Clear Sky Science · nl
Thematische analyse met open-source generatieve AI en machine learning: een nieuwe methode voor inductieve ontwikkeling van kwalitatieve codeboeken
Waarom dit ertoe doet voor alledaagse vragen
Telkens wanneer mensen enquêtes invullen of interviewvragen beantwoorden, laten ze rijke verhalen achter over werk, school, gezondheid of het gemeenschapsleven. Een paar dozijn van die antwoorden lezen is eenvoudig; duizenden begrijpen is dat niet. Dit artikel beschrijft een nieuwe manier voor onderzoekers om open-source kunstmatige intelligentie te gebruiken om door enorme stapels geschreven opmerkingen te bladeren en de belangrijkste ideeën eruit te halen, terwijl mensen de interpretatie blijven leiden. Het doel is om zorgvuldige, genuanceerde kwalitatieve research mogelijk te maken op de schaal die gewoonlijk gereserveerd is voor big-data statistiek.
Een slimmer manier om duizenden opmerkingen te lezen
De auteurs richten zich op een populaire benadering in de sociale wetenschappen die thematische analyse heet, waarbij onderzoekers tekst lezen en zoeken naar terugkerende patronen of “thema’s” die hun onderzoeksvragen beantwoorden. Traditioneel betekent dit dat elk commentaar langzaam handmatig wordt gecodeerd en dat er een codeboek wordt opgebouwd—een gestructureerde lijst van thema’s en subthema’s. Dat proces werkt goed voor enkele tientallen interviews, maar wordt overweldigend wanneer er tienduizenden open antwoorden zijn. Het artikel stelt de vraag: kunnen vrij beschikbare generatieve tekstmodellen en andere open-source tools helpen bij de vroege, repetitieve delen van dit werk zonder het menselijke oordeel te vervangen?
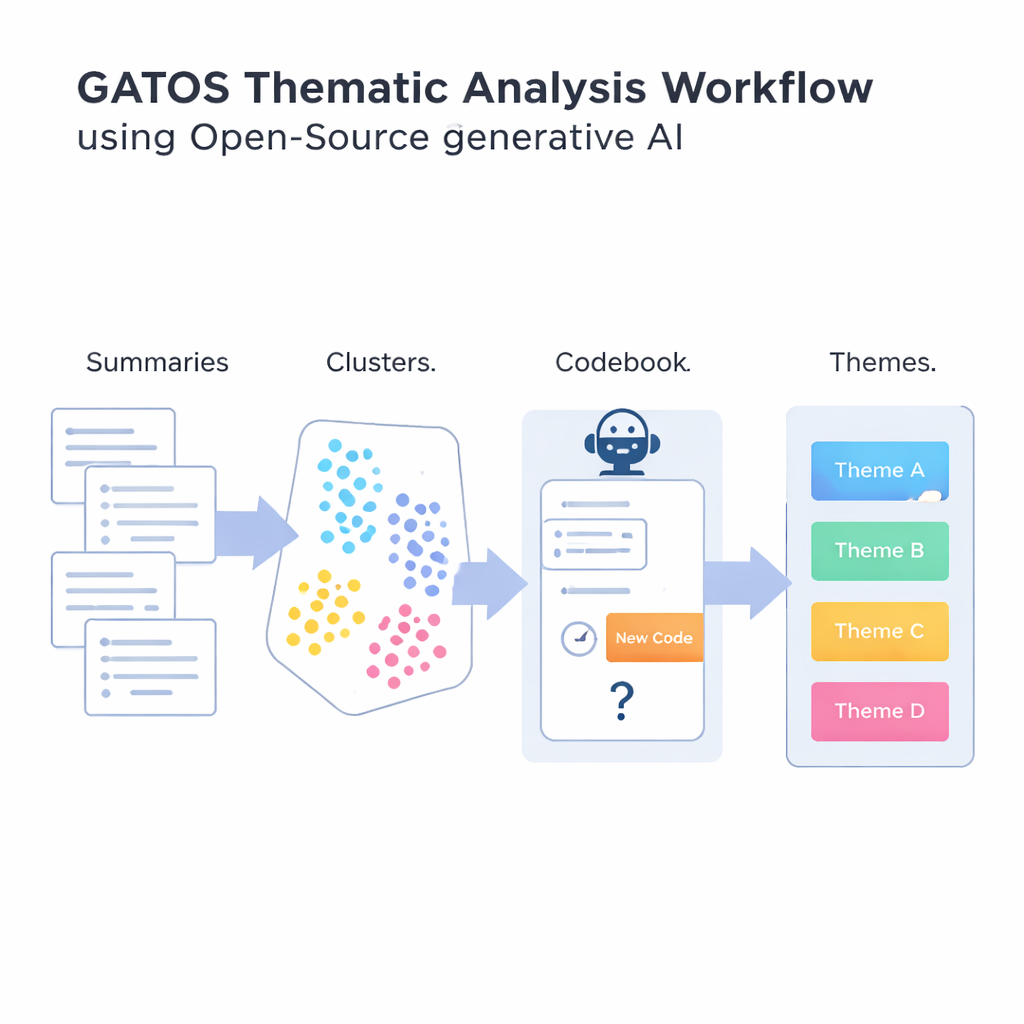
Introductie van de GATOS-workflow
Om die vraag te beantwoorden introduceren de auteurs de Generative AI-enabled Theme Organization and Structuring-workflow, ofwel GATOS. Deze workflow schakelt meerdere stappen achter elkaar. Eerst leest een open-source taalmodel individuele reacties en schrijft korte, gerichte samenvattende punten van wat elke persoon zegt. Vervolgens zet een ander hulpmiddel deze samenvattingen om in numerieke representaties zodat een computer vergelijkbare ideeën kan vergelijken en groeperen. Die samenvattingen worden geclusterd in groepen die waarschijnlijk gedeelde thema’s weerspiegelen, zoals zorgen over werk–privébalans of frustraties over onduidelijke communicatie.
AI laten voorstellen, maar geen overvloed aan nieuwe ideeën veroorzaken
De meest vernieuwende stap komt wanneer het systeem begint met het opbouwen van een concept-codeboek. Voor elke cluster van gerelateerde samenvattingen bekijkt een ander generatief model de ideeën in die cluster en de codes die al in het codeboek staan. Het overweegt vervolgens of er daadwerkelijk een nieuwe code nodig is, of dat bestaande codes volstaan. Als er een nieuwe invalshoek verschijnt—bijvoorbeeld “betrouwbare videoconferentietools” als een specifiek punt—stelt het een korte label en definitie voor die wordt toegevoegd. Zo niet, dan kiest het ervoor om bestaande codes te hergebruiken. Een laatste stap groepeert gerelateerde codes in bredere thema’s, waardoor een gestructureerde kaart ontstaat van ruwe opmerkingen naar georganiseerde inzichten. De nadruk ligt steeds op het vermijden van een overvloed aan bijna-duplicaatcodes, terwijl subtiele verschillen in ervaringen bewaard blijven.
De methode testen met realistisch fictieve data
Aangezien studies in de echte wereld zelden met een bekend “antwoordensleutel” komen, testte het team GATOS met synthetische (computergegenereerde) data waarbij de verborgen thema’s van tevoren bekend waren. Ze creëerden drie grote, levensechte datasets: collegiale feedback over teamwerk, opvattingen over ethische cultuur op de werkvloer en meningen over terugkeer naar kantoor na de COVID-19-pandemie. Voor elke dataset definieerden ze eerst acht thema’s en meerdere subthema’s, en gebruikten vervolgens een taalmodel om honderden realistische reacties te schrijven vanuit verschillende persona’s, zoals vakbondsleden, managers of studenten. Nadat GATOS op deze datasets was losgelaten, vergeleken menselijke beoordelaars de door AI gegenereerde thema’s met de oorspronkelijke, verborgen subthema’s om te zien hoe goed ze overeenkwamen.
Hoe goed werkte het, en wat zijn de afwegingen?
Over alle drie de testcases herstelde de workflow het merendeel van de oorspronkelijke subthema’s redelijk nauwkeurig: de overgrote meerderheid had minstens één sterke match, en slechts een klein aantal ontbrak een goede tegenhanger. Belangrijk is dat naarmate het systeem meer data bekeek, het minder nieuwe codes voorstelde, wat suggereert dat het leerde bestaande ideeën te hergebruiken in plaats van eindeloze variaties te verzinnen. De auteurs betogen dat dit soort open-source, lokaal uitvoerbare opzet privacyzorgen kan verminderen en het makkelijker kan maken voor verschillende onderzoeksteams om elkaars werk te repliceren. Tegelijk wijzen ze erop dat synthetische data eenvoudiger zijn dan veel reële situaties, dat de workflow nog steeds overlappende codes kan creëren, en dat menselijke onderzoekers nodig blijven om het uiteindelijke codeboek te verfijnen, interpreteren en beoordelen.
Wat dit betekent voor niet-experts
Voor lezers buiten de wetenschap is de conclusie dat open-source AI sociale wetenschappers en andere onderzoekers kan helpen naar veel meer mensen te luisteren zonder hun woorden te reduceren tot grove cijfers. In plaats van menselijke analisten te vervangen, fungeert de GATOS-workflow als een zeer snelle, zeer georganiseerde assistent die patronen en conceptlabels voorstelt, en mensen laat beslissen wat die patronen werkelijk betekenen. Als vervolgonderzoek deze resultaten op echte data bevestigt, zouden tools zoals GATOS het eenvoudiger kunnen maken om werkplekbeleid, onderwijsprogramma’s en publieke beslissingen te baseren op de volledige rijkdom van wat mensen daadwerkelijk zeggen, en niet alleen op meerkeuze-antwoorden.
Bronvermelding: Katz, A., Fleming, G.C. & Main, J.B. Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanit Soc Sci Commun 13, 209 (2026). https://doi.org/10.1057/s41599-026-06508-5
Trefwoorden: kwalitatieve data-analyse, thematische analyse, generatieve AI, open-source taalmodellen, methoden van sociaalwetenschappelijk onderzoek