Clear Sky Science · nl
Het detecteren van stigmatiserende taal in klinische aantekeningen met grote taalmodellen voor verslavingszorg
Waarom de woorden in uw medisch dossier ertoe doen
Naarmate meer patiënten online toegang krijgen tot hun medische dossiers, is de taal die zorgverleners gebruiken niet langer verborgen in ziekenhuiscomputers — ze is zichtbaar voor de mensen die erin worden beschreven. Voor patiënten met een verslaving kan één uitdrukking zoals “drugverslaafde” stilletjes schaamte versterken, vertrouwen beschadigen en zelfs de zorg beïnvloeden die ze ontvangen. Deze studie stelt een actuele vraag: kan moderne kunstmatige intelligentie ziekenhuizen helpen stigmatiserende taal in klinische aantekeningen te detecteren en te verminderen voordat het patiënten schaadt?

Schadelijke labels verborgen in alledaagse aantekeningen
Stigma in de gezondheidszorg verschijnt niet alleen in oogcontact of toon van stem; het zit ook ingebakken in het geschreven dossier. Elektronische patiëntendossiers bevatten miljoenen aantekeningen die patiënten volgen door verschillende klinieken en ziekenhuizen. Termen zoals “alcoholmisbruik” of “drugs-zoekend gedrag” kunnen beïnvloeden hoe toekomstige zorgverleners een persoon zien, lang nadat een bezoek aan de spoedeisende hulp of een ziekenhuisopname heeft plaatsgevonden. De onderzoekers concentreerden zich op intensivecare-aantekeningen over patiënten met middelengebruikproblemen, waar de inzet hoog is en de documentatie uitgebreid. Ze vertrokken van nationale richtlijnen die respectvol, persoon-eerst taalgebruik aanmoedigen — zoals “persoon met een middelengebruikstoornis” in plaats van “verslaafde” — en gebruikten deze ideeën om een grote dataset te maken van aantekeningen die waren gelabeld als stigmatiserend of niet.
Een AI leren tussen de regels te lezen
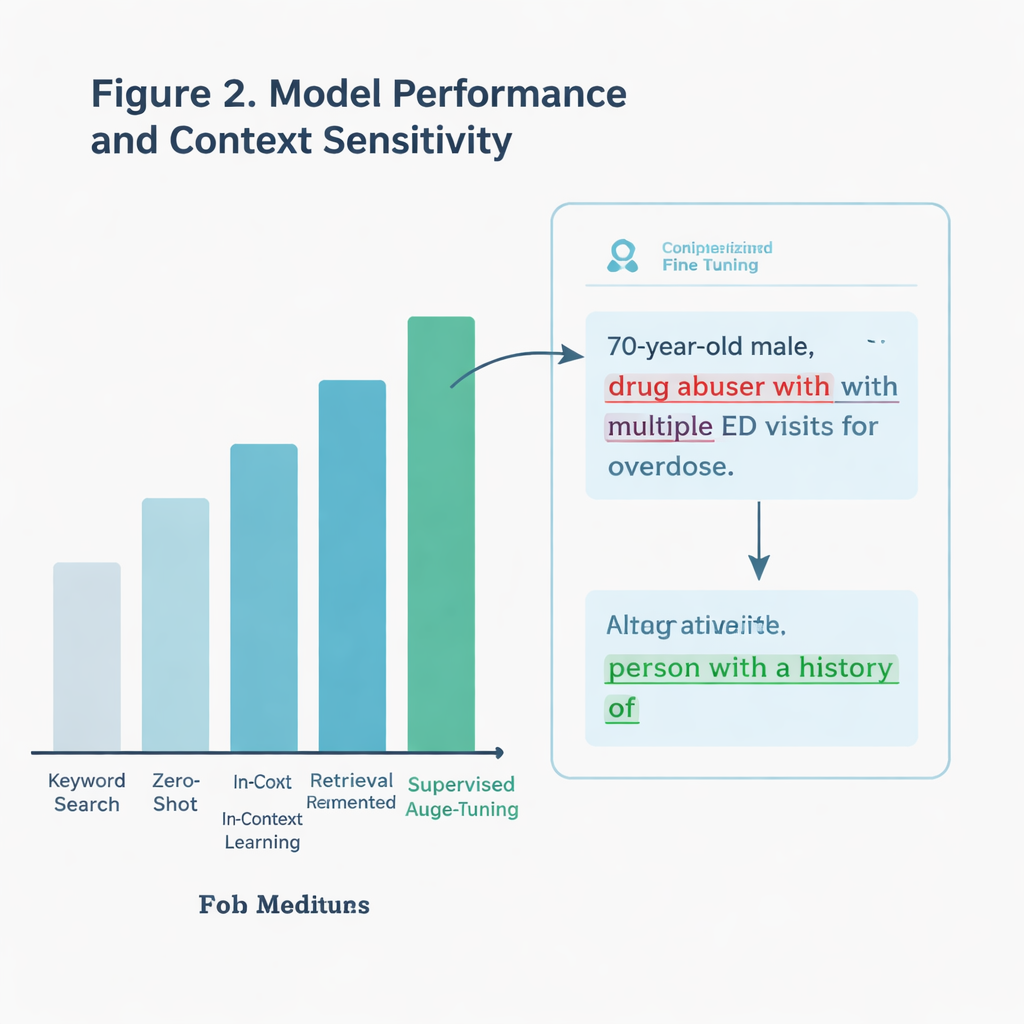
In plaats van alleen naar foute woorden te zoeken, wilden de onderzoekers een AI-systeem dat context kan begrijpen. Een aantekening kan bijvoorbeeld een citaat bevatten van een patiënt die zichzelf als “dronken” beschrijft, wat iets anders is dan wanneer een zorgverlener dat labelt. De auteurs vergeleken meerdere benaderingen, allemaal gebouwd op een groot taalmodel (een type AI dat tekst verwerkt en genereert). Een eenvoudige methode keek alleen naar specifieke trefwoorden uit de richtlijnen. Meer geavanceerde methoden vroegen de AI elke aantekening direct te beoordelen, hetzij zonder voorbeelden, met aanvullende richtlijnen voor communicatie, of na speciale training — oftewel fine-tuning — op duizenden gelabelde IC-aantekeningen.
Wat in de praktijk het beste werkte
Het fijn-afgestelde model bleek duidelijk het beste. Op een niet-gebruikte testset van meer dan 11.000 aantekeningen identificeerde het ongeveer 97 procent van de gevallen met stigmatiserende taal correct, veel beter dan een eenvoudige trefwoordzoekopdracht. Het presteerde ook beter op een bijzonder lastige subset van aantekeningen die potentieel beladen termen bevatten maar niet altijd op een schadelijke manier werden gebruikt. Het model kon onderscheid maken tussen echt veroordelende zinnen en neutraal of geciteerd gebruik, waar een grovere zoekmethode faalde. Toen het team het systeem testte op aantekeningen van een ander zorgsysteem — bijna 300.000 IC-aantekeningen geschreven in een andere staat — bleef het beter presteren dan de trefwoordaanpak, hoewel stigmatiserende taal zeldzaam was in dat real-world monster.
Nieuwe problematische zinnen ontdekken die zorgverleners misten
De onderzoekers gingen een stap verder en vroegen de AI uit te leggen waarom het bepaalde aantekeningen had gemarkeerd. Een verslavingsspecialist beoordeelde vervolgens deze verklaringen. In tientallen gevallen wezen de modellen echt stigmatiserende taal aan die menselijke annotatoren aanvankelijk over het hoofd hadden gezien, inclusief zinnen die niet in bestaande richtlijnen stonden. Voorbeelden waren beschrijvingen zoals “drugs-zoekend gedrag” of terloopse vermeldingen van “alcoholische cirrose” die subtiel de persoon de schuld geven in plaats van de ziekte. Dit suggereert dat goed ontworpen AI-hulpmiddelen niet alleen huidige best practices kunnen afdwingen, maar ook ons begrip kunnen uitbreiden van hoe schadelijke taal eruitziet naarmate klinische schrijfwijzen evolueren.
Van onderzoekstool naar hulp naast het bed
De studie woog ook praktische aspecten af. Trefwoordzoeken is razendsnel maar oppervlakkig. Het meest nauwkeurige AI-model vereiste enkele uren training op krachtige grafische processors, maar eenmaal getraind kon het aantekeningen in enkele seconden screenen — traag voor een zoekmachine, maar acceptabel voor een achtergrondassistent in een ziekenhuisomgeving. Een andere, minder aangepaste benadering die alleen op zorgvuldig opgestelde prompts vertrouwde, presteerde redelijk goed zonder extra training, wat duidt op lichtere opties voor klinieken met minder technische middelen. Samen wijzen deze bevindingen op systemen die in realtime risicovolle bewoording kunnen markeren en respectvollere alternatieven kunnen voorstellen terwijl zorgverleners typen.
Een stap naar respectvollere zorg
Voor de niet-specialist is de belangrijkste conclusie eenvoudig: de woorden in uw dossier zijn niet alleen technisch jargon; ze helpen bepalen hoe u wordt behandeld. Dit werk toont aan dat grote taalmodellen betrouwbaar veel vormen van stigmatiserende taal met betrekking tot verslaving in intensivecare-aantekeningen kunnen opsporen, zelfs wanneer het probleem subtiel is. Hoewel geen enkel systeem perfect is, kunnen dergelijke hulpmiddelen fungeren als altijd-aan redacteuren die zorgverleners aansporen tot taal die mensen erkent als meer dan hun diagnose. Op de lange termijn kan die verschuiving — van schuld naar respect — net zo belangrijk zijn voor herstel als welk geneesmiddel of apparaat dan ook.
Bronvermelding: Sethi, R., Caskey, J., Gao, Y. et al. Detecting stigmatizing language in clinical notes with large language models for addiction care. npj Health Syst. 3, 15 (2026). https://doi.org/10.1038/s44401-026-00069-0
Trefwoorden: stigma bij verslaving, klinische aantekeningen, grote taalmodellen, elektronische patiëntendossiers, persoon-eerst taalgebruik