Clear Sky Science · pl
Budowa korpusu Dwudziestu Czterech Historii z oznaczonymi częściami mowy (starożytno‑nowoczesny)
Dlaczego stare kroniki mają znaczenie w erze sztucznej inteligencji
Przez ponad dwa tysiąclecia chińscy kronikarze zapisywali wojny, dwory, klęski głodu i codzienne życie w rozległej serii znanej jako Dwudziestocztery Historie. Dziś te klasyczne teksty są na nowo odkrywane nie tylko przez uczonych, lecz także przez komputery. Badanie opisuje, jak badacze przekształcili te starożytne kroniki oraz ich współczesne tłumaczenia na chiński w starannie oznakowaną bazę językową. Zasób ten może pomóc sztucznej inteligencji w czytaniu, tłumaczeniu i analizie tekstów historycznych z większą dokładnością — i uczynić odległą przeszłość znacznie bardziej dostępną dla odbiorców.
Z zakurzonych tomów do tekstu cyfrowego
Projekt zaczyna się od podstawowego, lecz zniechęcającego zadania: przekształcenia milionów drukowanych znaków w czysty, dokładny tekst cyfrowy. Zespół korzystał z dwóch źródeł — definitywnego nowoczesnego wydania Dwudziestu Czterech Historii oraz dużego internetowego zbioru — aby zasilić system rozpoznawania znaków (OCR). Następnie skrupulatnie usuńęli zniekształcone fragmenty, poprawili błędnie odczytane znaki i oczyścili tekst z szumów, takich jak nagłówki i stopki stron. W rezultacie powstał zestaw plików równoległych, jeden w starożytnym chińskim i drugi we współczesnym chińskim, wiernie odzwierciedlający oryginalne książki, a jednocześnie gotowy do analizy komputerowej. 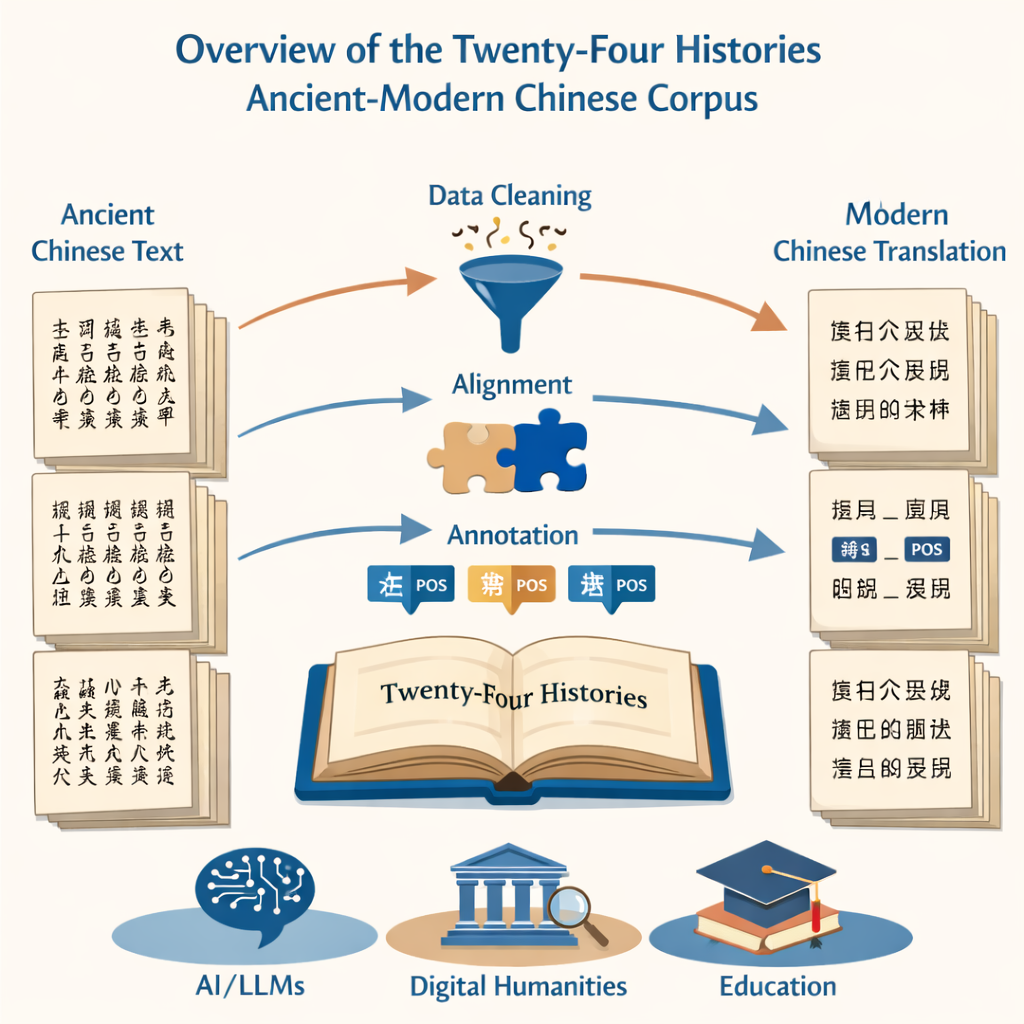
Parowanie zdań starożytnych z ich nowoczesnymi odpowiednikami
Ponieważ celem było porównanie zmian językowych w czasie, kluczowe było dopasowanie starych i nowych wersji zdanie po zdaniu. Badacze użyli wyspecjalizowanego oprogramowania do wyrównywania, najpierw łącząc akapity, a potem dzieląc je na odpowiadające sobie zdania. Narzędzia automatyczne wykonały zasadniczą pracę, lecz eksperci ludzie musieli przeglądać każdą sugerowaną parę, ponieważ gramatyka starożytnego chińskiego może znacznie różnić się od nowoczesnej. Tam, gdzie oprogramowanie popełniało błąd — dzieląc myśl w niewłaściwym miejscu lub źle odczytując znak — anotatorzy sprawdzali oryginalne zeskanowane strony i korygowali tekst cyfrowy, aby każde zdanie starożytne idealnie odpowiadało swojemu nowoczesnemu odpowiednikowi.
Nauczanie komputerów rozpoznawania gramatyki
Ponad zwykłą transkrypcją, sednem projektu jest oznaczanie gramatyczne. Każde słowo w tekstach starożytnych i nowoczesnych zostało oznaczone tagiem części mowy, wskazującym, czy jest to na przykład rzeczownik, czasownik czy wyraz określający czas. Ponieważ nie istnieje pojedynczy standard dla starożytnego chińskiego, zespół oparł swój system na współczesnych krajowych wytycznych, a następnie dostosował je do starszych użyć. Opracowali schemat 22 tagów, który obejmuje specjalną etykietę dla unikatowych starożytnych użyć czasowników, takich jak „spowodować życie” czy „umarć dla kraju”. Dostosowana sieć neuronowa — zbudowana na modelu językowym dla tekstów starożytnych i warstwach etykietowania sekwencji — wygenerowała wstępne tagi, które następnie sprawdził i poprawił duży zespół dobrze wyszkolonych doktorantów. Surowe testy zgodności między anotatorami wykazały bardzo wysoką spójność, co potwierdza, że końcowy oznaczony korpus jest zarówno obszerny, jak i wiarygodny.
Co ujawnia nowe spojrzenie
Dzięki oznaczonemu korpusowi autorzy przeanalizowali niektóre wzorce, które on uwidacznia. W starożytnym chińskim dominują słowa jednosznakowe, odzwierciedlając słynnie zwięzły styl pisania, podczas gdy współczesny chiński faworyzuje słowa dwuznakowe. Najczęściej występujące elementy w starożytnym języku to drobne partykuły gramatyczne, takie jak „之” i „以”, podczas gdy czasowniki i zwykłe rzeczowniki razem stanowią około połowy wszystkich słów w obu okresach. Dane pokazują także, które słowa mają tendencję do występowania razem — na przykład struktury opisujące urzędników, armie czy misje dyplomatyczne. Porównując tagi w parach starożytne–nowoczesne, zespół prześledził, jak funkcje zmieniały się w czasie: niektóre stare przyimki i przysłówki odpowiadają obecnie pełnoprawnym współczesnym czasownikom, a niektóre czasowniki utrwaliły się jako stałe tytuły lub terminy prawne. Jedno studium przypadku wyodrębniło wszystkie nazwy miejsc i zmapowało ich skupiska w różnych dynastii, ujawniając, jak centra polityczne i gospodarcze przesuwały się z północnego zachodu ku niższemu dorzeczu Jangcy i dalej. 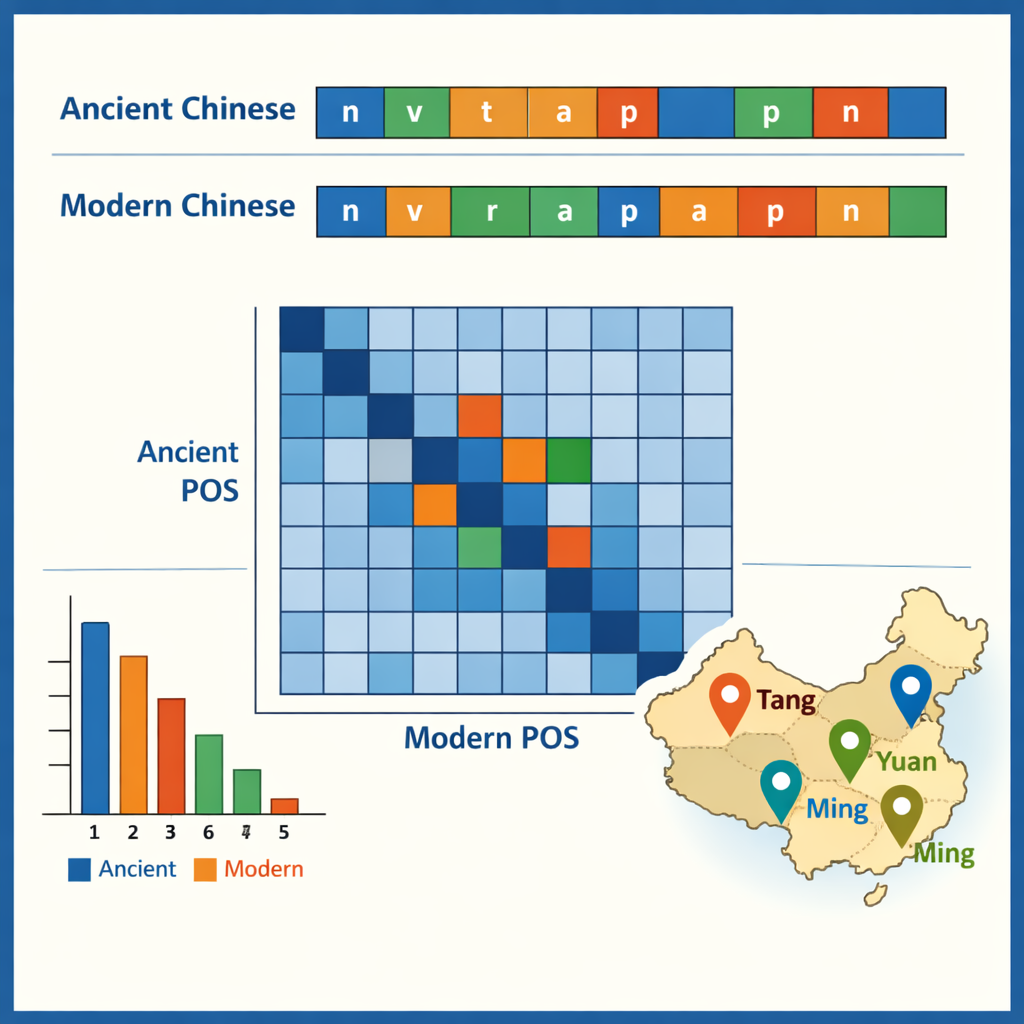
Wprowadzenie przeszłości w cyfrową przyszłość
Mówiąc prosto, projekt przekształca monumentalną ścianę klasycznej prozy w uporządkowane dane, po których mogą poruszać się zarówno ludzie, jak i maszyny. Dla historyków i językoznawców daje potężne narzędzie do śledzenia, jak zmieniały się słowa, gramatyka, a nawet granice państw na przestrzeni stuleci. Dla twórców AI oferuje materiał treningowy wysokiej jakości do budowy modeli językowych, które rzeczywiście potrafią obsługiwać klasyczny chiński, zamiast traktować go jako zbiór znaków. A dla studentów i czytelników ogólnych, parowanie zdań starożytnych i współczesnych obniża barierę dostępu do klasyki. Poprzez staranne etykietowanie i wyrównywanie Dwudziestu Czterech Historii autorzy stworzyli most od rękopisów przeszłości do inteligentnych systemów teraźniejszości i przyszłości.
Cytowanie: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Słowa kluczowe: korpus starożytnego chińskiego, oznakowanie części mowy, humanistyka cyfrowa, teksty równoległe, historyczna zmiana językowa