Clear Sky Science · pl
M3SFormer: wieloetapowy transformator łączący semantykę i styl do uzupełniania obrazów fresków
Przywracanie wyblakłej sztuki ściennej do życia
W świątyniach i jaskiniach w Chinach antyczne freski i malowidła na zwojach stopniowo się rozpadają — pigment łuszczy się, twarze znikają, a całe sceny giną z biegiem czasu. Konserwatorzy coraz częściej polegają na narzędziach cyfrowych, zarówno by bezpiecznie badać te dzieła, jak i wyobrazić sobie ich pierwotny wygląd. W artykule przedstawiono M3SFormer, nowy system sztucznej inteligencji zaprojektowany specjalnie do „inpaintingu” uszkodzonych fresków i tradycyjnych malowideł, wypełniający brakujące obszary przy zachowaniu oryginalnej struktury, kolorów i stylu artystycznego.

Dlaczego stare freski są tak trudne do naprawienia
Restauracja historycznych malowideł ściennych jest znacznie bardziej wymagająca niż łatanie rodzinnego zdjęcia. Freski często zawierają gęste wzory, delikatne pociągnięcia pędzla i ostre granice kolorystyczne między postaciami, szatami a tłem. Wcześniejsze metody głębokiego uczenia, szczególnie oparte na standardowych sieciach konwolucyjnych, sprawdzają się przy drobnych zadrapaniach, lecz zawodzą, gdy brakuje dużych fragmentów. Mogą rozmywać istotne linie, wymyślać kształty niepasujące do otoczenia albo wygładzać dramatyczne kontrasty, które nadają freskom ich charakter. Inne podejścia nadmiernie kompresują informacje obrazowe, tracąc wysokoczęstotliwościowe detale — cienkie pęknięcia, włosowe kreski, faktury tkanin — na których konserwatorom szczególnie zależy.
Trzystopniowy cyfrowy proces restauracji
M3SFormer mierzy się z tymi wyzwaniami dzięki podejściu od ogółu do szczegółu, w wieloetapowym potoku. Najpierw krok Global Structure Reasoning dzieli obraz na małe płaty i używa transformera — modelu pierwotnie opracowanego do języka — by zrozumieć, jak odległe części fresku ze sobą współgrają. Poprzez modelowanie połączeń na długim dystansie bez typowej utraty informacji wynikającej z silnej kwantyzacji, ten etap buduje szczegółowy, globalny plan struktury malowidła. Następnie etap Semantic–Stylistic Consistency wprowadza dwa rodzaje wysokopoziomowych wskazówek: segmentuje obraz na sensowne regiony (takie jak twarze, szaty czy tło) i, korzystając z wstępnie wytrenowanej sieci, uczy się charakterystycznych faktur i kolorów dla każdego regionu. Wreszcie etap Flow-Guided Refinement traktuje restaurację jako stopniową ewolucję, używając nauczonego „pola prędkości”, aby krok po kroku przesuwać początkową hipotezę w stronę spójnego wizualnie rezultatu.
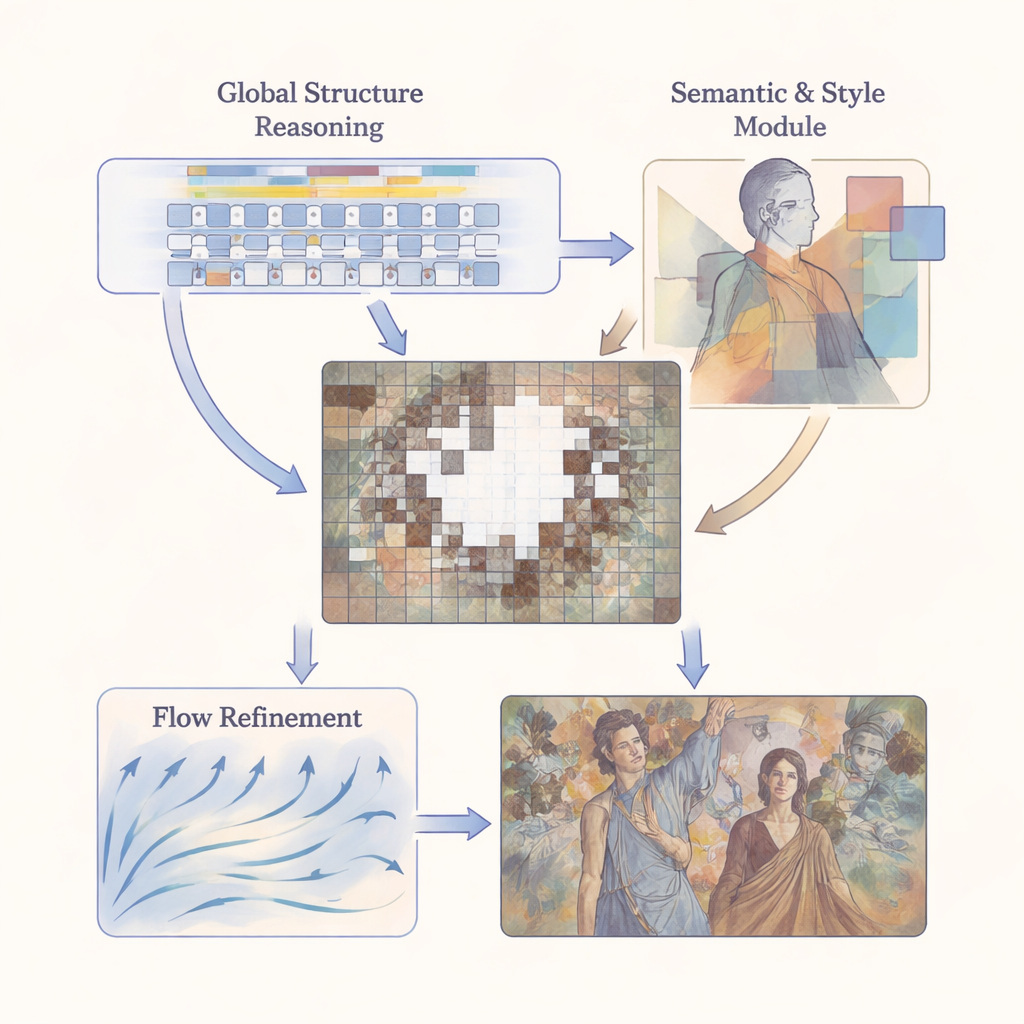
Utrzymanie harmonii struktury i stylu
Centralna idea pracy polega na tym, że treść i styl muszą być traktowane razem, ale nie mylone. Komponent semantyczny modelu, oparty na silnym systemie segmentacji znanym jako Mask2Former, informuje sieć, gdzie zaczynają się i kończą różne elementy sceny. Na to nakłada się komponent stylu, mierzący, jak blisko przywrócone obszary odpowiadają oryginałowi w każdej semantycznej strefie, przy użyciu wielowarstwowego porównania wzorców cech (przez macierze Grama) na wielu skalach. Dzięki temu system może traktować twarz postaci inaczej niż zdobioną szatę czy pochmurne niebo, zamiast stosować jedną globalną regułę stylu, która zatarłaby lokalne różnice. Na etapie dopracowywania maski semantyczne działają jak barierki dla pola przepływu, zapewniając, że wypełniane piksele ewoluują w sposób zgodny zarówno ze strukturą, jak i ze stylem.
Testowanie metody
Aby sprawdzić, jak dobrze M3SFormer działa w realistycznych warunkach, autorzy zgromadzili dwa duże zbiory danych: jeden z chińskimi freskami z różnych regionów, drugi z tradycyjnymi pejzażami. Symulowali uszkodzenia za pomocą masek wzorowanych na rzeczywistych pęknięciach i brakujących fragmentach, a następnie porównali swoją metodę z siedmioma najnowocześniejszymi alternatywami, obejmującymi systemy oparte zarówno na transformerach, jak i na dyfuzji. W standardowych miarach jakości obrazu, podobieństwa strukturalnego i realizmu percepcyjnego M3SFormer konsekwentnie osiągał najlepsze wyniki, szczególnie gdy obszar uszkodzony był duży i złożony. Porównania wizualne pokazują, że unika on rozmyć, dziwnych plam kolorów i szumowatych kropek, które trapią wiele konkurencyjnych metod, przy jednoczesnym zachowaniu praktycznej szybkości działania nadającej się do zastosowań rzeczywistych.
Ograniczenia, wnioski i przyszłe możliwości
Pomimo zalet M3SFormer nie jest remedium na wszystkie problemy. W obliczu bardzo dużych braków czy skomplikowanych wzorów wciąż może „halucynować” detale niezgodne z historyczną rzeczywistością — ważne ostrzeżenie dla konserwatorów, którzy zawsze muszą rozgraniczać przypuszczalną rekonstrukcję od spekulacji. Autorzy sugerują, że przyszłe wersje powinny włączać explicite wskazówki, takie jak szkice czy krótkie opisy tekstowe, aby ograniczyć swobodę wyobraźni modelu. Nawet z tymi zastrzeżeniami podejście oferuje potężne nowe narzędzie dla muzeów i badaczy: sposób generowania szczegółowych, stylistycznie wiernych cyfrowych rekonstrukcji, eksplorowania nieinwazyjnych „co-jeśli” w restauracji oraz pomagania w zapewnieniu, że kruche skarby kultury będą mogły być badane i podziwiane długo po wyblaknięciu oryginalnych pigmentów.
Cytowanie: Hu, Q., Ge, Q., Zhang, Y. et al. M3SFormer: multi-stage semantic and style-fused transformer for mural image inpainting. npj Herit. Sci. 14, 64 (2026). https://doi.org/10.1038/s40494-026-02325-w
Słowa kluczowe: cyfrowa konserwacja fresków, inpainting obrazów, dziedzictwo kulturowe, modele transformerowe, konserwacja dzieł sztuki