Clear Sky Science · nl
3D Magische Spiegel: kledingreconstructie uit één enkele afbeelding vanuit een causaal perspectief
Kleren passen zonder pashokje
Stel je voor dat je met je telefoon één foto van je hele lichaam schiet en onmiddellijk jezelf in 3D ziet, kunt laten draaien, van kijkhoek kunt veranderen of zelfs outfits met een vriend kunt ruilen. Dit artikel pakt het kerntechnische probleem achter die “3D Magische Spiegel” aan: van één gewone 2D-foto van een geklede persoon een gedetailleerd 3D-model van de kleding maken, zonder te vertrouwen op dure 3D-scans of gecontroleerde studiobeelden.
Waarom het omzetten van 2D-foto’s naar 3D zo lastig is
Het omzetten van een plat beeld in een 3D-object is een klassiek raadsel. Bestaande systemen beginnen vaak met een vast digitaal lichaamssjabloon en buigen dat zodat het bij de foto past. Dat werkt redelijk goed voor stijve lichaamsdelen zoals armen en benen, maar faalt bij vloeiende jurken, gedrapeerde jassen, haar of handtassen, die geen eenvoudige standaardvorm volgen. Een andere hindernis is data: op het web staan miljoenen modestfoto’s, maar bijna geen grote verzamelingen met nauwkeurig gemeten 3D-kledingstukken om op te trainen. Ten slotte verbergt één enkele foto belangrijke informatie. Een korte jas dicht bij de camera kan identiek lijken aan een grotere jas verder weg, en lichtval of stofpatronen kunnen een leeralgoritme ook verwarren. Deze dubbelzinnigheden maken het moeilijk voor een neurale netwerk om de juiste 3D-structuur te ‘‘raden’’.
AI leren oorzaak van gevolg te scheiden
In plaats van het probleem als een black-box mapping van pixels naar 3D te behandelen, lenen de auteurs ideeën uit causaal redeneren—de wiskunde van oorzaak en gevolg. Zij zien de uiteindelijke afbeelding als het resultaat van vier verborgen oorzaken: de camerapositie, de vorm van de kleding, de textuur (kleuren en patronen) en de belichting. Een speciaal ‘‘structureel causaal schema’’ geeft aan hoe deze factoren samen de waargenomen foto voortbrengen. Geleid door dit schema gebruikt het systeem vier afzonderlijke neurale encoders, elk verantwoordelijk voor één factor. Samen met een fysica-geïnspireerde 3D-renderer vormen ze een lus: afbeelding en voorgrondmasker gaan erin, er komt een gekleurd 3D-mesh uit, en dat wordt weer geprojecteerd naar een afbeelding die met het origineel vergeleken kan worden.
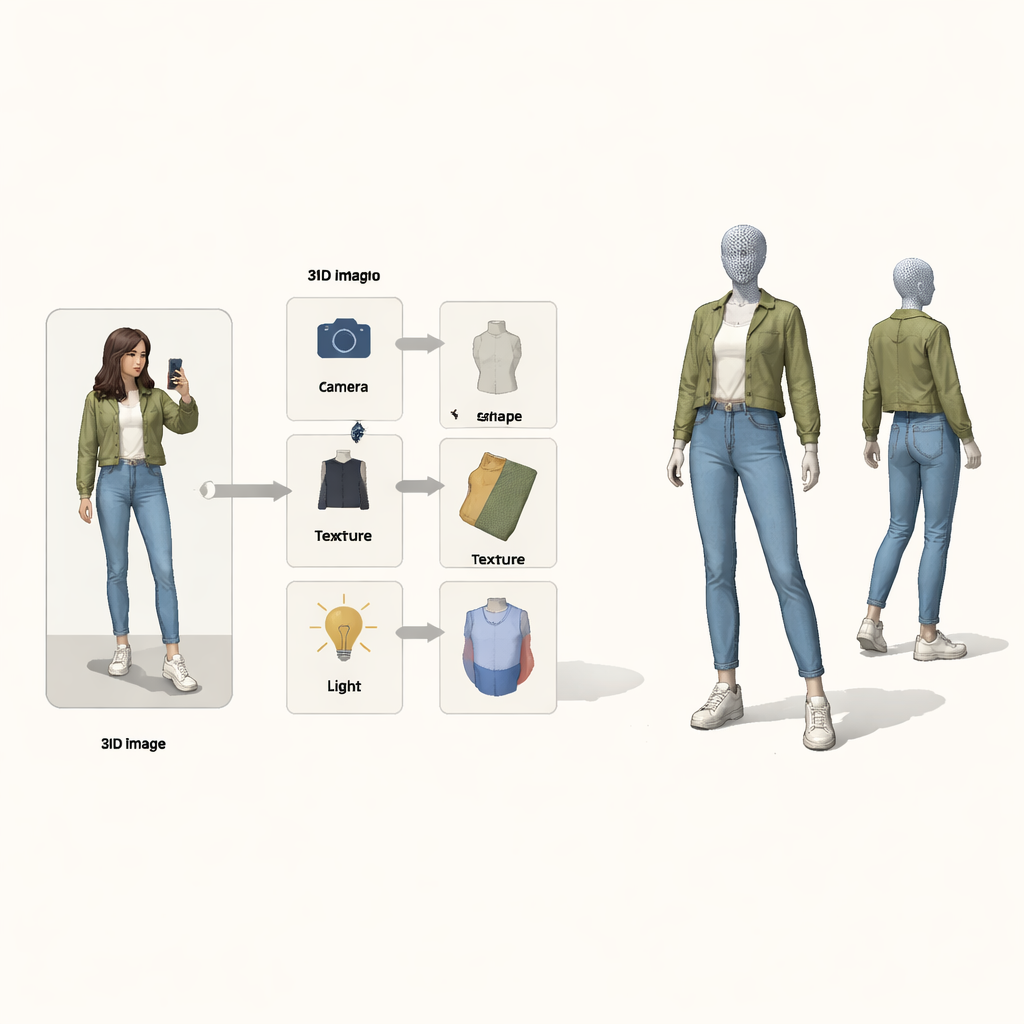
Een leerlus die één ding tegelijk repareert
Zelfs met gescheiden encoders kan training misgaan. Als de reconstructie onvolledig is, is onduidelijk welke encoder de fout veroorzaakt, en gewone leerregels passen meestal alle componenten tegelijk aan. De auteurs benaderen dit als een klassiek ‘‘collider’’-probleem in causaliteit, waarbij verschillende oorzaken elkaar onterecht kunnen compenseren. Hun oplossing is om twee expectation–maximization-lussen in de training te weven. In de eerste lus worden drie encoders tijdelijk bevroren terwijl alleen de vierde wordt bijgewerkt, zodat fouten duidelijk worden toegeschreven en die component een schonere rol leert. In de tweede lus wordt een gedeelde ‘‘prototype’’-3D-vorm—beginnende als een eenvoudige bol—langzaam bijgewerkt om de gemiddelde menselijke of vogelvorm in de data te worden. Individuele voorbeelden leren alleen kleine afwijkingen van dit prototype, terwijl de cameramodule de volledige verantwoordelijkheid neemt voor hoe groot of nabij het object lijkt, en daarmee direct de verwarring tussen grootte en afstand aanpakt.
Van modestfoto’s naar vogels, en verder
Om hun aanpak te testen trainen de onderzoekers op twee grote modestdatasets met gewone straatfoto’s en op een standaardcollectie van vogelafbeeldingen. Belangrijk is dat ze alleen 2D-voormaskers gebruiken, geen 3D-ground-truth-meshes. Voor menselijke kleding presteert hun systeem beter dan populaire lichaamssjabloonmethoden bij het matchen van de werkelijke omtrek van kleding en gaat het niet-rigide elementen zoals haar en handtassen trouwer om. Bij vogels bereikt het de kwaliteit van toonaangevende single-image 3D-reconstructiemethoden of overtreft die, terwijl het realistischere nieuwe kijkhoeken produceert. De 3D-modellen zijn flexibel genoeg voor speelse toepassingen, zoals het uitwisselen van texturen tussen personen of het genereren van synthetische trainingsdata om persoonsherkenningssystemen te verbeteren die in surveillance-onderzoek worden gebruikt.
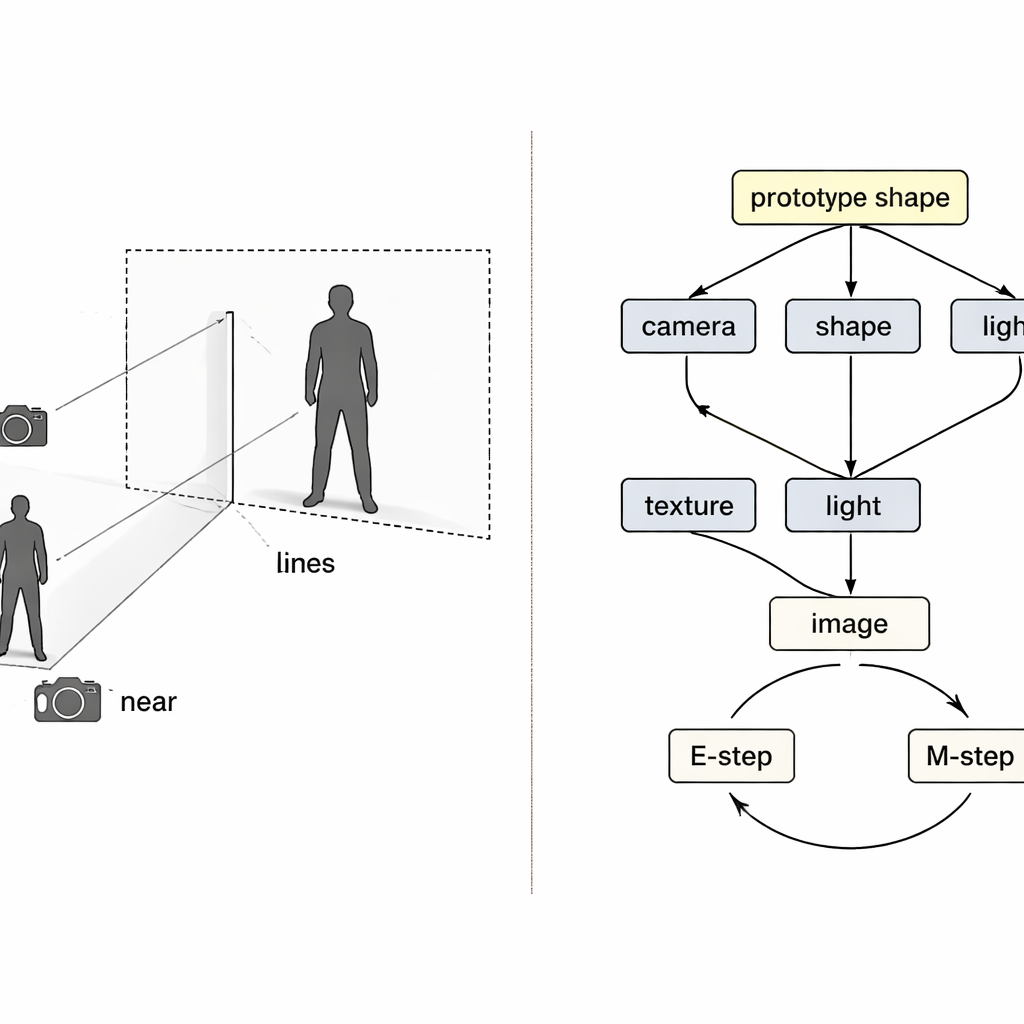
Wat dit betekent voor alledaagse digitale werelden
Voor niet-specialisten is de kernboodschap dat overtuigende 3D-avatar- en virtueel-passen-tools niet langer kostbare 3D-scanners of rigide sjablonen vereisen. Door expliciet oorzaak en gevolg te modelleren—camera, vorm, textuur en licht te scheiden en te verankeren aan een gedeeld prototype—laten de auteurs zien hoe een systeem een enkele foto als een 3D-scène kan ‘‘verklaren’’. Hoewel de methode nog worstelt met onbekende aanzichten, zoals de rug van een persoon die alleen van voren is gefotografeerd, vormt het een belangrijke stap richting praktische 3D Magische Spiegels die werken op de rommelige, in-the-wild beelden die we echt maken.
Bronvermelding: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Trefwoorden: virtueel passen, 3D-reconstructie, causaal leren, computer vision, fashion AI