Clear Sky Science · pl
Geo-TCAM: metoda opisu Thanków łącząca modelowanie tematów z geometrycznie sterowaną uwagą przestrzenną
Starożytna sztuka spotyka inteligentną technologię
Malowidła Thangka — żywo kolorowe zwoju widywane w wielu tybetańskich świątyniach — są pełne drobnych detali i warstw religijnego znaczenia. Dla zwiedzających muzea lub odbiorców online bez specjalistycznego wykształcenia większość tej symboliki bywa trudna do rozszyfrowania. W tym badaniu przedstawiono Geo‑TCAM, system sztucznej inteligencji zaprojektowany do automatycznego generowania bogatych, precyzyjnych opisów obrazów Thangka, pomagając ludziom na całym świecie lepiej rozumieć i zachować to unikatowe dziedzictwo kulturowe.
Dlaczego obrazy Thangka są trudne dla komputerów
W przeciwieństwie do zwykłych zdjęć, dzieła Thangka są celowo gęste i symboliczne. Jeden obraz może zawierać centralną bóstwo, dziesiątki mniejszych postaci, wzorzyste ramy oraz specyficzne gesty dłoni, przedmioty, kolory i pozy, z których każdy ma religijne znaczenie. Standardowe programy do opisywania obrazów radzą sobie zwykle dobrze z prostymi scenami typu „pies na plaży”, ale tutaj mają trudności: mogą poprawnie nazwać głównego Buddę, a jednocześnie przegapić, czy trzyma on misę czy miecz, błędnie odczytać jego postawę lub pomylić go z innym bóstwem o podobnym wyglądzie. Takie błędy nie są błahostką — potrafią odwrócić przekaz i doktrynę, które obraz ma przedstawiać, podważając jego wartość edukacyjną i kulturową.
Nowy plan opisywania świętych obrazów
Geo‑TCAM rozwiązuje te problemy, łącząc trzy pomysły: wielopoziomowe cechy wizualne, wiedzę tematyczną o sztuce Thangka oraz geometrycznie sterowaną uwagę skierowaną na kluczowe obszary jak twarze. Po pierwsze, wykorzystuje głęboką sieć (ResNet50), aby analizować obraz na kilku poziomach jednocześnie: warstwy średnie wychwytują krawędzie, tekstury i proste kształty, podczas gdy warstwy głębsze podsumowują ogólną kompozycję. Poprzez łączenie tych poziomów model może dostrzec zarówno drobne detale, takie jak ozdoby, jak i szeroki układ tła i postaci, oferując bogatsze rozumienie wizualne niż wcześniejsze systemy skoncentrowane na pojedynczej warstwie. 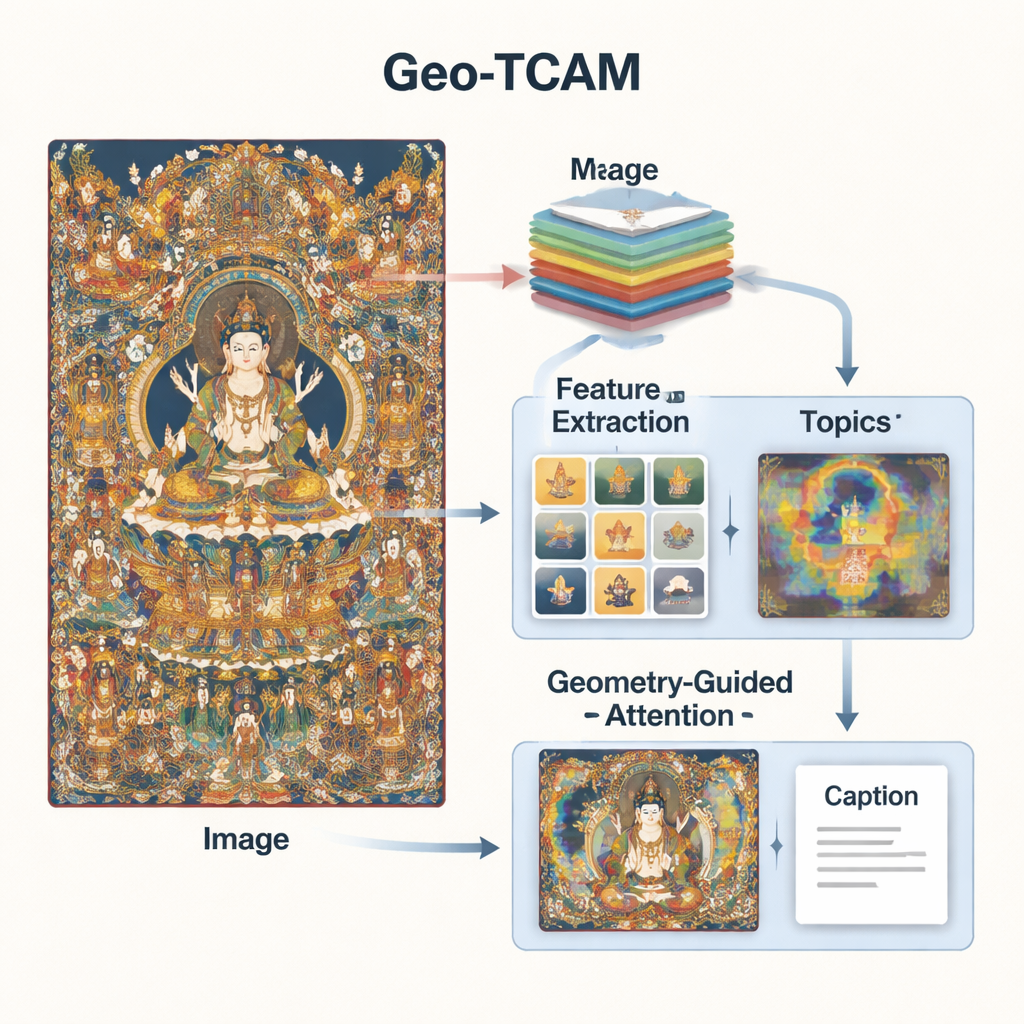
Nauczanie modelu „tematów” Thangka
Sam obraz to za mało; system potrzebuje też pewnego wyczucia języka i tematów Thangka. Aby to zapewnić, badacze przeszkolili model tematów na tysiącach ekspercko napisanych opisów Thangka. Model ten grupuje słowa w kilka typowych tematów — na przykład związanych z Buddami, Bodhisattwami, lotosowymi tronami, przedmiotami rytualnymi czy bóstwami ochronnymi. Dla każdego nowego obrazu Geo‑TCAM ocenia, które tematy są najbardziej istotne i miesza tę informację z cechami wizualnymi. Mechanizm uwagi następnie wyróżnia regiony obrazu najlepiej dopasowane do prawdopodobnych tematów. W praktyce uprzednia wiedza o tym, które obiekty i symbole występują razem, skłania sztuczną inteligencję do tworzenia bardziej znaczących, kulturowo świadomych opisów.
Pozwalanie AI „patrzeć” tam, gdzie to najważniejsze
Trzecią innowacją jest moduł geometrycznie sterowanej przestrzennej uwagi twarzy (GFSA). Kompozycje Thangka zwykle lokują twarz głównej postaci w przewidywalnych obszarach obrazu. Geo‑TCAM korzysta z prostych narzędzi wykrywania krawędzi, aby zlokalizować ten rejon oraz otaczające go dłonie i postawę, a następnie stosuje dedykowany mechanizm uwagi, który zwiększa wpływ tych pikseli przy formułowaniu podpisu. Strategia „najpierw zlokalizuj, potem skieruj” pomaga zapobiegać wczesnej błędnej identyfikacji centralnej postaci, co w przeciwnym razie prowadziłoby do łańcuchów tekstowych błędów dotyczących gestów, atrybutów i rangi. Mapy cieplne wizualizacji pokazują, że dzięki GFSA model koncentruje się wyraźniej na twarzy głównej postaci i kluczowych przedmiotach, jednocześnie śledząc ważne motywy tła. 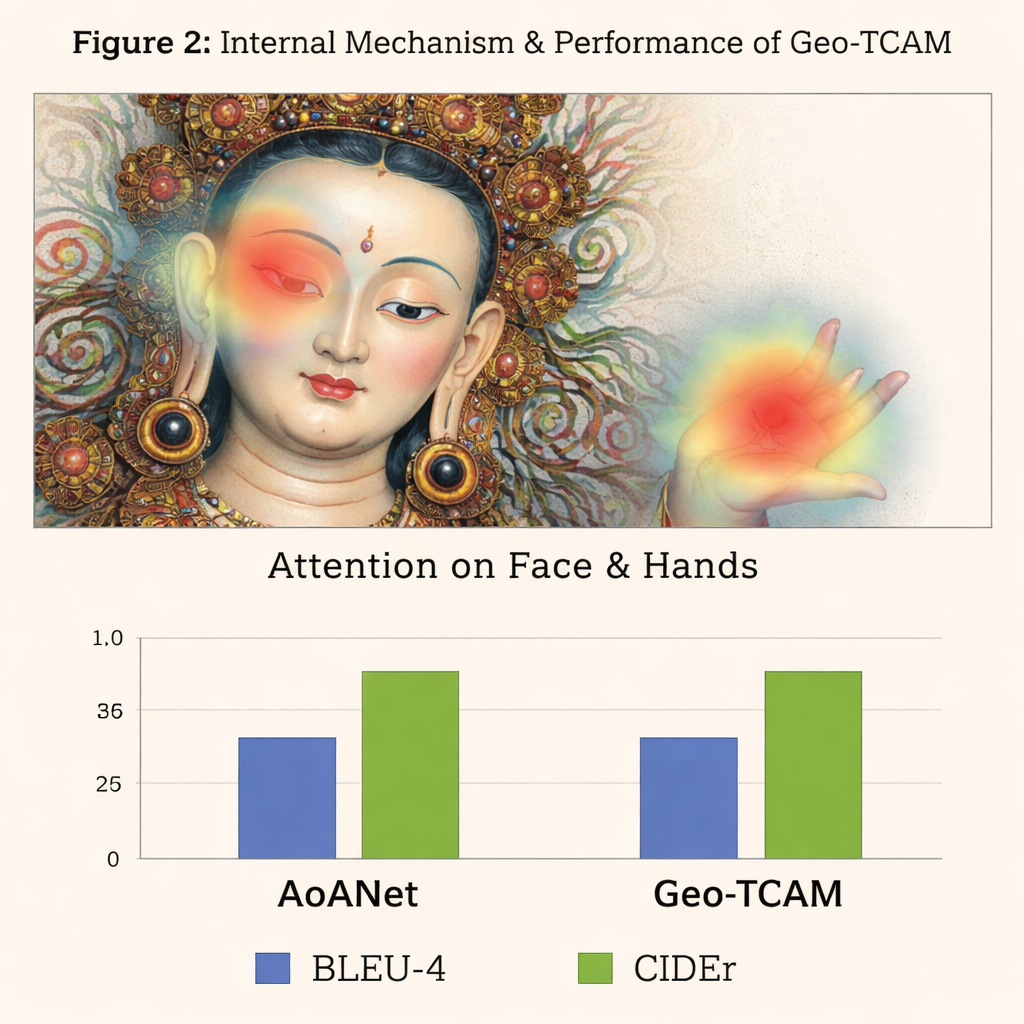
Jak dobrze działa Geo‑TCAM?
Aby przetestować swoje podejście, autorzy zbudowali specjalistyczny zbiór D‑Thangka obejmujący prawie 4 000 starannie oznakowanych obrazów, z których każdy ma szczegółowe opisy ekspertów. Na tym zbiorze Geo‑TCAM wyraźnie przewyższał kilka silnych systemów opisywania, w tym popularny AoANet oraz duże modele wizualno‑językowe. W zależności od metryki jego wyniki poprawiły się nawet o około 120% względem bazowego rozwiązania, a oceniający ludzie zdecydowanie preferowali jego podpisy pod względem dokładności, płynności i bogactwa szczegółów. Co ważne, gdy ten sam model oceniano na standardowym zbiorze zdjęć codziennych (COCO), pozostawał konkurencyjny wobec wiodących metod, pokazując, że jego konstrukcja jest wydajna, a jednocześnie ogólnego przeznaczenia.
Co to oznacza dla dziedzictwa i nie tylko
Dla osób niebędących ekspertami główne wnioski są takie, że Geo‑TCAM potrafi przekształcić wizualnie złożone obrazy Thangka w jasne, informacyjne narracje, które podkreślają, kogo przedstawiono, co robią i dlaczego te szczegóły są istotne. Poprzez łączenie wielowarstwowej analizy wizualnej, wyuczonych tematów z tekstów eksperckich oraz specjalnej uwagi na twarze i gesty, system dopasowuje swoje opisy o wiele bliżej do sposobu, w jaki specjaliści interpretują te dzieła sztuki. W dłuższej perspektywie takie narzędzia mogą wspierać archiwa cyfrowe, przewodniki muzealne i platformy edukacyjne, ułatwiając dostęp do ezoterycznej sztuki religijnej i pomagając konserwatorom oraz badaczom dokumentować i chronić kruchą spuściznę kulturową.
Cytowanie: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Słowa kluczowe: Opis obrazów Thangka, Sztuczna inteligencja dziedzictwa kulturowego, uwaga wizualna, modelowanie tematów, ochrona dzieł sztuki