucyjne zdjęcia utrudniają oprogramowaniu dopasowanie cech między widokami, co prowadzi do błędów w pozycjach kamer i nierównych oszacowań głębi. Gdy te zawodna miary trafiają do współczesnych rendererów opartych na „Gaussian splatting” — systemów budujących sceny z tysięcy małych kolorowych plamek — efektem może być niestabilna optymalizacja, nadmiarowe plamki i widoczne zniekształcenia geometrii.
Wyostrzenie zdjęć za pomocą inteligentniejszego ulepszania obrazu
Aby zatrzymać błędy u źródła, autorzy najpierw budują wyspecjalizowaną sieć do „super-rozdzielczości”, która zamienia zdjęcia dziedzictwa niskiej jakości w ostrzejsze, bogatsze w szczegóły obrazy. Zamiast polegać na jednym rodzaju przetwarzania, sieć łączy dwie zalety. Moduł konwolucyjny wieloskalowy koncentruje się na lokalnych detalach — takich jak pęknięcia, pociągnięcia pędzla czy rzeźbione linie — analizując obraz na kilku rozmiarach sąsiedztwa jednocześnie. Następnie wydajny moduł Transformer wychwytuje szersze wzorce, takie jak powtarzające się motywy czy długie krzywizny przebiegające przez obiekt. Trzeci komponent selektywnie wzmacnia rzeczywiście podobne obszary obrazu, tłumiąc jednocześnie szum, tak aby słabe tekstury były wyraźniejsze, a nie rozmyte. Razem te elementy generują obrazy wysokiej rozdzielczości, które zachowują zarówno drobne zdobienia, jak i ogólną strukturę, dając późniejszym etapom 3D znacznie lepszy punkt wyjścia.
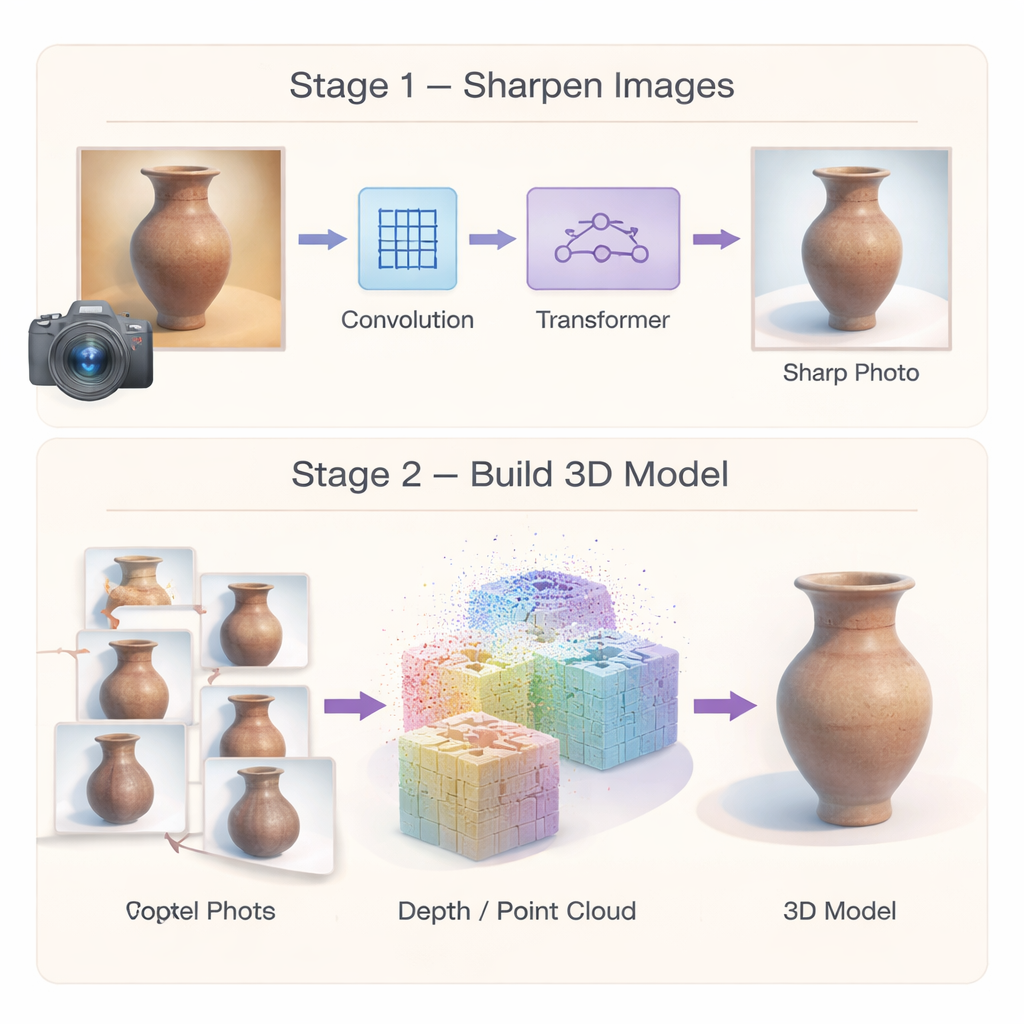
Budowanie stabilniejszych kształtów 3D z wielu widoków
Samo poprawienie obrazów nie wystarcza; sama rekonstrukcja 3D musi być również odporna na błędy. Druga część ramy przemyśla, jak inicjowany i optymalizowany jest model 3D. Zamiast polegać na rzadkim zbiorze dopasowanych punktów, autorzy używają metody „gęstego” dopasowania, która od samego początku generuje bogate chmury punktów i bardziej wiarygodne pozycje kamer. Te gęste punkty służą jako mocny szkielet geometryczny sceny. Na tym tle wprowadzają hybrydową reprezentację: przestrzeń wokół artefaktu dzielona jest na grube komórki 3D, a wspólny dekoder przewiduje szczegółowy kolor i kształt wielu małych plamek w każdej komórce. Ponieważ parametry są w dużej mierze współdzielone zamiast powielane, metoda zmniejsza zużycie pamięci i sprzyja gładkim, spójnym powierzchniom, sprawiając, że końcowy model jest mniej podatny na losowe guzki i dziury.
Szkolenie krokami zamiast wszystkiego naraz
Autorzy zmieniają też sposób szkolenia systemu. Zamiast zmuszać model od początku do dopasowania jednocześnie wyglądu i geometrii — co sprzyja utknięciu w słabych rozwiązaniach — przyjmują strategię w trzech etapach. Najpierw system uczy się jedynie odtwarzać kolory zdjęć wejściowych, zapewniając globalną spójność wizualną. Następnie stopniowo dodaje informacje o głębi pochodzące z gęstych chmur punktów, które kierują model ku prawdopodobnym powierzchniom. W ostatnim etapie dopracowuje drobne detale, wymuszając zgodność w pokrywających się fragmentach obrazów z różnych widoków. Testowana na nowym zbiorze Cultural‑Relics obejmującym porcelanę, meble, rękodzieło i tkaniny, jak również na standardowym benchmarku złożonych scen zewnętrznych, etapowa metoda nie tylko poprawia jakość wizualną, ale też skraca czas szkolenia i zużycie pamięci w porównaniu z wiodącymi alternatywami.
Co to oznacza dla zachowania przeszłości
Dla osób niebędących specjalistami kluczowy przekaz jest prosty: ta metoda pomaga przekształcać niedoskonałe zdjęcia muzealne lub terenowe w czyściejsze, bardziej dokładne repliki 3D obiektów dziedzictwa kulturowego, bez fizycznego kontaktu z nimi. Poprzez wyostrzanie zdjęć niskiej jakości, start z solidniejszego szkieletu geometrycznego i szkolenie modelu 3D w starannie kontrolowanych etapach, metoda produkuje cyfrowe artefakty, które lepiej oddają drobne zdobienia i ogólny kształt przy mniejszym wykorzystaniu zasobów obliczeniowych. W praktyce ułatwia to muzeom, konserwatorom i badaczom budowanie wiarygodnych wirtualnych kolekcji z zwykłych sesji fotograficznych, pomagając chronić delikatne obiekty i szeroko udostępniać je naukowcom oraz publiczności.
Cytowanie: Jia, Q., He, J. High-fidelity 3D reconstruction of cultural heritage via super-resolution and progressive Gaussian splatting. npj Herit. Sci. 14, 84 (2026). https://doi.org/10.1038/s40494-026-02355-4
Słowa kluczowe: digitalizacja dziedzictwa kulturowego, rekonstrukcja 3D, super-rozdzielczość obrazu, Gaussian splatting, cyfrowa konserwacja