Clear Sky Science · nl
De kloof tussen computationeel en experimenteel onderzoek overbruggen: gebruik van grote taalmodellen om Alzheimer‑therapieën te prioriteren op basis van vergelijking van leermodellen
Waarom dit belangrijk is voor families en patiënten
De ziekte van Alzheimer berooft mensen van geheugen, zelfstandigheid en levenskwaliteit, maar echt effectieve behandelingen zijn nog schaars. Deze studie verkent een snellere manier om bestaande medicijnen voor nieuwe toepassingen te vinden, door krachtige rekenmodellen te combineren met een groot taalmodel—hetzelfde type AI dat tegenwoordig in alledaagse chatbots wordt gebruikt—om enorme hoeveelheden medische gegevens en publicaties te doorzoeken. Het doel is een lange lijst mogelijke geneesmiddelen terug te brengen tot een klein, realistisch aantal dat wetenschappers en artsen daadwerkelijk bij patiënten kunnen testen.
Oude medicijnen een nieuwe rol geven
Het ontwikkelen van een gloednieuw geneesmiddel kost vaak meer dan tien jaar en gaat gepaard met miljardenkosten, zonder garanties op succes. Een alternatief is “drug repurposing” of hergebruik van geneesmiddelen: het zoeken naar nieuwe toepassingen voor medicijnen die al voor andere aandoeningen zijn goedgekeurd, zoals de ziekte van Parkinson of depressie. Omdat de veiligheidsprofielen van deze middelen al bekend zijn, kunnen ze vaak sneller in klinische studies voor Alzheimer worden gebracht. Moderne computermethoden die biologische databases en medische literatuur scannen produceren echter nu enorme lijsten met kandidaten—veel meer dan onderzoekers handmatig realistisch kunnen evalueren—waardoor een nieuw knelpunt ontstaat in het proces.
Meerdere slimme modellen samenbrengen
Het onderzoeksteam pakte dit probleem aan door een Alzheimer Drug Repurposing‑kader te bouwen dat begint met drie verschillende geavanceerde computermodellen. Elk model onderzoekt een grote biomedische "kaart" genaamd een kennisgrafiek, die ziekten, geneesmiddelen, genen en andere medische concepten met elkaar verbindt, en doet voorstellen welke geneesmiddelen mogelijk bij Alzheimer zouden kunnen helpen. Omdat elk model patronen op een andere manier ziet, overlappen hun lijsten niet volledig. De auteurs combineerden de top 30 suggesties van elk model tot één verzameling van 90 kandidaatmiddelen en gebruikten vervolgens een groot taalmodel (LLM) als een geautomatiseerde maar voorzichtige beoordelaar, dat gepubliceerde studies voor elk middel leest en inschat of het bewijs nuttig, neutraal of schadelijk lijkt voor Alzheimer.
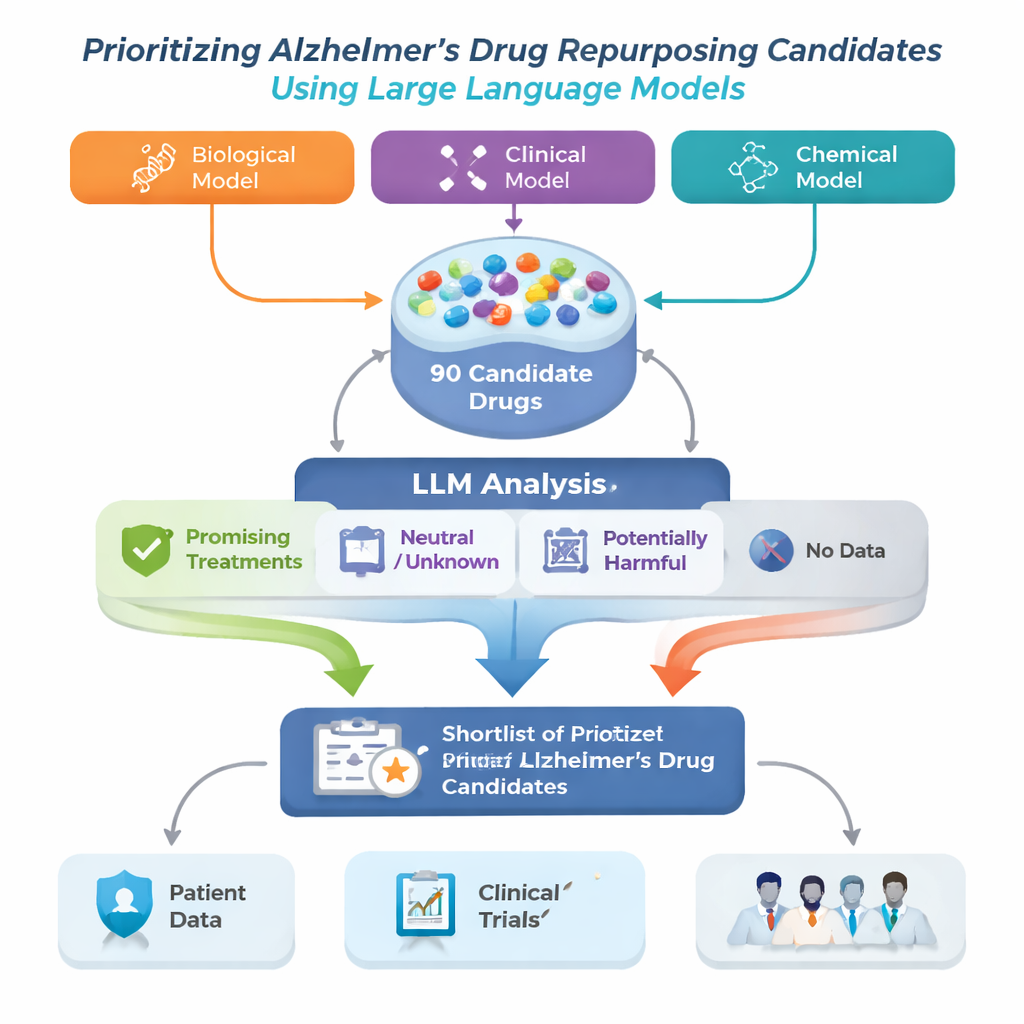
Hoe de AI de medische literatuur leest
Voor elk kandidaatmiddel haalde het systeem tot 200 wetenschappelijke samenvattingen (abstracts) uit PubMed plus gedetailleerde middelbeschrijvingen uit een farmaceutische database. Het LLM kreeg de instructie zijn oordeel uitsluitend te baseren op de tekst die het te zien kreeg en elk abstract te labelen als positief, neutraal of negatief voor Alzheimer‑behandeling. Deze labels werden vervolgens omgezet in eenvoudige scores: het aandeel abstracts dat positief, neutraal of negatief was. Met twee sets regels—een strengere die duidelijke positieve aanwijzingen vereiste en een mildere die elk vermoeden van voordeel markeerde—sorteerde het kader middelen in vier groepen: veelbelovende behandelingen, mogelijk schadelijk, onduidelijk of neutraal, en middelen zonder enige Alzheimer‑gerelateerde publicaties. Die laatste groep, hoewel weinig bestudeerd, kan juist bijzonder nieuwe kansen bevatten.
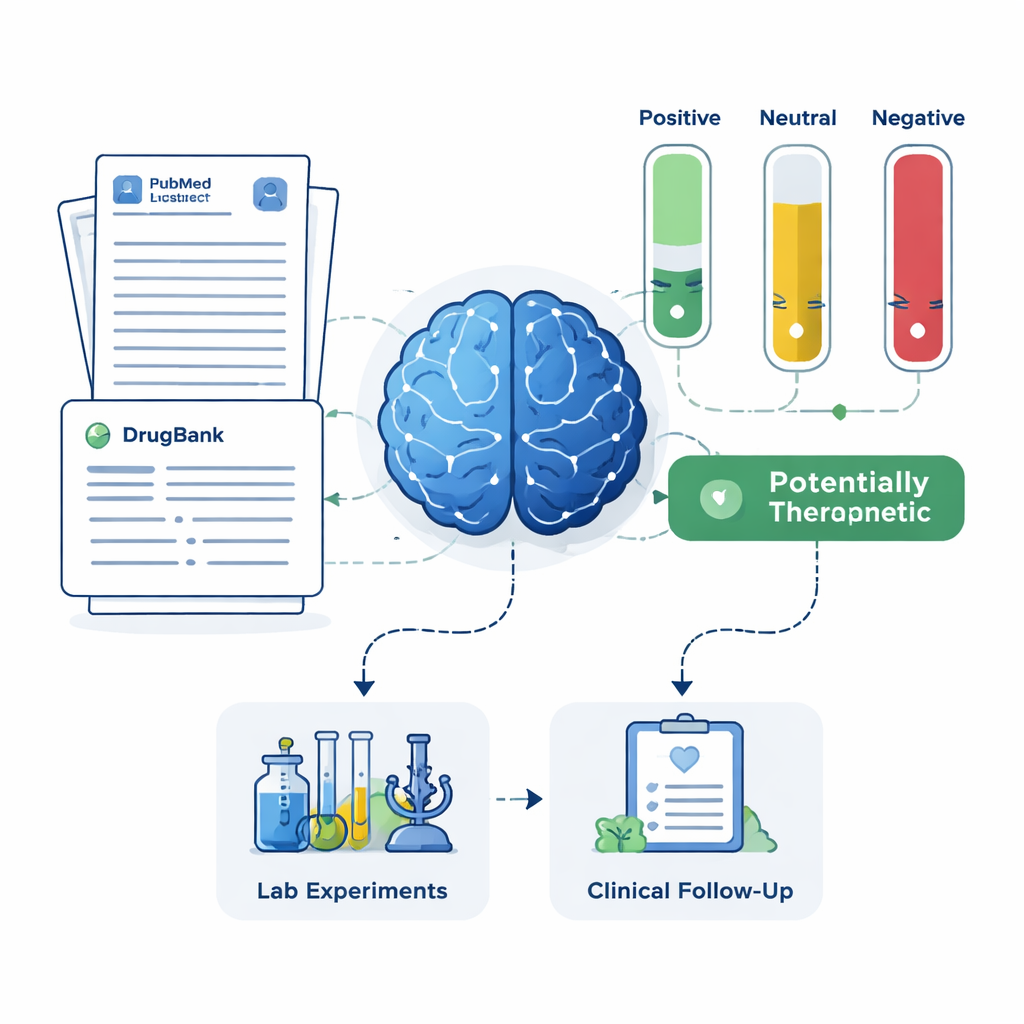
Controle met echte patiënten en klinische studies
Om te beoordelen of de korte lijst van de AI zinnig was in de praktijk, vergeleek het team de resultaten met twee onafhankelijke bronnen: een groot Alzheimer‑patiëntenregister en gegevens van geregistreerde klinische studies. Het kader vond met succes memantine terug, een bestaand Alzheimer‑medicijn met sterke beschermende signalen in patiëntgegevens en een uitgebreide proefgeschiedenis, als een prioriteitskandidaat. Het trok ook aandacht voor middelen zoals magnesium, minocycline, pimavanserin, testosteron en doxycycline, die verschillende niveaus van ondersteunend onderzoek hebben maar door deskundige clinici als veelbelovend werden beschouwd. Tegelijk identificeerde het systeem middelen waarvan de literatuur mogelijke schade of gebrek aan voordeel suggereerde, en adviseerde deze te deprioriteren of nader te onderzoeken op bijwerkingen in plaats van voor behandeling te gebruiken.
Van computervoorspellingen naar praktische vervolgstappen
In gewone bewoordingen werkt dit kader als een ultrasnelle, zorgvuldige onderzoeksassistent die duizenden artikelen leest, patronen in grote medische databases kruist en menselijke experts een veel kortere, beter georganiseerde lijst van Alzheimer‑middelencandidaten aanreikt om zich op te concentreren. De studie laat zien dat door verschillende typen AI te combineren—grafgebaseerde modellen om ideeën te genereren en een taalmodel om het bewijs te beoordelen—onderzoekers sneller goed onderbouwde medicijnen en intrigerende nieuwe opties voor tests kunnen vinden. Hoewel deze aanpak Alzheimer niet op zichzelf geneest, biedt zij een krachtig nieuw middel om computergegenereerde ideeën te verbinden met het zware werk van laboratoriumexperimenten en klinische proeven, wat mogelijk het pad naar effectievere behandelingen versnelt.
Bronvermelding: Li, M., Niu, S., Xu, Y. et al. Bridging the computational-experimental gap: leveraging large language model to prioritize Alzheimer’s therapeutics based on comparison of learning models. npj Health Syst. 3, 20 (2026). https://doi.org/10.1038/s44401-026-00074-3
Trefwoorden: Ziekte van Alzheimer, hergebruik van geneesmiddelen, kunstmatige intelligentie, grote taalmodellen, kennisgrafen